Download

1 / 24
240 likes | 408 Views
Building a dictionary for genomes. By Harmen J. Bussemaker, Hao Li, and Eric D. Siggia. Tal Frank. Topics that will be discussed. Biological background Present the biological problem Show an algorithm that treats this problem statistical mechanics methods

E N D
Building a dictionary for genomes By Harmen J. Bussemaker, Hao Li, and Eric D. Siggia Tal Frank
Topics that will be discussed Biological background Present the biological problem Show an algorithm that treats this problem statistical mechanics methods Try our algorithm on two well known problems
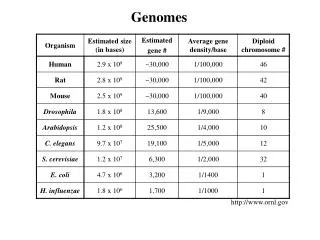
What we did so far Human Genome Project(2001) This article published(2000) :Sequence is not everything - Lets do some theory Control over gene expression - when, how much Control element = Regulator = Sequence motif Genes are working together = Co-regulated genes
The goals of this work Identify the Control element Where are they located ? Identify co-regulated genes
Multiple control elements Example : where are the control elements located? Concepts: directionality , upstream ,in the junk TACGAXTTCGA Example: co-regulated genes naïve approach :TACGAXTTTAAYATGGCA experimentally :TACGAXTTCGAYATGGCA To activate set of genes: multiple sequences needed
New terminology DNA = string of letters Control element = word Multiple control element = sentences Genes and junk = background noise Example : S: …GAGCXTGGYGCTT…… words = {GA,TG} sentence = GA.TG background = genes and junk.
MobyDick algorithm decipher a ‘‘text’’ consisting of a long string of letters written in an unknown language. Find the words in the text Find the right spacing example : D={A,T,AT} S=ATT P1=A.T.T P2=AT.T
How would you do it ? 1.Look for repeated substring in the string : {went, to, he} D (dictionary) 2.Space the text – ooopps Spacing is not that simple. e.g.– D={A,T,AT} S=ATT P1=A.T.T p1 P2=AT.T p2 Tal wentto Weizmann this morning. When he arrived he didn’t go to his office, hewentto drink a cup of coffee ….
MobyDick Blueprints 1 letter word S=TAGATAT D={T,A,G} Find pw pw ={pA,pT..} 2 letter word S=TAGATAT D={A,TA,…} Find pw pw ={pA,pTA.} No more optional words stop! Find spacing S=TA.G.A.TA.T
statistical mechanics in order to ? 1.How does MobyDick decide {pw}? 2.When does MobyDick add a new word? 3.Space (parse) the text.
The likelihood function k: a possible spacing Nw: number of times the word w appears Example : D=(T,AT,A) S=TATA k1=T.A.T.A k2=T.AT.A
Likelihood function - intuition Z(D,{pw})- partition function: <E>,<N>,<T>,…. Z(D,{pw})- the probability to obtain a sequence S. Example : D =(T,AT,A) {pT,pA,pAT} Question : what is the probability to S=TATA? 1st possibility : T.A.T.A pA*pA*pT*pT 2nd possibility: T.AT.A pT*pAT*pA
Finding {pw} Given : D,S Maximize Z({pw},D) with respect to {pw} This {pw} gives the highest probability to get the given S
Lets find the {pw} ! Definition : - average number of the word w over the different spacings . Can prove: maximize Z- solve: solving : is done by iteration: pw’ <Nw’> pw
Enough is enough !!! When is pw good enough ? when the new {pw} don’t give higher Z We say : this method converges ! Other methods don’t converge.
Why finding {pw} using this way ? Monte-Carlo methods don’t converge. Slow method can transform to fast method Order of complexity O(LDl) L-the length of the string D-the size of the dictionary l-the length of the longest word in D
Add new words ? Look at dictionary D={T,A,C,G} S=TATTGA Compose new word ww’ D={T,A,C,G} S=TATTGA ww’=TA Check occurrence D={T,A,C,G} S=TATTGA ww’=TA D={T,A,C,G,TA} S=TATTGA Yes- add to dictionary
A problem and a bad solution The algorithm finds only the words which are composed from words already in the dictionary. Example : S=AATATAAA 1st step : S=AATATAAA D= {A} 2nd step : S=AATATAAA AT is not a composition of words Solution: Look for repeated long strings by consideration the problem
Spacing Define : number of times the word w occurs in a given spacing. Quality factor : The required condition :
checking the algorithm Applying on the English novel Moby Dick Applying on Control elements on the yeast genome Not always possible - Voynich manuscript (1450)
Preparing the book MobyDick Call me Ishmael. Some years ago- never mind how long precisely- having little or no money in my purse, and nothing particular tothought I would sail … CallmeIshmaelSomeyearsagonevermindhowlongpreciselyhavingli ttleornomoneyinmypurseandnothingparticulartothoughtIwouldsail.. CallabajameIshmaelbjklmbbSomeyearsagonevermindhowlon Eciselyhavinglittlermsdrornomoneyinmypurseandnothingparticu artothoughtIwouldsail …
Results- MobyDick 10 first chapters D={a,b,c….} Text : 4,214 unique words 2,630 occurred only once Background – increases L by the factor of 3. 2,450 words found , 700 in English, 40 composite words.
Results- yeast D={T,A,C,G} Text : 443 experimentally determined sites Background – genes and junk 500 words found 114 match the experimentally predictions Not that good – it is a beginning!