Download

1 / 29
290 likes | 477 Views
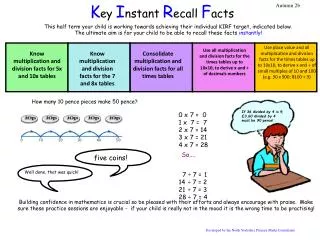
Grammatikkontroll för skribenter med svenska som andraspråk. Johnny Bigert, Viggo Kann, Ola Knutsson och Jonas Sjöbergh KTH Nada Stockholm, Sverige. Grammatikkontroll i CALL. Behov: Lärarna vill ha bort låg-nivå fel Eleverna vill inte upprepa fel

E N D
Grammatikkontroll för skribenter med svenska som andraspråk Johnny Bigert, Viggo Kann, Ola Knutsson och Jonas Sjöbergh KTH Nada Stockholm, Sverige
Grammatikkontroll i CALL Behov: Lärarna vill ha bort låg-nivå fel Eleverna vill inte upprepa fel Skapa “feedback” på elevers fria textproduktion Diskussion: Är det bra eller dåligt att fokusera på fel? Missade fel och falska alarm?
Räcker inte reglerna till? • Varför inte fullparsning (deep parsing)? • Kan man hitta alla fel i en text? Grammatiskt/acceptabelt • Hur skall man analysera en text som är full av fel?
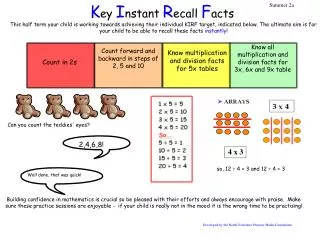
Tre metoder för grammatikkontroll • Granska – handskrivna regler • ProbGranska – statistik • MLGranska – regler skapas automatiskt
Granskas uppbyggnad Tokeniseraren Taggaren Lexikon (SUC & SAOL) Statistik (SUC) Regelmatcharen Regler (300 regler) Ordböjningsfunktion Grafiskt gränssnitt Interaktion med användaren
Kvinnan nn.utr.sin.def.nom hade vb.prt.akt.auxköpt vb.sup.akten dt.utr.sin.indny jj.pos.utr.sin.ind.nomhus nn.neu.plu.ind.nom bil nn.utr.sin.ind.nom Kvinnan nn.utr.sin.def.nom hade vb.prt.akt.auxköpt vb.sup.akten dt.utr.sin.indny jj.pos.utr.sin.ind.nomhus nn.neu.plu.ind.nom bil nn.utr.sin.ind.nom
ex2@regler { X(wordcl=nn & spec=ind & case=nom), % hus Y(wordcl=nn) % bil --> mark(X Y) corr(X.join(Y.text)) action(scrutinizing) }
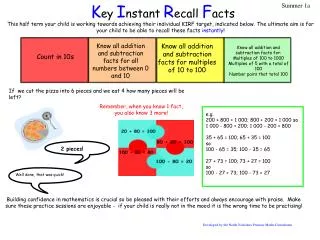
ProbGranska: Detektion av kontextkänsliga stavfel Vi vill hitta oförutsägbara fel, t.ex. förfrö Vi använder en hybridmetod: Statistik över taggtrigram (DT JJ NN 23000) från SUC (1 miljon ordklasstaggade ord) Lingvistisk kunskap för frastransformationer/reduktioner
Jag pn.utr.sin.def.subhar vb.prs.akt.auxen dt.utr.sin.indliten jj.pos.utr.sin.ind.nomhund nn.utr.sin.ind.nom sa vb.prt.aktmannen nn.utr.sin.def.nom. mad
En första ansats Algoritm: För varje position i i indataströmmen om frekvensen av (ti-1 ti ti+1) är låg i referenskorpus rapportera fel till användaren rapportera inget fel
Glesa data (sparse data) Glesa data för taggtrigramsstatistik – oändligt stort korpus saknas. Fras- och satsgränser kan skapa nästa vilka trigram som helst.
Exempel på glesa data ”Det är varje chefs uppgift att …” Det är varje taggas som pn.neu.sin.def.sub/obj, vb.prs.akt, dt.utr/neu.sin.ind och har frekvensen noll. dt.utr/neu.sin.ind är ovanlig, 709 förekomster i SUC.
Ersätt en tagg med en annan liknande tagg Vi försöker ersätta: Det är varje chefs uppgift.. med Det är en chefs uppgift.. (pn.neu.sin.def.sub/obj, vb.prs.akt, dt.utr.sin.ind) Vi får upp taggfrekvensen till 231
Olika taggbyten är olika bra Vi måste ha viktade trigram. Vi använder statistik ur korpus för att få fram relevanta vikter.
Metoden är bra på att hitta fel … men ger fortfarande ifrån sig många falska alarm. Förbättra metoden med lingvistisk kunskap
Sats- och frasigekänning med ytparsning Använd satsen som analysenhet för feldetektionen. Transformera ovanliga fraser till frekventa Ersätt frasen med dess huvud Ta bort en del fraser (AdvP, PP).
NP NP Frastransformationer Exempel: Alla hundar som är bruna är lyckliga Hundarna är lyckliga
Slutsatser Metoden är bra på att identifiera kontextkänsliga stavfel. Med lingvistisk kunskap kan metoden få högre precision Metoden bör kunna skalas upp till n-gram över fras och därmed bör mer strukturella fel kunna upptäckas (framtida forskning)
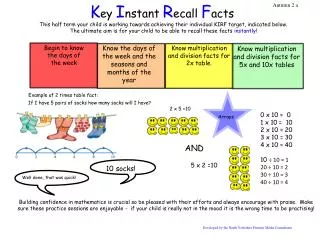
MLGranska: Maskininlärning för feldetektion • Se problemet som ett taggningsproblem • Märk upp felen t.ex. med taggen ERROR och resten med OK • Träna en maskininlärningsalgoritm (t.ex. TBL) på det annoterade materialet + material med korrekt text. • Utvärdera på ett okänt men annoterat material.
MLGranska Vi behöver många fel Idé: Skapa fel automatiskt Träna en maskininlärningsalgoritm på detta material. Automatisk annotering. Förlåtande felgenerering. Skapa en “feltaggare” för varje feltyp
Skapa träningsdata 1. Ta en referenskorpus 2. Ta en kopia av denna referenskorpus. 3. Skapa särskrivningsfel i denna – märk upp dessa ERROR 4. Övriga ord märks upp med OK i de två korpusarna.
Familjen NN OKbodde VB OKi PP OKett DT OKhus NN OKoch KN OKkörde VB OK en DT OK miljövänlig JJ OKbil NN OK. MAD OK
Kvinnan NN OKhade VB OKköpt VB OKen DT OKny JJ OKhus NN ERRORbil NN ERROR. MAD OK
Hur går träningen till? Regelmallar, ord/tagg före/efter Ta en kopia av träningskorpusen för att få en träningsmängd och ett “facit”. Applicera en initialgissning på träningsmängden = för varje ord – vilken tagg är vanligast? Skapa regler utifrån regelmallarna Välj ut de regler som gör träningsmängden mer lik “facit”. Välj bästa regeln, applicera denna, kolla nästa bästa regel.
Kvinnan NN OK hade VB OK köpt VB OK en DT OK ny JJ OK hus NN OK bil NN OK . MAD OK
NN OK + NN OK NN ERROR + NN ERROR Kvinnan NN OK hade VB OK köpt VB OK en DT OK ny JJ OK hus NN ERROR bil NN ERROR . MAD OK
MLGranska möter en ny text Ordklasstagga orden Gör en initialgissning Tillämpa de genererade reglerna Förhoppningsvis har felen taggats med taggen ERROR Alla särskrivningar kontrolleras mot stavningskontrollen Stava
MLGranska Fördelar: • Begränsad manuell insats • En taggare per feltyp kan ge bra diagnos och även ersättningsförslag (åtminstone för särskrivningar). Nackdelar: • Varje feltaggares enskilda falsklarm kan resultera i många falsklarm om man sätter ihop dem i ett verktyg.
Slutsatser Metoderna upptäcker olika fel – överens ibland Fördelar/nackdelar med varje metod? Vilka fel kommer vi fortfarande inte åt? Vi har jämfört metoderna på “felsamlingar” Just nu gör vi jämförelser på balanserat textmaterial