Download

1 / 32
320 likes | 422 Views
Learning Sets of Rules Tom Mitchel (cap. 10). Victor Cisneiros (vcac) Sergio Sette (sss3) Pablo Viana (pabv). Learning Sets of Rules. Objetivo: Estudar algoritmos capazes de aprender hipóteses como um conjunto de regras IF-THEN

E N D
Learning Sets of RulesTom Mitchel (cap. 10) Victor Cisneiros (vcac) Sergio Sette (sss3) Pablo Viana (pabv)
Learning Sets of Rules • Objetivo: Estudar algoritmos capazes de aprender hipóteses como um conjunto de regras IF-THEN • Ao contrário de outros métodos de aprendizagem como Redes Neurais por exemplo, regras no formato IF-THEN podem ser facilmente entendidas por pessoas humanas. • As regras aprendidas são expressões da lógica proposicional e da lógica de primeira-ordem
Motivação • Em 1995 um sistema PROGOL conseguiu aprender a seguinte regra a partir de vários dados de proteínas: • Fold(FOUR-HELICAL-UP-AND-DOWN-BUNDLE, p) ← Helix(p,h1) Λ Length(h1,HIGH) Λ Position(p,h1,n) Λ (1≤n≤3) Λ Adjacent(p,h1,h2) Λ Helix(p,h2) • Essa regra pode ser traduzida para o inglês como: • The protein P has a fold class “Four helical up and down bundle” if it contains a long helix h1 at a secondary structure position between 1 and 3 and h1 is next to a second helix.
Motivação • Essa facilidade de compreensão das regras torna esse método bastante atrativo para o uso em experimentos científicos • Biólogos poderiam por exemplo, estudar e criticar a tradução em inglês da hipótese mostrada no slide anterior
Como aprender um conjunto de regras? • Uma maneira seria utilizar uma árvore de decisão • Uma regra para cada folha: • IF (Outlook = Sunny) Λ (Humidity = High) THEN PlayTennis = NO • IF (Outlook = Sunny) Λ (Humidity = Normal) THEN PlayTennis = YES • IF (Outlook = Overcast) THEN PlayTennis = YES • ... etc
Outros Algoritmos • Podem aprender regras na forma de cláusulas de Horn de primeira-ordem • Ao contrário da árvore que aprende apenas regras proposicionais • Mais expressivo, permitem expressar variáveis e relacionamentos entre elas • Aprendem as regras uma de cada vez, iterando o processo até o final (Sequential Covering) • Árvores aprendem todo o conjunto de regras de uma só vez
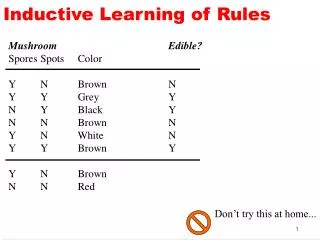
Considere a seguinte base de dados Attributes Target Attribute(O que se deseja aprender)
Sequential Covering • Suponha função LEARN-ONE-RULE • Entrada: Um conjunto de exemplos de treinamento positivos e negativos • Saída: Uma regra que cobre vários dos exemplos positivos e nenhum ou poucos negativos (A regra deve ter uma boa taxa de acerto mas não necessariamente precisa englobar muitos exemplos)
Sequential Covering • Dada essa função LEARN-ONE-RULE, um jeito óbvio de aprender um conjunto de regras seria: • 1. Invocar LEARN-ONE-RULE sobre todos os exemplos • 2. Remover todos os exemplos positivos cobertos pela regra aprendida • 3. Invocar LEARN-ONE-RULE novamente sobre os exemplos restantes • 4. Repetir o processo até atingir a fração desejada de exemplos positivos cobertos pelas regras
Como implementar LEARN-ONE-RULE? • Organizar o espaço de busca da mesma forma que o algoritmo ID3 de árvores de decisão • Começar com uma regra geral e ir adicionando os testes de atributos que mais melhoram a perfomance da regra • Ao contrário do algorítmo ID3, essa implementação só segue um único ramo da árvore
Como implementar LEARN-ONE-RULE? • O algoritmo sugerido anteriormente realiza uma busca em profundidade gulosa sem backtracking • Como toda busca gulosa, corre o risco de encontrar uma solução não ótima. Para minimizar isso pode se utilizar uma beam-search (a cada passo manter os K melhores candidatos) • Esse é o algoritmo CN2
First-Order Logic • Os algoritmos apresentados até agora só são capazes de aprender conjuntos de regras da lógica proposicional • Veremos a seguir, o algoritmo FOIL, capaz de aprender regras da lógica de primeira ordem, que são mais expressivas pois podem conter variáveis e são capazes de expressar relacionamentos entre elas
First-Order Logic • Constantes: Lula, ACM, unicórnio, 10 • Variáveis: x, y • Predicados: Corrupto, Maior_Que • Assumemvalores True ou False como resultado • Funções: idade • Assumem qualquer constante como resultado
First-Order Logic (Expressões) • Termo: Qualquer constante, variável ou qualquer função aplicada a um termo • Ex: Lula, x, idade(Lula) • Literal: Qualquer predicado aplicado a um termo, ou sua negação • Ex: Corrupto(ACM), ¬Maior_Que(idade(Lula), 60) • Cláusula: Qualquer disjunção de literais ... • Cláusula de Horn: Uma cláusula contendo no máximo 1 literal positivo • Ex: H V ¬L1V ... ¬Lnequivalente à H ← (L1Λ ... Λ Ln) ou IF L1Λ ... Λ Ln THEN H
FOIL • Algoritmo para aprendizagem de regras de primeira ordem (cláusulas de Horn) • Segue a mesma idéia dos já vistos SEQUENTIAL-COVERING e LEARN-ONE-RULE
FOIL • Ex: Suponha que queiramos aprender a definição do predicado Grandfather(x, y) • Divide-se os dados em exemplos positivos e negativos: • Positivos: { George, Anne } { Phillip, Peter } ... • Negativos: { George, Elizabeth } { Harry, Zarra } ...
FOIL (Ilustração Simples) • O algoritmo FOIL constrói um conjunto de cláusulas, cada uma com Grandfather(x, y) como “head” • → Grandfather(x, y) • Essa cláusula classifica todos os exemplos como positivos então é necessário especializá-la (adicionando liteirais). 3 adições em potencial: • Father(x, y) → Grandfather(x, y) • Parent(x, z) → Grandfather(x, y) • Father(x, z) → Grandfather(x, y) • O 1º classifca errado todos os 12 exemplos positivos, o 2º e 3º aceitam todos positivos mas erram alguns negativos, como o 3º erra menos escolhe-se ele • Father(x, z) Λ Parent(z, y) → Grandfather(x, y) • Como essa cláusula classifica corretamente todos os exemplos, o algoritmo FOIL irá escolhê-lo
FOIL – Especializando uma regra • Seja a regra atual P(x1,x2,...,xk) L1Λ ... Ln • L1 ... Ln são literais compondo as atuais condições e P(x1,x2,...,xk) o predicado que se deseja aprender. O FOIL irá gerar os seguintes candidatos: • Q(v1 ... vr) onde Q é qualquer predicado ocorrendo nos exemplos e v1 ... vr são quaisquer variáveis presentes na regra ou novas variáveis (no mínimo um vi deve pertencer a regra atual) • Equal(vj,vk) onde vj e vk são variáveis já presentes na regra • A negação de um dos literais acima
FOIL – Especializando uma regra • Exemplo: • regra atual = GrandDaughter(x,y) Father(y,z) • predicados = Father e Female • Os candidatos serão a adição dos seguintes literais à regra atual: • Equal(x,y), Female(x), Female(y), Father(x,y), Father(y,x) Father(x,z), Father(z,x), Father(y,z), Father(z,y) e a negação destes literais
FOIL – Especializando uma regra • Como escolher o candidato mais promissor? • Aquele que classifica o maior número de exemplos positivos e o menor número de exemplos negativos • Foil_Gain • p0 = número de exemplos positivos da regra atual • n0 = número de exemplos negativos da regra atual • p1 = número de exemplos positivos da regra especializada • n1 = número de exemplos negativos da regra especializada
Indução como o inverso da dedução • Uma abordagem diferente para a programação em lógica indutiva é baseada na observação de que a indução nada mais é que o inverso da dedução.
Invertendo o método da resolução • Método da Resolução: • Dada duas cláusulas C1 e C2, encontre a literal L de C1 tal que ¬L ocorre em C2. • Forme uma cláusula derivada C, incluindo os literais de C1 e C2, exceto L e ¬L. • C = (C1 – {L}) U (C2 – {¬L}) • Resolução inversa: • Dada duas cláusulas C1 e C, encontre a literal L que ocorre em C1, mas não aparece em C. • Forme a segunda cláusula C2, incluindo as literais: • C2 = (C - (C1 - {L})) U {¬L}
Resolução – First-Order Case • A diferença principal entre a resolução no caso proposicional e no de primeira-ordem é o processo de unificar substituições. • Uma substituição é qualquer mapeamento de variáveis a termos. • Na lógica de predicados para executar a resolução procuramos por uma literal L1 em C1, de modo que exista uma unificação de substituições entre ela e a negação de uma literal, ¬L2, em C2.
Resolução Inversa – First-Order Case • Podemos derivar da fórmula da resolução, por manipulação algébrica, considerando
Referências • Tom Mitchell. Machine Learning. McGraw-Hill. 1997. • Stuart Russel, Peter Norvig. Artificial Intelligence: A Modern Approach. Second Edition. Prentice Hall. 2002.