Download

1 / 37
370 likes | 486 Views
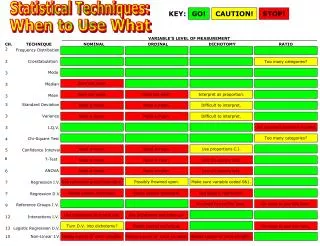
Start here. Statistical Techniques I. EXST7005. Measures of Central Tendency. Course Progression. Objective - Hypothesis testing Background We will test primarily means, but also variances - Means and other measures of central tendency will be discussed. SUMMATION OPERATIONS.

E N D
Start here Statistical Techniques I EXST7005 Measures of Central Tendency
Course Progression • Objective - Hypothesis testing Background • We will test primarily means, but also variances - • Means and other measures of central tendency will be discussed
SUMMATION OPERATIONS • The symbol will be used to represent summation • Given a variable, Yi • Representing a series of observations from Y1 (the first observation) to Yn (the last observation out of "n" observations) • The notation Yi represents the sum of all of the Yi values from the first to the last
This notation represents the summation of all Yi starting at i=1 and ending at i=n
Example of Summation • EXAMPLE: A variable "length of Bluegill in centimeters" is measured for individuals captured in a seine. This quantitative variable will be called "Y", and the number of individuals captured will be represented by "n". • For this example let n = 4 • The variable Yi is subscripted in order to distinguish between the individual fish (i) • Y1 = 3, Y2 = 4, Y3 = 1, Y4 = 2
Example of Summation (continued) • Summation operation: To indicate that we wish to sum all individuals in the sample (size n) we write • Yi = Y1 +Y2 +Y3 +Y4 = 3+4+1+2 = 10 • where, n = 4
Sum of Squares • To indicate the sum of squared numbers, simply indicate the square of the variable after the summation notation. • = Y12 + Y22 + Y32 + Y42 = 32 + 42 + 12 + 22 = 9 +16 +1 + 4 = 30 • where n = 4 • this is called the Sum of Squares, and should not be confused with the ...
Square of the Sum • Yi = 10 • The square of the sum is represented as (Yi)2. • Yi)2 = 102 = 100
Measures of Central Tendency • a measure of location on a scale • The most common measure is called the Arithmetic mean or the "average" • the sum of all observations divided by the number of observations. • This is calculated as the sum of the values of the variable of interest (Yi) divided by the number of values summed (n).
Example of Calculation of the Mean for 4 fish lengths • we previously determined that • Yi = Y1 +Y2 +Y3 +Y4 = 10 • where, n = 4 • The mean is Yi/n = 10/4 = 2.5
For a larger sample of fish • Yi = 7, 9, 9, 3, 6, 5, 0, 7, 0, 7 • n=10 • Yi = (7+9+9+3+6+5+0+7+0+7) = 53 • The mean is 53 / 10 = 5.3
MEDIAN - the central-most observation in a ranked (ordered or sorted) set of observations. If the number of observations is even, take the mean of the center most 2 observations • EXAMPLE: for the fish sample used earlier, rank the observations • Yi = 0, 0, 3, 5, 6, 7, 7, 7, 9, 9 • Since there is an even number of observations, the central most 2 are 6 and 7. If a single observation was in the center, it would be used. In this case the center falls between two numbers, so calculate • MEDIAN = (6 + 7) / 2 = 6.5 Other measures of central tendency
MODE value of the most frequently occurring observation • EXAMPLE: For the fish sample, • Y = 0, 0, 3, 5, 6, 7, 7, 7, 9, 9 • the most frequently occurring value was "7". • Therefore MODE = 7 Other measures of central tendency (continued) Value of Size Frequency 0 2 3 1 5 1 6 1 7 3 9 2
Other measures of central tendency (continued) • MIDRANGE - average of the largest and smallest observation. • EXAMPLE: The smallest observation in the fish sample was 0 and the largest was 9. The midrange is calculated as • MIDRANGE (0 + 9) / 2 = 4.5 • do not make the mistake of subtracting the lower from the higher, this is the RANGE, not the midrange
Which measure of Central Tendency is best • This depends on the distribution • If the distribution is monomodal and symmetric then the • MEAN = MEDIAN = MODE = MIDRANGE • e.g. the NORMAL bell-shaped curve
Which measure of Central Tendency is best (continued) • Bimodal distributions are not well described by any measure of central tendency, particularly the MODE
Asymmetrical distributions may be best described by the MEDIAN or MODE, depending on the objectives. • POSITIVE SKEW • Mode MEDIAN Mean Which measure of Central Tendency is best (continued)
Which measure of Central Tendency is best (continued) • NEGATIVE SKEW • MEAN MEDIAN MODE
Relative positions of the MEAN, MEDIAN and MODE • the MEAN is closest to the drawn out tail of the distribution. • the MODE is farthest from the tail. • the MEDIAN is intermediate. Statistic Negatively Skewed Symmetric Positively Skewed MODE Largest Middle Smallest MEDIAN Middle Middle Middle Largest MEAN Smallest Middle
The MEAN is generally preferred because • utilizes all information in the data set • it is widely recognized and is easy to work with • the distribution of the means tends to be normally distributed even if the original observations are not. • it is generally more sensitive to changes in the form of the distribution • e.g. asymmetry, though this is not always an advantage Selecting a measure of CENTRAL TENDENCY
Selecting a measure of CENTRAL TENDENCY (continued) • The MEDIAN or MODE may be desirable for asymmetric data sets • they may give a more representative measure of location • EXAMPLE: Find a "typical" salary for a business employing 5 individuals. • The salaries are: • $100,000 $30,000 $20,000 $15,000 $10,000
MEAN = $175000 / 5 = $35,000 • MEDIAN = $20,000 • MODE - there is no mode unless the data are arbitrarily grouped, and if grouped, two different people may not get the same mode • e.g. Salary Interval Frequency • 1 - 10000 1 • 10001 - 20000 2<=== MODE here • 20001 - 30000 1 • 30001 and over 1 CENTRAL TENDENCY (continued)
CENTRAL TENDENCY (continued) • MEDIAN and MODE do not use all of the information in the data set for calculation, so they are less sensitive to change. • For example if the top person above gets a raise to $200,000 the MEDIAN and MODE do not change. This can be either an advantage or a disadvantage, depending on the objectives. • HOWEVER, the MEAN increases from $35,000 to $75, 000
we will examine "parametric" statistical techniques • These techniques assume that the data conforms to a normal, bell-shaped curve. • We are able to assume that these techniques are adequate under the following conditions. • The data is normal, or "approximately" normal (e.g. symmetric) since the parametric techniques are robust to violations of the assumption of normality.
The sample size is large and hypotheses of the means are to be tested, since the means will tend to be normally distributed even if the original observations are not. • The distribution is known, or can be determined from a large sample, and can therefore be transformed to approximate normality. • For example, the number of individuals in many biological situations is commonly negatively binomially distributed. The original observations can be transformed by taking logarithms to approximate normality. Parametric statistics
OTHER TYPES OF MEANS • ARITHMETIC means: no transformation • GEOMETRIC means: result from a logarithmic transformation • GM(Yi)=nth root of (Y1*Y2*Y3*Y4*...*Yn) • EXP [{log(Y1)+log(Y2)+log(Y3)+log(Y4)...+log(Yn)}/n] • HARMONIC means: result from an inverse transformation • HM(Yi ) = INV({1/Y1+1/Y2+1/Y3+1/Y4...+1/Yn}/n)
Example calculations for 3 observations a b c d e f g Case Obs 1 5 5 5 5 5 5 5 Obs 2 5 5 5 5 5 5 30 Obs 3 5 10 100 1000 10000 85 50 Mean 5.00 6.67 36.67 336.67 3336.67 31.67 28.33 GM 5.00 6.30 13.57 29.24 63.00 12.86 19.57 11.84 HM 5.00 6.00 7.32 7.48 7.50 7.29 It is always true that HM GM Mean
Applications for other types of means • Arithmetic mean - the usual case • Geometric mean - Used as a transformation for some non-normal distributions • Particularly the negative binomial, a strongly skew distribution
Harmonic mean - used for particular cases where the probability of being sampled is an inverse function of the variable of interest • e.g. How long do fishermen fish in a day? • Suppose 8 fishermen go for 1 hour and one fisherman goes fishing for 8 hours. We go to sample and get one who plans to fish for one hour and one who plans to fish for 8 hours. The true mean is 16/9=1.778 • The arithmetic mean = (8+1)/2 = 4.5 hours • The harmonic mean = 1/((0.125+1)/2)=1.778 Other types of means (continued)
Population means • Remember always that our sample estimate of the mean is just one of many possible samples. Each sample is an attempt to estimate the true population mean. Our sample may be one of the good ones, pretty close to the true population mean, or it may be one of the not so good ones. We won't really know.
Population means (continued) • The true population mean is called , the greek letter mu • The sample estimate of the mean is denoted Y, called "y-bar".
How good is our estimate from the sample? This depends a lot on how good our sample is and on how much variability there is in the population. • Our best guarantee of getting a good sample is to sample at random. This should at least give us a representative sample of the population. • Variability is the other big problem in sampling, so we need to estimate how variable the population is, our next topic. Population means (continued)
PROC UNIVARIATE DATA=ONE PLOT; VAR SALEPRIC; TITLE3 'Frequency table of house Sale Price'; RUN; Analysis of house sale price data Table 1.1 from Freund & Wilson, 1997 Frequency table of house Sale Price Univariate Procedure Variable=SALEPRIC Moments N 42 Sum Wgts 42 Mean 41.37393 Sum 1737.705 Std Dev 12.44694 Variance 154.9264 Skewness -0.04538 Kurtosis 0.486405 USS 78247.67 CSS 6351.983 CV 30.08403 Std Mean 1.920605 T:Mean=0 21.54213 Pr>|T| 0.0001 Num ^= 0 42 Num > 0 42 M(Sign) 21 Pr>=|M| 0.0001 Sgn Rank 451.5 Pr>=|S| 0.0001 SAS example (#1 continued)
PROC UNIVARIATE DATA=ONE PLOT; VAR SALEPRIC; TITLE3 'Frequency table of house Sale Price'; RUN; Quantiles(Def=5) 100% Max 75 99% 75 75% Q3 48.9 95% 58.5 50% Med 42.85 90% 55.5 25% Q1 35.5 10% 22 0% Min 15 5% 19 1% 15 Range 60 Q3-Q1 13.4 Mode 37 Extremes Lowest Obs Highest Obs 15( 3) 55.5( 35) 18.9( 4) 56.35( 39) 19( 1) 58.5( 40) 19.8( 2) 61.35( 41) 22( 13) 75( 42) SAS example (#1 continued)
PROC UNIVARIATE DATA=ONE PLOT; VAR SALEPRIC; TITLE3 'Frequency table of house Sale Price'; RUN; Stem Leaf # Boxplot 7 5 1 0 7 6 6 1 1 | 5 668 3 | 5 00034 5 | 4 678889 6 +-----+ 4 00334444 8 *--+--* 3 5566777899 10 +-----+ 3 4 1 | 2 66 2 | 2 02 2 | 1 599 3 0 ----+----+----+----+ Multiply Stem.Leaf by 10**+1 SAS example (#1 continued)
PROC UNIVARIATE DATA=ONE PLOT; VAR SALEPRIC; TITLE3 'Frequency table of house Sale Price'; RUN; Analysis of house sale price data Table 1.1 from Freund & Wilson, 1997 Frequency table of house Sale Price Univariate Procedure Variable=SALEPRIC Normal Probability Plot 77.5+ * | +++ | ++++ | +++* | +*+** | +++** 47.5+ ****** | +**** | ***+*** | **++ | ++** | ++++ * 17.5+ *+++* ** +----+----+----+----+----+----+----+----+----+----+ -2 -1 0 +1 +2 SAS example (#1 continued)