Download

1 / 31
310 likes | 479 Views
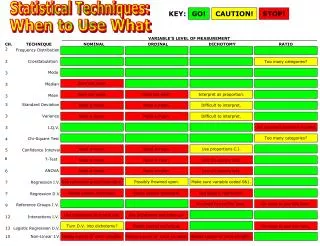
Statistical Techniques . Power and Types of Errors. Hypothesis testing Concepts. Logic of Test of Hypothesis is based on the selected probability, (significance level) for the test statistic (Z) which determines the range of what would be expected due to chance alone.

E N D
Statistical Techniques Power and Types of Errors
Hypothesis testing Concepts • Logic of Test of Hypothesis is based on the selected probability, (significance level) for the test statistic (Z) which determines the range of what would be expected due to chance alone. • Commonly used levels and terminology • "Significant" = 0.05 • "Highly significant" = 0.01
Errors! • Is it possible, when we do a test of hypothesis that we are wrong? • Yes, unfortunately. It is always possible that we are wrong. • Furthermore, there are two types of error that we could make!
“H subzero” or “Hnaught” “H sub-a” Stating a Hypothesis A null hypothesis H0is a statistical hypothesis that contains a statement of equality such as , =, or . A alternative hypothesis Hais the complement of the null hypothesis. It is a statement that must be true if H0 is false and contains a statement of inequality such as >, , or <.
Condition of equality Complement of the null hypothesis Stating a Hypothesis Example: A manufacturer claims that its rechargeable batteries have an average life of at least 1,000 charges. 1000 H0: Ha: 1000 (Claim) < 1000
Types of Errors No matter which hypothesis represents the claim, always begin the hypothesis test assuming that the null hypothesis is true. At the end of the test, one of two decisions will be made: 1. reject the null hypothesis, or 2. fail to reject the null hypothesis. A type I error occurs if the null hypothesis is rejected when it is true. A type II error occurs if the null hypothesis is not rejected when it is false.
Actual Truth of H0 Decision H0 is true H0 is false Do not reject H0 Correct Decision Type II Error Reject H0 Type I Error Correct Decision Types of Errors
Type I Error • Type I error is the REJECTION of a true Null Hypothesis. • This type of error is also called (alpha) error. • This is the value we choose as the "level of significance" • So we actually set the probability of making this type of error. • The probability of a type I error =
Type II error is the FAILURE TO REJECT of a Null Hypothesis that is false. • This type of error is also called (beta) error. • We do not set this value, but we call the probability of a type II error = • Furthermore, in practice we will never know this value. This is another reason we cannot "accept" the null hypothesis, because it is possible that we are wrong and we cannot state the probability of this type of error. Type II Error
So what can we do? • The good news, it is only possible to make one error at a time. • If you reject H0, then maybe you made a type I error, but you have not made a type II error. • If you fail to reject H0, then maybe you made a type II error, but you have not made a type I error.
The probability of Type II Error • This is a probability that we will not know. This probability is called • However, we can do several things to make the error smaller. So this will be our objective. • First, let's look at how these errors occur.
10 12 14 16 18 20 22 24 26 -4 -3 -2 -1 0 1 2 3 4 Type II Error • Examine an hypothesized distribution (below) that we believe to have a mean of 18.
10 12 14 16 18 20 22 24 26 -4 -3 -2 -1 0 1 2 3 4 Type II Error • We are going to do a 2 tailed test with an value of 0.05. Our critical limits will be ±1.96.
12 14 16 18 20 22 24 26 -4 -3 -2 -1 0 1 2 3 4 Type II Error • So we will reject any test statistic over 1.96 (or under -1.96). But lets suppose the null hypothesis is false!!! Lets suppose that the alternate hypothesis is true. Then the hypothesized distribution is not real, there is another "real" distribution that we are sampling from. What might it look like? 10
10 12 14 16 18 20 22 24 26 27 28 • Here is the real distribution. It actually has a mean of 22, but we don't know that. If we did, we would not have hypothesized a mean of 18! Type II Error
10 10 12 12 14 14 16 16 18 18 20 20 22 22 24 24 26 26 27 28 -4 -3 -2 -1 0 1 2 3 4 • So where on the real distribution is our critical limit. This is the key question. Type II Error Critical value
10 10 12 12 14 14 16 16 18 18 20 20 22 22 24 24 26 26 27 28 -4 -3 -2 -1 0 1 2 3 4 • Now we draw our sample from the real distribution. If our result says reject the H0, we make no error. Type II Error Critical value
10 10 12 12 14 14 16 16 18 18 20 20 22 22 24 24 26 26 27 28 -4 -3 -2 -1 0 1 2 3 4 • But if our result causes us to fail to reject, we err. Type II Error Critical value
10 12 14 16 18 20 22 24 26 27 28 • And in this case it appears we have pretty close to a 50-50 chance of going either way. Type II Error Critical value
10 12 14 16 18 20 22 24 26 27 28 • So we take our sample and do our test. Will we err? Maybe, and maybe not. If our sample happens to fall in the red area, we will not reject H0. • We would err. Type II Error
10 12 14 16 18 20 22 24 26 27 28 • But if our sample happens to fall in the yellow area, we will reject H0. • No error, we draw the correct conclusion. Type II Error
For = 0.05, our critical limit would be 1.96. • The critical limit translates to a value on the original scale of Yi = + Zi = 18 + 1.96(2) = 18 ± 3.92. The lower bound is 14.08 and the upper bound is 21.92. The lower bound is so far down on the real distribution that the probability of getting a sample that falls there is near zero. The upper bound is the one that falls in the middle of the "real" distribution. Probability of error
Probability of error (continued) • In this ficticious case we know that the true mean is 22 (we wouldn't normally know the true mean. • Since we know the true mean, we can calculate the probability of drawing a sample above and below the critical limit (21.92 on the Y scale, 0.04 on the Z scale of the real distribution).
Probability of error (continued) • The probability of falling below this value, and of making a type II error is 0.484, or about 48.4%. This is beta () • The probability of falling above this value, and of NOT making a type II error is 0.516, or 51.6%. • So in this case we can calculate , the probability of a Type II error. In practice we cannot usually know these.
Type II Error Probability • Since we don't actually know what the true mean is (or we wouldn't be hypothesizing something else), we cannot know in practice the type II error rate (). However, it is affected by a number of things, and we can know about these. • We define a new term POWER, this is the probability of NOT making a type II error (=1-). This was 0.516 in our example.
First, power is effected by the distance between the hypothesized mean () and true mean (). Power and Type II Error
10 10 12 12 14 14 16 16 18 18 20 20 22 22 24 24 26 26 27 28 -4 -3 -2 -1 0 1 2 3 4 10 10 12 12 14 14 16 16 18 18 20 20 22 22 24 24 26 26 27 28 -4 -3 -2 -1 0 1 2 3 4 • Second, power is effected by the value chosen for Type I error (). Power and Type II Error
10 12 14 16 18 20 22 24 26 27 28 10 12 14 16 18 20 22 24 26 27 28 • And third, power is effected by the variability or spread of the distribution. Power and Type II Error
Which of the 3 factors influencing power can you control? • For testing means you may be able to control sample size (n). This reduces the variability and increases power. • You probably cannot influence the difference between and . • You can choose any value of . However, this cannot be too small or Type II error becomes more likely. Too large and Type I error becomes likely. Controlling Power
Summary • Hypothesis testing is prone to two types of errors, one we control () and one we do not (). • Type I error is the REJECTION of a true Null Hypothesis. • Type II error is the FAILURE TO REJECT a Null Hypothesis that is false. • Not only do we not control TYPE II error, we probably do not even know its value.
Summary (continued) • The "Power" of a test is 1 = • We can influence power, and hopefully reduce it, by • Controlling the distance between and (not really likely) • Selecting a value of that is not too small (0.05 and 0.01 are the usual values) • Getting a larger sample size, usually the factor most under the control of the investigator.