Download
1 / 3
30 likes | 149 Views
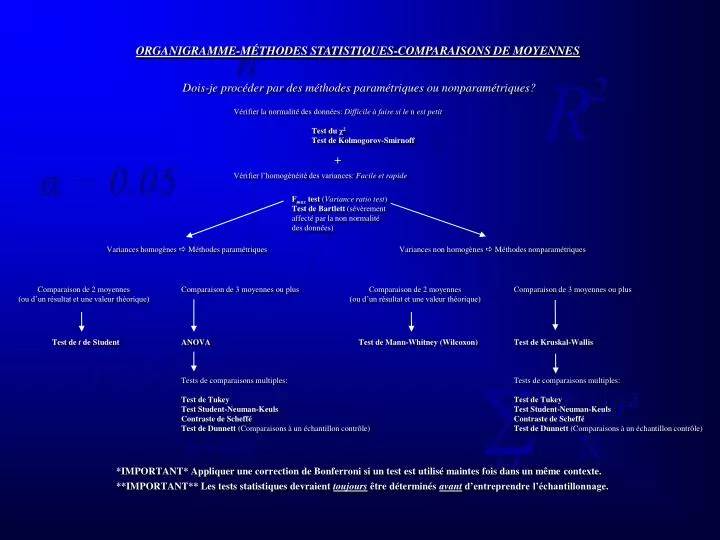
ORGANIGRAMME-MÉTHODES STATISTIQUES-COMPARAISONS DE MOYENNES. Dois-je procéder par des méthodes paramétriques ou nonparamétriques?. Vérifier la normalité des données: Difficile à faire si le n est petit Test du χ 2 Test de Kolmogorov-Smirnoff. +.

E N D
ORGANIGRAMME-MÉTHODES STATISTIQUES-COMPARAISONS DE MOYENNES Dois-je procéder par des méthodes paramétriques ou nonparamétriques? Vérifier la normalité des données: Difficile à faire si le n est petit Test du χ2 Test de Kolmogorov-Smirnoff + Vérifier l’homogénéité des variances: Facile et rapide Fmax test (Variance ratio test) Test de Bartlett (sévèrement affecté par la non normalité des données) Variances homogènes Méthodes paramétriques Variances non homogènes Méthodes nonparamétriques Comparaison de 2 moyennes (ou d’un résultat et une valeur théorique) Comparaison de 3 moyennes ou plus Comparaison de 2 moyennes (ou d’un résultat et une valeur théorique) Comparaison de 3 moyennes ou plus Test de t de Student ANOVA Test de Mann-Whitney (Wilcoxon) Test de Kruskal-Wallis Tests de comparaisons multiples: Test de Tukey Test Student-Neuman-Keuls Contraste de Scheffé Test de Dunnett (Comparaisons à un échantillon contrôle) Tests de comparaisons multiples: Test de Tukey Test Student-Neuman-Keuls Contraste de Scheffé Test de Dunnett (Comparaisons à un échantillon contrôle) *IMPORTANT* Appliquer une correction de Bonferroni si un test est utilisé maintes fois dans un même contexte. **IMPORTANT** Les tests statistiques devraient toujours être déterminés avant d’entreprendre l’échantillonnage.
Méthodes paramétriques: Font appel à des paramètres de population tels la moyenne μ et la variance σ2. Conditions d’application des méthodes paramétriques: Les données ont été échantillonnées aléatoirement; Les échantillons proviennent de populations ayant une distribution normale; Les variances des différents échantillons sont égales (homogénéité des variances). *Toutefois, les méthodes paramétriques sont suffisamment robustes pour répondre à des déviations considérables de leurs conditions d’application, surtout si la taille des échantillons n est égale ou presque égale (particulièrement vrai pour les tests bilatéraux). **Si les populations sont fortement asymétriques, les tests unilatéraux paramétriques sont à déconseiller. ***Si la condition de normalité des données est fortement violée, un seuil de signification (α) inférieur à 0.01 n’est pas fiable. ****Plus le n est grand, plus le test est robuste (il l’est d’autant plus que les n sont égaux). Si les n ne sont pas égaux, la probabilité de commettre une erreur de type I est inférieure à α si les plus grandes variances sont associées au plus grands échantillons, et supérieure à α si les plus petits échantillons possèdent les plus grandes variances. Méthodes nonparamétriques: Sont indépendantes des paramètres de population (Distribution-free methods). Ces méthodes s’avèrent plus puissantes (1-β) que les méthodes paramétriques lorsque celles-ci dérogent de leurs conditions d’application. Lorsque les deux types de méthodes peuvent être appliquées, la méthode paramétrique est toujours plus puissante que sa méthode nonparamétrique équivalente, et donc préférable. *Erreur de type I: Probabilité de rejeter l’hypothèse nulle alors que celle-ci est vraie. **Erreur de type II: Probabilité d’accepter l’hypothèse nulle alors que celle-ci est fausse.
Il y a moyen d’évaluer le n minimum requis pour observer une différence minimale détectable (δ), compte tenu de la puissance (1-β) et du seuil de signification (α) désirés. Il est souvent avantageux d’effectuer des pré-tests afin de déterminer le n minimal requis pour obtenir une différence significative. Plus les n sont grands, moins grande est la probabilité de commettre une erreur de type II. La puissance (φ) d’un test effectué peut être déterminée a posteriori (i.e. la probabilité d’avoir commis une erreur de type II). Lorsque l’on compare plus de deux moyennes, toujours procéder par ANOVA plutôt que par des tests de t comparant les moyennes deux à deux. E.g. Au seuil de signification α = 0.05, 3 moyennes comparées 2 à 2 13% de probabilité de commettre une erreur de type I entre les moyennes extrèmes… 10 moyennes comparées 2 à 2 63% de probabilité de commettre une erreur de type I entre les moyennes extrèmes… 20 moyennes comparées 2 à 2 92% de probabilité de commettre une erreur de type I entre les moyennes extrèmes… Il est parfois avantageux de transformer ses valeurs (e.g. log xi + 1) préalablement à l’application d’un test paramétrique si l’on sait, ou que l’on suspecte, que l’on ne satisfait pas à l’exigence de normalité des données. Ceci permet de se rapprocher de la normalité. Certains types de données ne suivent pas une distribution normale [e.g. événements aléatoires (Poisson), données nominales (binômiale)]. Excellentes références biostatistiques: Zar, J. H., Biostatistical Analyses; Sokal, R. R. & Rohlf, F. J., Biometry; Conover, W. J., Practical Nonparametric Statistics.