Download

1 / 42
420 likes | 560 Views
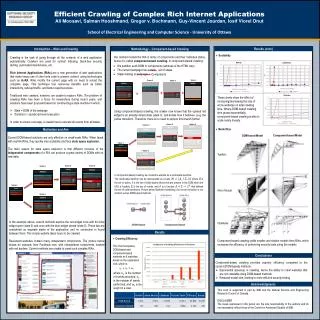
Efficient Complex Operators for Irregular Codes. Jack Sampson , Ganesh Venkatesh, Nathan Goulding-Hotta, Saturnino Garcia, Steven Swanson, Michael Bedford Taylor Department of Computer Science and Engineering University of California, San Diego. The Utilization Wall.

E N D
Efficient Complex Operators for Irregular Codes Jack Sampson, Ganesh Venkatesh, Nathan Goulding-Hotta, Saturnino Garcia, Steven Swanson, Michael Bedford Taylor Department of Computer Science and Engineering University of California, San Diego
The Utilization Wall With each successive process generation, the percentage of a chip that can actively switch drops exponentially due to power constraints. [Venkatesh, Chakraborty]
Classical scaling Device count S2 Device frequency S Device power (cap) 1/S Device power (Vdd) 1/S2 Utilization 1 Leakage limited scaling Device count S2 Device frequency S Device power (cap) 1/S Device power (Vdd) ~1 Utilization 1/S2 Scaling theory Transistor and power budgets no longer balanced Exponentially increasing problem! Observed impact Experimental results Flat frequency curve Increasing cache/processor ratio “Turbo Boost” The Utilization Wall [Venkatesh, Chakraborty]
Scaling theory Transistor and power budgets no longer balanced Exponentially increasing problem! Observed impact Experimental results Flat frequency curve Increasing cache/processor ratio “Turbo Boost” The Utilization Wall 2x 2x 2x [Venkatesh, Chakraborty]
Scaling theory Transistor and power budgets no longer balanced Exponentially increasing problem! Observed impact Experimental results Flat frequency curve Increasing cache/processor ratio “Turbo Boost” The Utilization Wall 3x 2x [Venkatesh, Chakraborty]
Dealing with the Utilization Wall • Insights: • Power is now more expensive than area • Specialized logic has been shown as an effective way to improve energy efficiency (10-1000x) • Our Approach: • Use area for specialized cores to save energy on common apps • Can apply power savings to other programs, increasing throughput • Specialized coprocessors provide an architectural way to trade area for an effective increase in power budget • Challenge: coprocessors for all types of applications
Specializing Irregular Codes • Effectiveness of specialization dependent on coverage • Need to cover many types of code • Both regular and irregular • What is irregular code? • Lacks easily exploited structure / parallelism • Found broadly across desktop workloads • How can we make it efficient? • Reduce per-op overheads with complex operators • Improve latency for serial portions
Candidates for Irregular Codes • Microprocessors • Handle all codes • Poor scaling of performance vs. energy • Utilization wall aggravates scaling problems • Accelerators • Require parallelizable, highly structured code • Memory system challenging to integrate with conventional memory • Target performance over energy • Conservation Cores (C-Cores) [Venkatesh, et al. ASPLOS 2010] • Handle arbitrary code • Share L1 cache with host processor • Target energy over performance
Conservation Cores (C-Cores) Automatically generated from hot regions of program source Hot code implemented by C-Core, cold code runs on host CPU Profiler selects regions C-to-Verilog compiler converts source regions to C-Cores Drop-in replacements for code No algorithmic changes required Software compatible in absence of available C-Core Toolchain handles HW generation/SW integration Hot code D cache C-Core Host CPU (general purpose) I cache [Venkatesh, et al. ASPLOS 2010] Cold code
This Paper: Two Techniques for Efficient Irregular Code Coprocessors • Selective De-Pipelining (SDP) • Form long combinational paths for non-pipeline parallel codes • Run logic at slow frequency while improving throughput! • Challenge: handling memory operations • Cachelets • L1 access is a large fraction of critical path for irregular codes • Can we make a cache hit only 0.5 cycles? • Specialize individual loads and stores • Apply both to the C-Core platform • Up to 2.5x speedup vsan efficient in-order processor • Up to 22x EDP improvement
Outline • Efficiency through specialization • Baseline C-Core Microarchitecture • Selective De-Pipelining • Cachelets • Conclusion
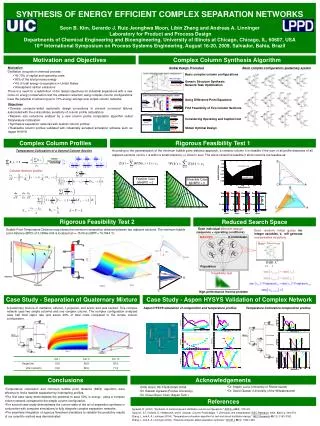
Constructing a C-Core C-Cores start with source code Parallelism agnostic Function call interface Code supported Arbitrary memory access patterns Data structures Complex control flow No parallelizing compiler required Example code for (i=0; i<N; i++) { x = A[i]; y = B[i]; C[x] = D[y] + x + y + x*y; }
Constructing a C-Core C-Cores start with source code Parallelism agnostic Function call interface Code supported Arbitrary memory access patterns Data structures Complex control flow No parallelizing compiler required BB0 BB1 BB2 CFG
Constructing a C-Core C-Cores start with source code Parallelism agnostic Function call interface Code supported Arbitrary memory access patterns Data structures Complex control flow No parallelizing compiler required BB1 + +1 + LD LD + <N? + LD + * + + ST DFG
Constructing a C-Core (cont.) + + + LD LD * + + + LD + ST +1 • Schedule memory operations on L1 • Add pipeline registers to match host processor frequency <N?
Observation + + + LD LD * + + + LD + ST +1 • Pipeline registers just for timing • No actual overlap in execution between pipeline stages <N?
Outline • Efficiency through specialization • Baseline C-Core Microarchitecture • Selective De-Pipelining • Cachelets • Conclusion
Meeting the Needs of Datapath and Memory • Datapath • Easy to replicate operators in space • Energy-efficient when operators feed directly to operators • Memory • Interface is inherently centralized • Performance-efficient when the interface can be rapidly multiplexed • Can we serve both at once?
Constructing Efficient Complex Operators Direct mapping from CFG, DFG Produces large, complex operators (one per CFG node) BB0 CFG + + + + + + LD LD LD LD BB1 * * + + + + BB2 + + LD LD + + ST ST +1 +1 <N? <N? Complex Operator
SDP addresses the needs of datapath and memory Fast, pipelined memory Slow, aperiodic datapath clock Selective De-Pipelining (SDP) clock Memory mux + + + LD + + + LD + + * + + + LD + ST + + +1 <N?
Intra-basic-block registers on fast clock for memory Registers between basic blocks clocked on slow clock Selective De-Pipelining (SDP) clock Memory mux + + + LD + + + LD + + * + + + LD + ST + + +1 <N?
Constructs large, efficient operators Combinational paths spanning entire basic block In-order memory pipelining, handles dependence Selective De-Pipelining (SDP) clock Memory mux + + + LD + + + LD + + * + + + LD + ST + + +1 <N?
SDP Benefits • Reduced clock power • Reduced area • Improved inter-operator optimization • Easier to meet timing
SDP creates more energy-efficient coprocessors SDP Results (EDP improvement)
SDP Results (speedup) • New design faster than C-Cores, host processor • SDP most effective for apps with larger BBs
Outline • Efficiency through specialization • Baseline C-Core Microarchitecture • Selective De-Pipelining • Cachelets • Conclusion
Motivation for Cachelets • Relative to a processor • ALU operations ~3x faster • Many more ALU operations executing in parallel • L1 cache latency has not improved • L1 cache latency more critical for C-Cores • L1 access is 9x longer than an ALU op! • Can we make L1 accesses faster?
Cache Access Latency • Limiting factor for performance • 50% of scheduling latency for last op on critical path • Closer caches could reduce latency • But must be very small
Cachelets • Integrate into datapath for low-latency access • Several 1-4 line fully-associative arrays • Built with latches • Each services subset of loads/stores • Coherent • MEI states only (no shared lines) • Checkout/shootdown via L1 offloads coherence complexity
Cachelet Insertion Policies • Each memory operation mapped to cachelet or L1 • Profile-based assignment • Two policies: Private and Shared • Fewer than 16 lines per C-Core, on average • Private: One operation per cachelet • Average of 8.4 cachelets per C-Ccore • Area overhead of 13.4% • Shared: Several operations per cachelet • 6.2 cachelets per C-Ccore, • Average sharing factor of 10.3 • Area overhead of 16.8%
CacheletImpactonCriticalPath • Provide majority of utility of full sized L1 at cachelet latency • Improve EDP – reduction in latency worth the energy
Cachelet Speedup over SDP • Benefits of cachelets depend on application • Best when there are several disjoint memory access streams • Usually deployed for spatial rather than temporal locality
C-Cores with SDP and Cachelets vs. Host Processor • Average speedup of 1.61x over in-order host processor
C-Cores with SDP and Cachelets vs. Host Processor • 10.3x EDP improvement over in-order host processor
Conclusion • Achieving high coverage with specialization requires handling both irregular and regular codes • Selective De-Pipelining addresses the divergent needs of memory and datapath • Cachelets reduce cache access time by a factor of 6 for subset of memory operations • Using SDP and cachelets, we provide both 10.3x EDP 1.6x performance improvements for irregular code
Application Level, with both SDP and Cachelets • 57% EDP reduction over in-order host processor
Application Level, with both SDP and Cachelets • Average application speedup of 1.33x over host processor
SDP creates more energy-efficient coprocessors SDP Results (Application EDP improvement)
SDP Results (Application Speedup) • New design faster than C-Cores, host processor • SDP most effective for apps with larger BBs
Cachelet Speedup over SDP (Application Level) • Benefits of cachelets depend on application • Best when there are several disjoint memory access streams • Usually deployed for spatial rather than temporal locality