Download

1 / 1
10 likes | 146 Views
Developing a Concept Extraction Technique with Ensemble Pathway Prat Tanapaisankit (NJIT), Min Song (NJIT), and Edward A. Fox (Virginia Tech). Training Data 1748 tuples 6000 sentences from the Ensemble Pathway and the web as positive examples.

E N D
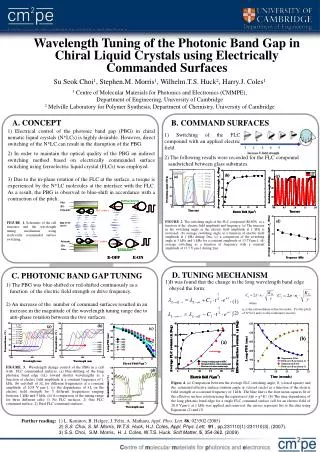
Developing a Concept Extraction Technique with Ensemble Pathway Prat Tanapaisankit (NJIT), Min Song (NJIT), and Edward A. Fox (Virginia Tech) • Training Data • 1748 tuples • 6000 sentences from the Ensemble Pathway and the web as positive examples. • 4000 sentences collected from the web, which are used as negative examples. • Contributions • We apply Conditional Random Fields (CRFs) to concept extraction. • We propose an automatic procedure to build the training data. • We use CEED to apply concept extraction to an educational collection, extending how concept extraction has been applied to digital libraries. • We provide RESTful web services for concept extraction. • AcknowledgmentsPartial support for this research was provided by the National Science Foundation under grants DUE- 0937629 and 0840719, and by the New Jersey Institute of Technology. • Ensemble: • www.computingportal.org • Abstract • In this poster, we describe our Concept Extraction technique for Educational Digital libraries (CEED) which applies Conditional Random Fields (CRFs) to extract concepts from the Ensemble Pathway collection. • Ensemble • NSF NSDL Pathways project working to establish a national, distributed digital library for computing education. • Support the multidisciplinary aspects of computing education communities. • Encourages contribution, use, reuse, review, and evaluation of educational materials of all kinds. • Serves as a computing portal for a collection of information that is distributed in location and in ownership. • 9 content providers and 9 sub-collections. • 9901 articles in its collection at time of study • Harvesting Metadata • We retrieved metadata records from the Ensemble OAI provider at http://figo.cc.vt.edu:8080/fedora3/oai. • We used jOAI, which is a Java-based open source Open Archives Initiative (OAI) data provider and harvester tool developed by Digital Learning Sciences (DLS). • The repository site is OAI-compliant according to the OAI Implementation Guidelines, so other harvesting tools that conform to the OAI-PMH protocol can be employed as well. • Indexing Metadata • We indexed the Ensemble Pathway collections with our tool, QICs. After indexing we have found that the collection contains a good number of metadata records although the majority of them do not provide an abstract (description). The Ensemble Pathway served a total of 9901 educational resources at the time of the study. An example of input and output Overall Data Flow of CEED Positive Example The computer uses a modem to access the Web. Negative Example Test Data (Sentence) Trained Model Concept Tuple Index List of Tags CEED CEED (Concept Extraction technique for Education Digital library) The <general>computer</general> uses a <hardware>modem </hardware> to access the <computer-communication-networks>Web<computer-communication-networks>. Sentence With Concept Tags Training Data • System Description • CEED is a CRFs-based concept extraction technique. Its core engine is a CRFs-based tagger which takes a sentence as an input and returns the sentence along with a concept tag for important terms. • The system has 28 tags used for different important terms. Before performing the extraction task, CEED needs to be properly trained to build a model. • Concept Tuple • The format of a tuple is denoted as follows: • (Computing concept, description, class) • For example • (Algorithm, Model of computation and algorithm, Theory of Computation) • Computing concepts are taken from “The Free On-line Dictionary of Computing” (http://foldoc.org/). • Classes based on the ACM Classification are assigned to each concept manually. • Description provides more information of a class.