Download
1 / 19
190 likes | 202 Views
Learn about hash table concepts, efficient lookup, insertion techniques, extensible hashing, linear hashing, and dynamic hashing frameworks. Explore examples and advantages of extensible hash tables and common defects. Understand linear hashing and its implementation for efficient record management.

E N D
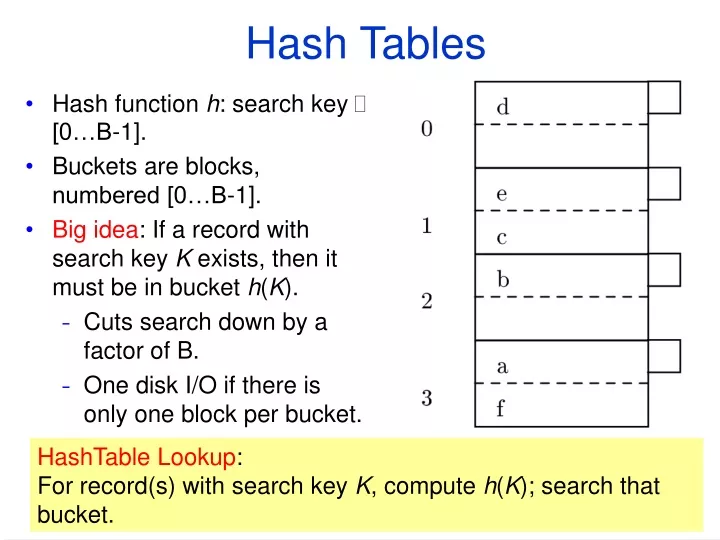
Hash Tables • Hash function h: search key [0…B-1]. • Buckets are blocks, numbered [0…B-1]. • Big idea: If a record with search key K exists, then it must be in bucket h(K). • Cuts search down by a factor of B. • One disk I/O if there is only one block per bucket. HashTable Lookup: For record(s) with search key K, compute h(K); search that bucket.
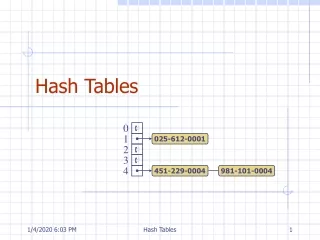
HashTable Insertion • Put in bucket h(K) if it fits; otherwise create an overflow block. • Overflow block(s) are part of bucket. Example: Insert record with search key g.
What if the File Grows too Large? • Efficiency is highest if #records < #buckets #(records/block) • If file grows, we need a dynamic hashing method to maintain the above relationship. • Extensible Hashing: double the number of buckets when needed. • Linear hashing: add one more bucket as appropriate.
Dynamic Hashing Framework • Hash function h produces a sequence of k bits. • Only some of the bits are used at any time to determine placement of keys in buckets. Extensible Hashing (Buckets may share blocks!) • Keep parameter i = number of bits from the beginning of h(K) that determine the bucket. • Bucket array now = pointers to buckets. • A block can serve as several buckets. • For each block, a parameter ji tells how many bits of h(K) determine membership in the block. • I.e., a block represents 2i-j buckets that share the first j bits of their number.
Example • An extensible hash table when i=1:
Extensible Hashtable Insert • If record with key K fits in the block pointed to by h(K), put it there. • If not, let this block B represent j bits. • j<i: • Split block B into two and distribute the records (of B) according to (j+1)st bit; • set j:=j+1; • fix pointers in bucket array, so that entries that formerly pointed to B now point either to B or the new block How? depending on…(j+1)st bit • j=i: • Set i:=i+1; • Double the bucket array, so it has now 2i+1 entries; • proceed as in (1). Letwbe an old array entry. Both the new entries,w0andw1,point to the same block that w used to point to.
Now, after the insertion Before Example • Insert record with h(K) = 1010.
Currently After the insertions Example: Next • Next: records with h(K)=0000; h(K)=0111. • Bucket for 0... gets split, • but i stays at 2. • Then: record with h(K) = 1000. • Overflows bucket for 10... • Raise i to 3.
Extensible Hash Tables: Advantages: • Lookup; never search more than one data block. • Hope that the bucket array fits in main memory Defects: • Substantial amount of work to double the bucket array • Interrupts access to data file • Makes certain insertions appear to take very long • Doubling the bucket array soon is going to make the array to not fit in main memory. • Problem with skewed key distributions. • E.g. Let 1 block=2 records. Suppose that three records have hash values, which happen to be the same in the first 20 bits. • In that case we would have i=20 and and one million bucket-array entries, even though we have only 3 records!!
Linear Hashing • Use i bits from right (loworder) end of h(K). • Buckets numbered [0…n-1], where 2i-1<n2i. • Let last i bits of h(K) be m = (a1,a2,…,ai) • If m < n, then record belongs to bucket m. • If nm<2i, then record belongs in bucket m-2i-1, that is the bucket we would get if we changed a1 (which must be 1) to 0. #of buckets #of records This is also part of the structure
Linear HashTable Insert • Pick an upper limit on capacity, • e.g., 85% (1.7 records/bucket in our example). • If an insertion exceeds capacity limit, set n := n + 1. • If new n is 2i + 1, set i := i + 1. No change in bucket numbers needed --- just imagine a leading 0. • Need to split bucket n - 2i-1 because there is now a bucket numbered (old) n.
i=1 i=1 n=1 0000 0 0 n=1 r=0 r=1 Example • Insert records with h(K) = 0000, 1010, 1111, 0101, 0001, 1100. Before After
i=1 i=1 0000 0000 1 0 0 n=1 n=2 1010 r=1 r=2 Example • Insert records with h(K) = 0000, 1010, 1111, 0101, 0001, 1100. Before After Capacity limit exceeded; increment n
i=1 i=1 0000 1111 0000 1 0 1 0 n=2 n=2 1010 1010 r=3 r=2 Example • Insert records with h(K) = 0000, 1010, 1111, 0101, 0001, 1100. Before After
i=2 i=1 1111 0000 0000 1010 00 1 10 0 n=3 n=2 1010 1111 01 r=4 r=3 0101 Example • Insert records with h(K) = 0000, 1010, 1111, 0101, 0001, 1100. Before After Capacity limit exceeded; increment n, which causes incrementing i as well.
i=2 i=2 1010 0000 1010 0000 10 00 10 00 n=3 n=3 1111 1111 01 01 r=4 r=5 0101 0101 0001 Example • Insert records with h(K) = 0000, 1010, 1111, 0101, 0001, 1100. Before After As long as capacity is not exceeded can add overflow blocks.
0000 00 i=2 i=2 1111 0000 1010 1010 1100 11 00 10 10 n=3 n=4 1111 0001 01 01 r=5 r=6 0101 0101 0001 Example • Insert records with h(K) = 0000, 1010, 1111, 0101, 0001, 1100. Before After Capacity limit exceeded; increment n.
Lookup in Linear Hash Table • For record(s) with search key K, compute h(K); search the corresponding bucket according to the procedure described for insertion. • If the record we wish to look up isn’t there, it can’t be anywhere else. • E.g. lookup for a key which hashes to 1010, and then for a key which hashes to 1011. i=2 n=3 r=4
Exercise • Suppose we want to insert keys with hash values: 0000…1111 in a linear hash table with 100% capacity threshold. • Assume that a block can hold three records.