Download

1 / 16
170 likes | 428 Views
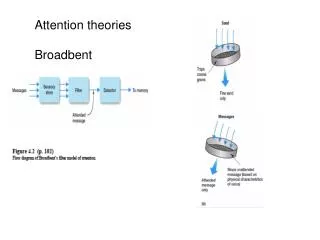
An attempt to integrate theories of object-based attention and space-based attention. The spatial element comes from CODE (COntour DEtection theory of grouping by proximity). (Offelen & Vos, 1982, 1983) The object-based input comes from Bundesen's TVA (Theory of Visual Attention).

E N D
An attempt to integrate theories of object-based attention and space-based attention.
The spatial element comes from CODE (COntour DEtection theory of grouping by proximity). (Offelen & Vos, 1982, 1983) The object-based input comes from Bundesen's TVA (Theory of Visual Attention). (Bundesen, 1990)
Five questions posed by Logan: • How is space represented? • 2. What is an object? • • Similarity (Kahneman & Henik,1977) • • Common fate (Driver & Baylis, 1989) • • Proximity (Prinzmetal, 1981) • 3. What determines the shape of the spotlight? • 4.How does selection occur within the focus of attention? • 5.How does selection occur between objects?
How CODE provides the input for CTVA: Objects are represented on an analogue map separated by a Euclidean metric. Features or items are not represented on the map as points, but as distributions across space. A threshold is applied to these distributions to turn the perceptual items into "quasi-discrete/quasi-analogue" (p606) representations of objects.
How TVA analyses CODE input: TVA assumes two levels of representation- (a) a perceptual level that consists of features of display items; (b) a conceptual level which consists of categorisations of both display items and features. They are linked by the following parameter- η(x,i) This parameter is used to select (a) a catagorisation for that object and (b) a within-group perceptual object.
(A) Object catagorisation - Two shapes are briefly presented on a background of dots.
Summary of CTVA: • Stimuli are represented as distributions in analogue space • The CODE surface increases with overlapping distributions • A threshold set by higher cognitive processes determines the size of the feature catches and whether stimuli will be grouped together • The feature catches attract attention and provide the input for TVA - h(x,i) • TVA adds Perceptual Bias and Attentional Weight • A race for categorisation within a feature catch determins which of two or more items within a feature catch is processed
Testing the model against previous experiments Logan compared the results of his model against the results of 7 established experimental results in object-based attention. Through manipulation of the free parameters Logan was able to model the data from previous experiments such as Eriksen and Eriksen’s flanker paradigm, and Prinzmetal’s (1981) illusory conjunction experiment.
95% 94% Logan’s data correlated with Prinzmetal’s data at r = 0.901! 25% 18% 10% 7%
The five questions posed by Logan: • How is space represented? It’s neither object-based or space-based but is a mixture of the two. We start with objects which are out there. These objects are then represented in terms of distributions in space on a saliency map. The CODE surface sums them up and a threshold is imposed from top down which creates the input in terms of perceptual groups. 2. What is an object? An object is defined as the above threshold region of a distribution: an appature which is opened up in the CODE suface by slicing off the the peaks of the map with a threshold.
3. What determines the shape of the spotlight? Same as Q2. In CTVA an object and a spotlight are basically the same thing. 4. How does selection occur within the focus of attention? A race occurs between the different items in a joint feature catch. The winner is attended to. 5. How does selection between objects occur? Despite suggesting how important this problem is CTVA makes no attempts to solve it.
Yes No • It says nothing about spatial grouping by other gestalt factors such as similarity and common fate. How would these factors be represented on the saliency map? • 2. In real life objects are not just points. • 3. Is too much left to the homunculus? • 4. Is CTVA too flexible? • It is a formal theory. • 2. It has accounted for data from seven major phenomena found in the attention literature. • 3. It integrates space and object representations of attention Is CTVA a good theory?
Logan has created a theory which can explain spatial effects and can explain object based effects without falling into a paradox. However... though the flexible parameters allow it to be applied to many studies post hoc it's questionable whether it can predict such complex results before a study is conducted. Conclusions