Download

1 / 54
540 likes | 696 Views
A Look at Means, Variances, Standard Deviations, and z -Scores. Dr. Margie Mason College of William and Mary mmmaso@wm.edu. Based on the Technical Assistance Document 2009 Algebra I Standard of Learning A.9.

E N D
A Look at Means, Variances, Standard Deviations, and z-Scores Dr. Margie Mason College of William and Mary mmmaso@wm.edu
Based on theTechnical Assistance Document2009 Algebra I Standard of Learning A.9 http://www.doe.virginia.gov/instruction/high_school/mathematics/technical_assistance_algebra1_a9.pdf
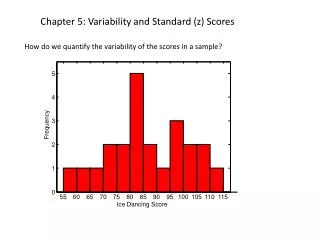
Algebra Standard of Learning A.9 The student, given a set of data, will interpret variation in real-world contexts and calculate and interpret mean absolute deviation, standard deviation, and z-scores.
Mathematics SOL 5.16 5.16 The student will a) describe mean, median, and mode as measures of center; b) describe mean as fair share; c) find the mean, median, mode, and range of a set of data; and d) describe the range of a set of data as a measure of variation.
Algebra SOL A.10 The student will compare and contrast multiple univariate data sets, using box-and-whisker plots.
Algebra SOL A.10 Let’s use unifix stick heights of 5 6 8 8 10 13 15 17 18 20
Determining a Box-and-Whisker Plot Find: Median – the middle value when arranged from smallest to largest. 11.5 Lower extreme (LE) – the smallest value 5 Upper extreme (UE) – the largest value 20 Lower quartile (LQ) – the value halfway between the lower extreme and the median. 8 Upper quartile (UQ) – the value halfway between the upper extreme and the median. 17 Interquartile range (IQR) – The difference between the upper quartile and the lower quartile. 9
Determining a Box-and-Whisker Plot Determine and draw the scale. Subtract the smallest value from the largest value to determine the range. Choose a reasonable size for the intervals based on the range to be covered, e.g., 1, 2, 5, or 10. Draw the scale much like a number line at the bottom of your plot.
Determining a Box-and-Whisker Plot 3. Draw the box: a. Length of the box extends for LQ to UQ. It is drawn above the scale. b. Mark the median. c. Width of box can be anything.
Determining a Box-and-Whisker Plot 4. Draw the whiskers: a. Draw from the box you just drew to LE and UE.
Determining a Box-and-Whisker Plot Alternate method for drawing the whiskers: 4. Determine the outliers: Multiply the IQR by 1.5 and add this number to the UQ and subtract it from the LQ. Any values outside these limits are outliers.
Determining a Box-and-Whisker Plot Alternate Method: 5. Draw whiskers: a. Draw from box to LE and UE excluding outliers. b. Place asterisks on any outliers.
Determining a Box-and-Whisker Plot How many years of experience as a teacher do you have?
Mathematics SOL 6.15 The student will a) describe mean as balance point; and b) decide which measure of center is appropriate for a given purpose.
Mathematics SOL 6.15 The mean is the numerical average of the data set and is found by adding the numbers in the data set together and dividing the sum by the number of data pieces in the set. In grade 5 mathematics, mean is defined as fair-share.
Mathematics SOL 6.15 Mean can be defined as the point on a number line where the data distribution is balanced. This means that the sum of the distances from the mean of all the points above the mean is equal to the sum of the distances of all the data points below the mean. This is the concept of mean as the balance point. Defining mean as balance point is a prerequisite for understanding standard deviation.
Mathematics SOL 6.15 Balance Point: The sum of the distances on a number line from the mean of all the points above the mean is equal to the sum of the distances of all the data points below the mean. 7 + 6 + 4 + 4 + 2 = 1 + 3 + 5 + 6 + 8
Sample vs. Population Data A statistical population includes all elements in the set. A sample is a subset of the population. A data set, whether a sample or population, is comprised of individual data points referred to as elements of the data set. Start with small defined population data sets of approximately 30 items or less.
*Elements* An element of a data set will be represented as xi. Where i represents the ith term of the data set.
Sample vs. Population Data The arithmetic mean of a population is represented by the Greek letter (mu), while the calculated arithmetic mean of a sample is represented by , read “x bar.”
Mean Absolute Deviation vs. Variance and Standard Deviation Measuring dispersion or spread of a data set about the mean One measure of spread is to find the sum of the deviations between each element and the mean; however, this sum is always zero.
Mean Absolute Deviation vs. Variance and Standard Deviation Two methods: take the absolute value of the deviations before finding the average, (Mean Absolute Deviation) or square the deviations before find the average (Variance and Standard Deviation)
Mean Absolute Deviation vs. Variance and Standard Deviation Summation Notation
Mean Absolute Deviation The arithmetic mean of the absolute values of the deviations of elements from the mean of a data set. 5 6 8 8 10 13 15 17 18 20 |5-12| + |6-12| + |8-12| + |8-12| +|10-12| + |13-12| + |15-12| +|17-12| + |18-12| + |20-12| 10 = 7 + 6 + 4 + 4 + 2 + 1 + 3 + 5 + 6 + 8 10 = 46 10 = 4.6
*Mean Absolute Deviation* Mean absolute deviation = where represents the mean of the data set, n represents the number of elements in the data set, and xi represents the ith element of the data set.
Mean Absolute Deviation Mean absolute deviation is less affected by outlier data than the variance and standard deviation. Outliers are elements that fall at least 1.5 times the interquartile range (IQR) below the first quartile (Q1) or above the third quartile (Q3).
Variance The average of the squared deviations from the mean is known as the variance and is another measure of the spread of the elements in the set. (5-12)2 + (6-12)2 + (8-12)2 + (8-12)2 +(10-12)2 + (13-12)2 + (15-12)2 +(17-12)2 + (18-12)2 + (20-12)2 10 = (-7)2 + (-6) 2 + (-4) 2 + (-4) 2 + (-2) 2 + 12 + 32 + 52 + 62 + 82 10 = 49 + 36 + 16 + 16 + 4 + 1 + 9 + 25 + 36 + 64 = 256 = 25.6 10 10
*Variance* Variance (s 2)= where represents the mean of the data set, n represents number of elements in the data set, and xi represents the ith element of the data set.
Variance The differences are squares so that they don’t cancel each other out when finding the sum. When squaring the differences, the units of measure are squared and the larger differences are “weighted” more heavily than smaller differences. In order to provide a measure of variation in terms of the original units of the date, the square root of the variance is taken, yielding the standard deviation.
Standard Deviation The positive square root of the variance of the data set. The greater the value, the more spread out the data are about the mean. The lesser (closer to 0) the value, the closer the data are clustered about the mean.
*Standard Deviation* Standard deviation (s)= where represents the mean of the data set, n represents the number of elements in the data set, and xi represents the ith element of the data set.
Standard Deviation “ ”, written and read “sigma”, represents the standard deviation of a population and “s” represents the sample standard deviation. s = the square root of 25.6 = 5.06
Standard Deviation The population standard deviation can be estimated by calculating the sample standard deviation. The formulas for sample and population look similar except that the sample standard deviation formula uses n – 1 instead of n in the denominator. This is to account for the possibility of greater variability of data in the population than what was seen in the sample.
Standard Deviation When n-1 is used in the denominator, the result is a larger number. So the calculated value of the sample standard deviation will be larger than the population standard deviation. As sample sizes get larger, the difference gets smaller. The use of n-1 is known as Bessel’s correction. SOL A.9 used the population standard deviation with n in the denominator.
Interpreting Standard Deviation Standard deviation is a measure of the typical amount an entry deviates from the mean. The more the entries are spread out, the greater the standard deviation.
Interpreting Standard DeviationEmpirical Rule (68 -95-99.7 Rule) For data with a (symmetric) bell-shaped distribution, the standard deviation has the following characteristics: About68%of the data lie within one standard deviation of the mean. About95%of the data lie within two standard deviations of the mean. About99.7%of the data lie within three standard deviations of the mean.
99.7% within 3 standard deviations 95% within 2 standard deviations Empirical Rule (68 – 95 – 99.7 Rule) 68% within 1 standard deviation 34% 34% 2.35% 2.35% 13.5% 13.5%
Example: Using the Empirical Rule In a survey conducted by the National Center for Health Statistics, the sample mean height of women in the United States (ages 20-29) was 64.3 inches, with a sample standard deviation of 2.62 inches. Estimate the percent of the women whose heights are between 59.06 inches and 64.3 inches.
Example: Using the Empirical Rule Because the distribution is bell-shaped, you can use the Empirical Rule. 34% + 13.5% = 47.5% of women are between 59.06 and 64.3 inches tall.
Chebychev’s Theorem The portion of any data set lying within k standard deviations (k > 1) of the mean is at least: k = 2: In any data set, at least of the data lie within 2 standard deviations of the mean. k = 3: In any data set, at least of the data lie within 3 standard deviations of the mean.
Using Chebychev’s Theorem The age distribution for Florida is shown in the histogram. Apply Chebychev’s Theorem to the data using k = 2. What can you conclude?
Using Chebychev’s Theorem k = 2: μ – 2σ = 39.2 – 2(24.8) = – 10.4 (use 0 since age can’t be negative) μ+ 2σ = 39.2 + 2(24.8) = 88.8 At least 75% of the population of Florida is between 0 and 88.8 years old.
z-Scores A z-score, also called a standard score, is a measure of the position derived from the mean and standard deviation of the data set. In Algebra I, the z-score will be used to determine how many standard deviations an element is above of below the mean of the data set. It can also be used to determine the value of the element, given the z-score of an unknown element and the mean and standard deviation of a data set.
The Standard Score (z-Score) Represents the number of standard deviations a given value x falls from the mean μ.
z-Scores The z-score will be positive if the element lies above the mean and negative if it lies below the mean. A z-score is calculated by subtracting the mean of the data set from the element and dividing the result by the standard deviation of the data set.
*z-Scores* z-score (z) = where x represents an element of the data set, m represents the mean of the data set, and s represents the standard deviation of the data set.
z-Scores z-score of 5 = (5 - 12)/5.06 = -1.38 z-score of 6 = (6 - 12)/5.06 = -1.19 z-score of 8 = (8 - 12)/5.06 = -.79 z-score of 10 = (10 - 12)/5.06 = -.40 z-score of 13 = (13 - 12)/5.06 = .20 z-score of 15 = (15 - 12)/5.06 = .59 z-score of 17 = (17 - 12)/5.06 = .99 z-score of 18 = (18 - 12)/5.06 = 1.19 z-score of 20 = (20 - 12)/5.06 = 1.58
z-Scores Suppose you had the misfortune to have an Algebra test and a history test on the same day. Why you got your tests back, here is the information given to you regarding your performance and the performance of the class on these exams. Which test did you do better on? Algebra History Your score 82 93 Mean 71.06 85.43 Stan. Dev 10.32 18.91
z-Scores Suppose the mean and standard deviation on an algebra test were given as 72 and 12, respectively. Susan’s z-score on the test was 2.34. Was Susan’s test score above or below the mean? How do you know? David’s z-score on the same test was -1.25. Was David’s test score above or below the mean? How do you know?
z-Scores Suppose the mean and standard deviation on an algebra test were given as 72 and 12, respectively. Dakota had a z-score of 0.08 on the test. What does this z-score tell you about Dakota’s test score relative to the mean?