Download

1 / 32
320 likes | 339 Views
Stay organized with the semester schedule and the important deadlines for assignments, team projects, exams, and office hours.

E N D
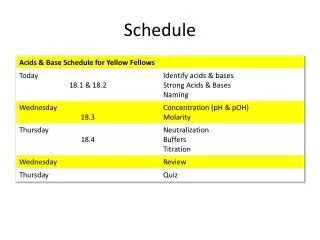
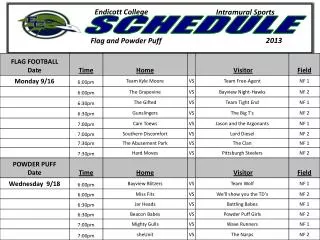
Semester Schedule • PLA5 Due 4/1/19 11:59pm to HuskyCT • PLA6 Due 4/15/19 11:59pm to HuskyCT • Team Project - 4/15/19 11:59pm Short PPT only • TeamXXShort.pptx • TeamXXLong.pptx • XX is your team A to Y • 5/3/19 11:59pm Final Paper, Long PPT, code • Exam • 4/9/19 closed book, T/F, multiple choice, etc. • 4/11/19 open anything problems • TA Office hours Yanyuan M 4pm-5pm, F 3pm-5pmChaoqun M 1:30-3:00 pm, W 1:30-3:00 pm SteveTTh 4:45-5:30
Advice on Short PPT • Only the Short PPT due 4/15, 11:59pm. • Starting April 16th we'll do 5 presentation to class. This us a cushion of one if we get delayed or there's some kind of conflict. • Each team 10-minute talk with 10-12 slides1 title slide with all student names1 paradigm / languages slide1 history of language line2-4 slides on each language2-4 slides the examples1 summary slideone language 4 slides per language/example two language 4 slides per language/example threee language 4 slides per language/example
Team Project Sample Emailed • Includes word report and powerpoint • Who did What.docx Please find below Authors of Report: Page 1-7, 15-17, 25 Person1 Page 8-11, 18-21, 25, Appendix B Person2 Page 12-14, 22-25 Person3 Please find below Authors of Long PPT: Slides 2-15, 43-54, 81 Person1 Slides 16-28, 55-65, 79, 81 Person2 Slides 29-42, 66-78, 80 Person3 Please find below Authors of Implementation: Cilk Implementation and Code: Author: Person3 1. Groote 1-D implementation in Cilk (Groote1D.cpp) 2. Groote 2-D implementation in Cilk (Groote2D.cpp) 3. Groote 3-D implementation in Cilk (Groote3D.cpp) ParaSail Implementation and Code: 1. Quick Sort implementation (qsort.psl). Author: Person2 2. Fibonacci implementation (Fibonacci.psl) Author: Person1
PLA6Logic Programming with Prolog Due Friday, April 25, 11:59pm (30 pts) • Relational database consisting of four tables of information on • suppliers (S), parts (P), projects (J), project (SPJ) • Supplier numbers (S#), part numbers (P#), & project numbers (J#), are unique in tables S, P, & J • http://wiki.c2.com/?SupplierPartsProjectsDatabase • Represent DB as Prolog Facts • Define Relevant Prolog Rules • Write Prolog Queries
Prolog Facts and Rules – pla6pll supp(s# sname status city) part(p# pname color weight city) proj(j#jname city) sppj(s# p# j#qty) suppliesparts(S,P,N,T,C,J,A):-supp(S,N,T,C),sppj(S,P,J,A). usedbyproject(P,N,C,A,L,S,J,D):-part(P,N,C,A,L),sppj(S,P,J,D). usesparts(J,A,B,P,N,S,J,X,G,H):- proj(J,A,B), sppj(S,P,J,X), part(P,N,G,H). notinlocation(S,N,T,C,J,A,B):-supp(S,N,T,C),proj(J,A,B),not(C=B).
Prolog Queries • When given a pair of projects, find all suppliers who supply both projects. Return the entire entry (i.e., S#, Sname, Status, City) for the supplier. • When given a city, find all parts supplied to any project in that city. Once again, return the entire entry for the part. Find all parts supplied to any project by a supplier in the same city. In this case, results are organized by all parts for every city in the database. • Find all projects supplied by at least one supplier not in the same city. • Find all suppliers that supply at least one part supplied by at least one supplier who supplies at least one red part. • Find all pairs of city values such that a supplier in the first city supplies a project in the second city. • Find all triples of city, part#, city, such that a supplier in the first city supplies the specified part to a project in the second city, and the two city values are different. • When given a supplier, find all projects supplied entirely by that supplier.
PLA5 Word Index Using Strings in Ada April 1, 11:59pm (30 pts) • Extend PLA4v3 with a word index that tracks the line(s) within the input file where each word occurs. There may be multiple occurrences of the word in a file. Current output of PLA3v3 is: Goodbye 4 Hello 1 World 1 • You are to update the output to: Goodbye: in lines 1-2-5-6 wc=4 Hello: in lines 3 wc=1 World: in lines 3 wc=1 • Assume: Each word at least one character and start with a letter. If a word has 2 or more characters, then the second and successive characters can be letters, digits, the underscore, or the hyphen
new_u_words_min.adb -- Read one word per line and print list of unique words and their frequencies -- Case sensitive. This is a minimalist version. No bells or whistles. With ada.integer_text_io; use ada.integer_text_io; With ada.text_io; use ada.text_io; Procedure new_u_words_minis type Word is record s: String(1 .. 120); -- The string. Assume 120 characters or less wlen: Natural; -- Length of the word Count:Natural:=0; -- Total number of occurrences of this word LineNo: Natural :=0; -- Word found on LineNo end record; type Word_Arrayis array(1 .. 1000) of Word; type Word_Listis record words: Word_Array; -- The unique words Num_Words:Natural:=0; -- How many unique words seen so far curr_line: Natural := 1; -- Current Line end record;
new_u_words_min.adb procedure get_words(wl: out Word_List) is begin wl.num_words := 0; -- only to get rid of a warning while not End_of_Fileloop declare s: String := Get_Line; found: Boolean := false; begin for iin 1 .. wl.num_wordsloop if s = wl.words(i).s(1 .. wl.words(i).wlen) then wl.words(i).count := wl.words(i).count + 1; found := true; end if; exit when found; end loop;
new_u_words_min.adb if not found then -- Add word to list wl.num_words := wl.num_words + 1; wl.words(wl.num_words).s(1 .. s'last) := s; wl.words(wl.num_words).wlen := s'length; Wl.Words(Wl.Num_Words).Count := 1; Wl.Words(Wl.Num_Words).LineNo:= wl.curr_line; -- set LineNo of word wl.curr_line := wl.curr_line + 1; -- one word per line so increase curr_line end if; end; -- declare end loop; end get_words;
new_u_words_min.adb procedure put_words(wl: Word_List) is begin for iin 1 .. wl.num_wordsloop put(wl.words(i).LineNo); put(wl.words(i).count); put(" " & wl.words(i).s(1 .. wl.words(i).wlen)); new_line; end loop; end put_words; the_words: Word_List; begin get_words(the_words); put_words(the_words); end new_u_words_min;
Output of Revised Program • First number is last line it appeared • Second number occurence
Suggested Solution Approach • Build an dedicated output string for the word, its occurrences in lines, and final word count. • Programmatically, for the word “Goodbye” the string would be built in the following steps: Goodbye in lines: -- create when the word is first found Goodbye in lines: 1 -- append “ 1” when the word is first found Goodbye in lines: 1-2 -- append “-2” when the word is found in line 2 Goodbye in lines: 1-2-5 -- append “-5” when the word is found in line 5 Goodbye in lines: 1-2-5-6 -- append “6” when the word is found in line 7 Goodbye in lines: 1-2-5-6-6 -- append “6” when the word is found again in line 7 -- Etc… • Built as the words are recognized on each line • After EOF reached for all words, you print out the new dedicated output string for the word and append “wc=” and then print out the word count 5 as an integer • You can also convert the word count to string and append
PLA4 Due 3/14/19 11:59pm To HuskyCT • Modify an existing word frequency function Ada program (u_words_min.adb) or (u_words_tight.adb) that implements WFF by assuming that there is one word in every line of the input. • Both of the adb files assume a word of 20 characters as a string – in the posted web copies of the two files, this has been increased to 120 which has the result of reading the entire line and treating the entire line as one large word which can include spaces. • So, when the program is compiled and run, the input generates the following output:
PLA4 Due 3/14/19 11:59pm To HuskyCT • This programming project is an exercise in learning a new language by having to modify and extend someone else’s code. The specific extensions are as follows for three separate versions: • V1: Change the original program to alphabetically sort the outputted list of words – first executable. • V2: + V1 Change the logic so that the words within each line are identified – this would then result in a full word frequency functionality and if the sort has been implemented, it will now sort the entire list – second executable. • V3: +V1+V2 Change the program so that the data is read from input.txt and written to output.tex – third executable. • Use AdaGIDE https://sourceforge.net/projects/adagide/and upload your .adb files to HuskyCT. If you use a GNAT compiler, please make sure it compiles/runs in the IDE.
Three Versions • (10 pts) V1Change the original program to alphabetically sort the outputted list of words – first executable. • (10 pts) V2 + V1 Change the logic so that the words within each line are identified – this would then result in a full word frequency functionality and if the sort has been implemented, it will now sort the entire list – second executable. • (10 pts) V3+V1+V2 Change the program so that the data is read from input.txt and written to output.tex – third executable.
u_words_min.adb -- Read one word per line and print list of unique words and their frequencies -- Case sensitive -- This is a minimalist version. No bells or whistles. with ada.integer_text_io; use ada.integer_text_io; with ada.text_io; use ada.text_io; procedure u_words_minis type Word is record s: String(1 .. 120); -- The string. Assume 120 characters or less wlen: Natural; -- Length of the word count: Natural := 0; -- Total number of occurrences of this word end record; type Word_Arrayis array(1 .. 1000) of Word; type Word_Listis record words: Word_Array; -- The unique words num_words: Natural := 0; -- How many unique words seen so far end record;
u_words_min.adb procedure get_words(wl: out Word_List) is begin wl.num_words := 0; -- only to get rid of a warning while not End_of_Fileloop declare s: String := Get_Line; found: Boolean := false; begin for iin 1 .. wl.num_wordsloop if s = wl.words(i).s(1 .. wl.words(i).wlen) then wl.words(i).count := wl.words(i).count + 1; found := true; end if; exit when found; end loop;
u_words_min.adb if not found then -- Add word to list wl.num_words := wl.num_words + 1; wl.words(wl.num_words).s(1 .. s'last) := s; wl.words(wl.num_words).wlen := s'length; wl.words(wl.num_words).count := 1; end if; end; -- declare end loop; end get_words;
u_words_min.adb procedure put_words(wl: Word_List) is begin for iin 1 .. wl.num_wordsloop put(wl.words(i).count); put(" " & wl.words(i).s(1 .. wl.words(i).wlen)); new_line; end loop; end put_words; the_words: Word_List; begin get_words(the_words); put_words(the_words); end u_words_min;
u_words_tight.adb -- Read one word per line and print list of unique words and their frequencies -- Case sensitive. -- This is a minimalist version. -- No bells or whistles. -- This version has a fast inner loop. -- It has only one comparison. -- This is done by always putting the word being sought at the end of the list. -- If the word being sought is found earlier in the list, --. then the value at the end is ignored. -- If it is not found earlier, then it has already been added. -- The final location in the list can’t hold a word that is being counted. -- It can only be used to hold a sentinal during a search.
u_words_tight.adb with ada.integer_text_io; use ada.integer_text_io; with ada.text_io; use ada.text_io; procedure u_words_tightis type Word is record str: String (1 .. 120); -- The string. Assume 120 characters or less wlen: Natural; -- Length of the word count: Natural := 1; -- Total number of occurrences of this word end record; type Word_Arrayis array(1 .. 1000) of Word; type Word_Listis record words: Word_Array; -- The unique words num_words: Natural; -- How many unique words seen so far end record;
u_words_tight.adb procedure get_words (wl: out Word_List) is i : Natural; begin wl.num_words := 0; -- Initialize here to avoid a warning while not End_of_Fileloop declare s: String := Get_Line; begin wl.words (wl.num_words + 1).str (1 .. s'Last) := s; wl.words (wl.num_words + 1).wlen := s'Length; i := 1; while s /= wl.words (i).str (1 .. wl.words (i).wlen) loop i := i + 1; end loop; -- s = wl.words(i) if i = wl.num_words + 1 then wl.num_words := wl.num_words + 1; else wl.words(i).count := wl.words(i).count + 1; end if; end; -- declare end loop; end get_words;
u_words_tight.adb procedure put_words (wl: Word_List) is begin for iin 1 .. wl.num_wordsloop put (wl.words(i).count); put (" " & wl.words(i).str(1 .. wl.words(i).wlen)); new_line; end loop; end put_words; the_words: Word_List; begin get_words (the_words); put_words (the_words); end u_words_tight;
PLA3 Due 2/28/19 11:59pm To HuskyCT • We’re Using XDS-IDE: • https://www.excelsior-usa.com/xds.html • https://github.com/excelsior-oss/xds-ide/releases/tag/xds-ide-1.7.0 • Just Extract the zip file to a directory on your desktop • There is a WCF Modula-2 solution you can utilize as a basis • Code samples http://sdcse.engr.uconn.edu/Cse4102/PascalModula2Samples.zip
PLA3 Due 2/28/19 11:59pm To HuskyCT • Utilize XDS-IDE for a WFF Dual Solution • Single module solution using records based off of findwords.mod sample code that outputs to stdout a list of words and their frequency • Single module reworking first solution into • A read procedure that reads the lines into the document variable of type AllLines • A wff procedure that generates word frequency in the wordsindoc variable of type AllWords and WordFreq record • A sortandprint procedure that outputs to stdout a list of words and their frequency in alpha order • http://www.engr.uconn.edu/~steve/Cse4102/PascalModula2Samples.zip
PLA3 Modula-2 Program - Implement WFF - Due February 28, 11:59pm • Implement the Word Frequency Function (WFF) in Modula-2, sort final word list using findwords.mod: http://sdcse.engr.uconn.edu/Cse4102/PascalModula2Samples.zip • You need to develop a (two programs) for this project: • Single module solution using records based off of findwords.mod that outputs to stdout a list of words and their frequency • Single module reworking your solution from A into a read procedure that reads the lines into the document variable of type AllLines, a wff procedure that generates the word frequency in the wordsindoc variable of type AllWords and the WordFreq record, and a sortandprint procedure that outputs to stdout a list of words and their frequency in alphabetical order. • Utilize XDS Modula-2 https://www.excelsior-usa.com/xds.htmland and upload your .mod files to HuskyCT. If you use a GNU compiler, please make sure it compiles/runs in the IDE.
CSE4102 AnnouncementsPLA2 Due 2/14/19 11:59pm To HuskyCT • Utilize Dev-Pascal • Implement both WCF and WFF • Just open and save a file • No need to Alphabetize • Code sample http://sdcse.engr.uconn.edu/Cse4102/PascalModula2Samples.zip • Consider starting with readwritetofilesNEW.pas
PLA2 Pascal Program– Implement WCF & WFF- Due Feb 14, 11:59pm • Implement the Word Count Functionality (WCF) and Word Frequency Functionality (WFF) in Pascal as described in: http://sdcse.engr.uconn.edu/Cse4102/CommonProbBackground.pdf • Utilize Dev-Pascal http://www.bloodshed.net/devpascal.html and upload your .pas file to HuskyCT. • Note for WCF you need to read in and process a line at a time. For WFF, you need to define a record and an array of that record similar to the structure utilized in C. If you use a GNU compiler, please make sure it compiles/runs in the IDE.
CSE4102 AnnouncementsPLA1 Due 1/31/19 11:59pm to HuskyCT • Need to store backslash zero '\0' at the end of the string in order to terminate the string so that the strcpy, printf %s, etc. will work • Must Compile/Run under gcc • Three test cases: test1.txt test2.txt test3.txt • Compile using as below if argc argvgccWCF.c./a.out test1.txt test2.txt