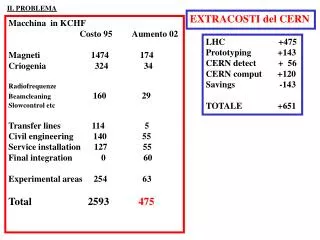
Download
1 / 10
100 likes | 226 Views
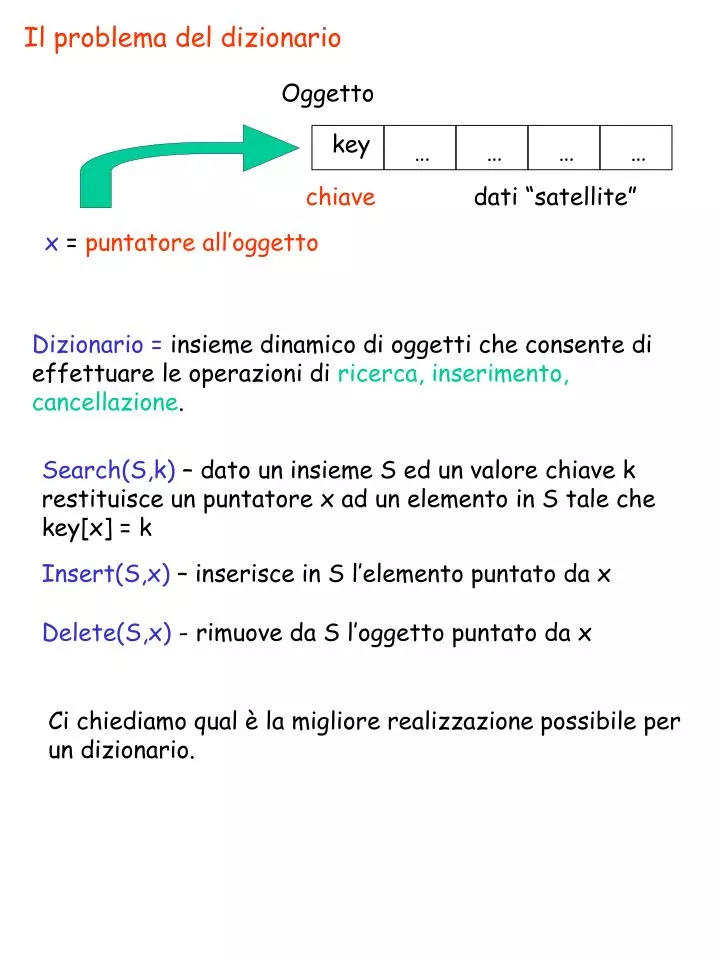
Il problema del dizionario. Oggetto. key. …. …. …. …. chiave. dati “satellite”. x = puntatore all’oggetto. Dizionario = insieme dinamico di oggetti che consente di effettuare le operazioni di ricerca, inserimento, cancellazione.

E N D
Il problema del dizionario Oggetto key … … … … chiave dati “satellite” x = puntatore all’oggetto Dizionario = insieme dinamico di oggetti che consente di effettuare le operazioni di ricerca, inserimento, cancellazione. Search(S,k) – dato un insieme S ed un valore chiave k restituisce un puntatore x ad un elemento in S tale che key[x] = k Insert(S,x) – inserisce in S l’elemento puntato da x Delete(S,x) - rimuove da S l’oggetto puntato da x Ci chiediamo qual è la migliore realizzazione possibile per un dizionario.
Esempio Dizionario per la gestione del corso di algoritmi Nome Voto Parziale (chiave) (dati satellite) Bravino 23 Lasfanga 21 Svogliatelli 15 Secchioni 30 Modesto 9 … Metodo più semplice array non ordinato In questo caso: Insert costa O(1) - inserisco dopo Modesto Search costa O(n) – devo scorrere la tabella Delete costa O(n) - delete = search + trasferimento
Possiamo ridurre il tempo di esecuzione della operazione di ricerca? Il problema della ricerca di un elemento in un array non ordinato ha delimitazione inferiore (n) INFATTI Ogni algoritmo deve, nel caso peggiore, guardare tutti gli elementi dell’insieme per accertarsi o meno della presenza dell’elemento cercato. L’operazione di ricerca costa meno in un array ordinato. Posso usare il metodo di ricerca per dimezzamenti successivi
La ricerca per dimezzamenti successivi ha un costo O(log(n)). Posso fare meglio? • NO! • Ognialgoritmo per la ricerca di un elemento in un insieme di n elementi richiede (log(n)) confronti. • Infatti: • - Ogni algoritmo deve restituire la posizione dell’elemento tra le n possibili; • Ad ogni algoritmo posso associare un albero di decisione; • L’albero di decisione deve avere n foglie; • L’altezza dell’albero fornisce un lower bound alla complessità di un generico algoritmo; • Il numero di foglie di un albero di altezza h è al più 2h • Quindi: • n < 2h h > log2(n) • Per un generico algoritmo T(n) = ( log2(n)) Il metodo di ricerca per dimezzamenti successivi è ottimale.
RICAPITOLANDO: gestione “banale” del dizionario Array Ordinato Search – O(log(n)) Insert – O(n) Ho bisogno di: O(log(n)) confronti per trovare la giusta posizione in cui inserire l’elemento O(n) trasferimenti per mantenere l’array ordinato (Ricorda che O(n) + O(log(n)) = O(n)) Delete - O(n) (come per Insert) Array non Ordinato Search – O(n) Insert – O(1) Delete - O(n) Lista non Ordinata Search – O(n) Insert – O(1) Delete - O(n) Lista Ordinata Search – O(n) Costerebbe comunque n (non posso fare dim. successivi) Insert – O(n) Devo mantenere ordinata la lista Delete - O(n)
Alberi binari di ricerca (ABR) Nodo key p left right chiave x = puntatore al nodo Albero binario insieme di nodi (record) caratterizzato da quattro campi: key[x] (chiave), p[x] (puntatore al padre), left[x] (puntatore al figlio sinistro), right[x] (puntatore al figlio destro). root[T] Puntatore alla radice dell’albero x = puntatore nodo left[x] = NIL (il nodo non ha figlio sinistro) right[x] = NIL (il nodo non ha figlio destro) Un albero binario di ricerca (ABR) è una albero binario in cui le chiavi dei vari nodi soddisfano la seguente proprietà: PROPRIETA’ dell’ABR Sia x un nodo generico di un ABR. Se y è un nodo del sotto-albero sinistro di x allora: key[y] < key[x] Se y è un nodo del sotto-albero destro di x allora: key[y] > key[x]
Alberi binari di ricerca Ordinamento decrescente 15 Ordinamento crescente 6 18 3 7 17 20 massimo 13 2 4 minimo 9
Le proprietà di un ABR determinano un ordinamento totale … massimo minimo Verifichiamo… 15 6 18 3 7 17 20 massimo 13 2 4 minimo 9
Visita di un ABR Visita in ordine simmetrico – dato un nodo x, elenco prima il sotto-albero sinistro di x, poi il nodo x, poi il sotto-albero destro. Inorder-tree-walk(x) If (x NIL) then Inorder-tree-walk(left[x]) stampa key[x] Inorder-tree-walk(right[x]) Verifica di correttezza – Supponiamo,per semplicità, che l’albero sia completo. Indichiamo con h l’altezza dell’albero. Vogliamo mostrare che Inorder-tree-walk(x) restituisce la sequenza ordinata h=1 Successione parametri chiamate root[T] Left[root(T)] right[root(T)] NIL NIL NIL NIL key[left[root[T]]] < key[root[T]] < key[right[root[T]]]
Verifica correttezza (continua …) h = generico (ipotizzo che la procedura sia corretta per h-1) root[T] Left[root(T)] right[root(T)] Albero di altezza h-1. Tutti i suoi elementi sono maggiori o uguali della radice Albero di altezza h-1. Tutti i suoi elementi sono minori o uguali della radice Analisi complessità La complessità della procedura considerata è T(n) = (n). Matematicamente …… T(n) = 2 T(n/2) + c Intuitivamente …… La procedura è chiamata un numero di volte pari al numero di nodi dell’albero (e ad ogni chiamata effettua un numero costante di operazioni).