Download

1 / 64
640 likes | 719 Views
Explore the application of Hidden Markov Model, Support Vector Machine, and string kernels in protein structure prediction and analysis. Learn about protein ranking, structural classification, secondary structure prediction, and domain segmentation.

E N D
Machine Learning in the Study of Protein Structure Rui Kuang Columbia University Candidacy Exam Talk May 5th, 2004 Committee: Christina S. Leslie (advisor), Yoav Freund, Tony Jebara
Table of contents • Introduction to protein structure and its prediction • HMM, SVM and string kernels • Machine learning in the study of protein structure • Protein ranking • Protein structural classification • Protein secondary structural and conformational state prediction • Protein domain segmentation • Conclusion and Future work
Introduction • HMM, SVM and string kernels • Topics • Conclusion and future work Part 1: Introduction to Protein Structure and Its Prediction Thanks to Carl-Ivar Branden and John Tooze
Why study protein structure • Protein– Derived from Greek word proteios meaning “of the first rank” in 1838 by Jöns J. Berzelius • Crucial in all biological processes • Function depends on structure structure can help us to understand function
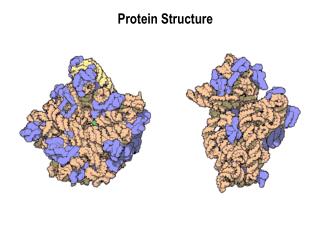
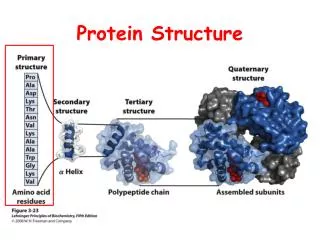
How to Describe Protein Structure • Primary structure: amino acid sequence • Secondary structure: local structure elements • Tertiary structure: packing and arrangement of secondary structure, also called domain • Quaternary structure: arrangement of several polypeptide chains
Secondary Structure : Alpha Helix hydrogen bonds between C’=O at position n and N-H at position n+i (i=3,4,5)
Secondary Structure : Beta Sheet Antiparallel Beta Sheet Parallel Beta Sheet We can also have a mix of both.
Secondary Structure : Loop Regions • Less conserved structure • Insertions and deletions are more often • Conformations are flexible
Tertiary Structure Phi – N - bond Psi – -C’ bond
Protein Domains • A polypeptide chain or a part of a polypeptide chain that can fold independently into a stable tertiary structure.
Determination of Protein Structures • Experimental determination (time consuming and expensive) • X-ray crystallography • Nuclear magnetic resonance (NMR) • Computational determination [Schonbrun 2002 (B2)] • Comparative modeling • Fold recognition ('threading') • Ab initio structure prediction (‘de novo’)
Sequence, Structure and Function [Domingues 2000 (B1)] Sequence (1,000,000) • >30% sequence similarity suggests strong structure similarity • Remote homologous proteins can also share similar structure Structure (24,000): discrete groups of folds with unclear boundaries • Function associated with different structures • Super-family with the same fold can evolve into distinct functions. • 66% of proteins having similar fold also have a similar function Function (Ill-defined) Picture due to Michal Linial
Introduction • HMM, SVM and string kernels • Topics • Conclusion and future work Part 2: Hidden Markov Model, Support Vector Machine and String Kernels K( , ) Thanks to Nello Cristianini
Hidden Markov Models for Modeling Protein [Krogh 1993(B3)] Alignment Maximum Likelihood Or Maximum a posteriori HMM If we don’t know the alignment, use EM to train HMM.
Hidden Markov Models for Modeling Protein [Krogh 1993(B3)] • Probability of sequence x through path q • Viterbi algorithm for finding the best path • Can be used for sequence clustering, database search…
Support Vector Machine [Burges 1998(B4)] • Relate to structural risk minimization • Linear-separable case • Primal qp problem Minimize subject to • Dual convex problem Minimize subject to &
Support Vector Machine [Burges 1998(B4)] • Kernel: one nice property of dual qp problem is that it only involves the inner product between feature vectors, we can define a kernel function to compute it more efficiently • Example:
String Kernels for Text Classification [Lodhi 2002(M2)] • String subsequence kernel –SSK : • A recursive computation of SSK has the complexity of the computation O(n|s||t|). It is quadratic in terms of the length of input sequences. Not practical.
Introduction • HMM, SVM and string kernels • Topics • Conclusion and future work Part 3 Machine learning in the study of protein structure 3.1 Protein ranking 3.2 Protein structural classification 3.3 Protein secondary structure and conformational state prediction 3.4 Protein domain segmentation
Smith-Waterman • SAM-T98 • BLAST/PSI-BLAST • Rank Propagation Part 3.1 Protein Ranking Please!!! Stand in order
Local alignment: Smith-Waterman algorithm • For two string x and y, a local alignment with gaps is: • The score is: • Smith-Waterman score: Thanks to Jean Philippe
BLAST [Altschul 1997 (R1)]: a heuristic algorithm for matching DNA/Protein sequences • Idea: True matches are likely to contain a short stretch of identity AKQ KQD QDY DYY YYY… AKQSKQ.. KQDAQD.. QDY .. DYY .. YYY… Protein Database Neighbor mapping AKQDYYYYE… cut Search match substitution score>T Query: ………DYY……………… Target: …ASDDYYQQEYY… Extend match Extend match
PSI-BLAST: Position-specific Iterated BLAST [Altschul 1997 (R1)] • Only extend those double hits within a certain range. • A gapped alignment uses dynamic programming to extend a central pair of aligned residues in both directions. • PSI-BLAST can takes PSSM as input to search database
SAM-T98 [Karplus 1999 (C3)] Iterate 4 rounds NR Protein database Query sequence Blast search Build alignment with hits search Profile/Alignment HMM
Local and Global Consistency [Zhou 2003 (M1)] • Affinity matrix • D is a diagonal matrix of sum of i-th row of W • Iterate • F* is the limit of seuqnce {F(t)}
Rank propagation [Weston 2004 (R2)] • Protein similarity network: • Graph nodes: protein sequences in the database • Directed edges: a exponential function of the PSI-BLAST e-value (destination node as query) • Activation value at each node: the similarity to the query sequnce • Exploit the structure of the protein similarity network
Fisher Kernel • Mismatch Kernel • ISITE Kernel • SVM-Pairwise • EMOTIF Kernel • Cluster Kernels Part 3.2 Protein structural classification Where are my relatives?
SCOP Fold Superfamily Negative Test Set Negative Training Set Family Positive Test Set Positive Training Set SCOP[Murzin 1995 (C1)] Family : Sequence identity > 30% or functions and structures are very similar Superfamily : low sequence similarity but functional features suggest probable common evolutionary origin Common fold : same major secondary structures in the same arrangement with the same topological connections
CATH[Orengo 1997 (C2)] • Class Secondary structure composition and contacts • Architecture Gross arrangement of secondary structure • Topology Similar number and arrange of secondary structure and same connectivity linking • Homologous superfamily • Sequence family
Fisher Kernel [Jaakkola 2000 (C4)] • A HMM (or more than one) is built for each family • Derive feature mapping from the Fisher scores of each sequence given a HMM H1:
SVM-pairwise [Liao 2002 (C5)] • Represent sequence P as a vector of pairwise similarity score with all training sequences • The similarity score could be a Smith-Waterman score or PSI-BLAST e-value.
Mismatch Kernel [ Leslie 2002 (C6)] AKQ KQD QDY DYY YYY… Implementation with suffix tree achieves linear time complexity O(||mkm+1(|x|+|y|)) AKQDYYYYE… AKQ … CKQ AKY … DKQ AAQ ( 0 , … , 1 , … , 1 , … , 1 , … , 1 , … , 0 ) AAQAKQDKQEKQ AKQ
EMOTIF Kernel [Ben-Hur 2003 (C8)] • EMOTIF TRIE built from eBLOCKS [Nevill-manning 1998 (C7)] • EMOTIF feature vector: where is the number of occurrences of the motif m in x
I-SITE Kernel [Hou 2003 (C10)] • Similar to EMOTIF kernel I-SITE kernel encodes protein sequences as a vector of the confidence level against structural motifs in the I-SITES library [Bystroff 1998 (C9)]
Cluster kernels [Weston 2004 (C11)] • Neighborhood Kernels Implicitly average the feature vectors for sequences in the PSI-BLAST neighborhood of input sequence (dependent on the size of the neighborhood and total length of unlabeled sequences) • Bagged Kernels Run bagged k-means to estimate p(x,y), the empirical probability that x and y are in the same cluster. The new kernel is the product of p(x,y) and base kernel K(x,y)
PrISM • HMMSTR • PHD • PSI-PRED Part 3.3: Protein secondary structure and conformational state prediction Can we really do that?
PHD: Profile network from HeiDelberg [Rost 1993 (P1)] Accuracy: 70.8%
PSIPRED [Jones 1999 (P2)] Accuracy: 76.0%
PrISM [Yang 2003 (P3)] Prediction with this conformation library based on sequence and secondary structure similarity, accuracy: 74.6%
HMMSTR [Bystroff 2000 (P4)]: a Hidden Markov Model for Local Sequence-Structure Correlations in Proteins • I-sites motifs are modeled as markov chains and merged into one compact HMM to capture grammatical structure • The HMM can be used for Gene finding, secondary or conformational state prediction, sequence alignment… • Accuray: • secondary structure prediction: 74.5% • Conformational state prediction: 74.0%
Part 3.4: Protein domain segmentation • DOMAINATION • Pfam Database • Multi-experts Cut? where???
DOMAINATION [George 2002 (D1)] • Get a distribution of both the N- and C-termini in PSI-BLAST alignment at each position, potential domain boundaries with Z-score>2 • Acuracy: 50% over 452 multi-domain proteins
Pfam [Sonnhammer 1997 (D2)] • A database of HMMs of domain families • Pfam A: high quality alignments and HMMS built from known domains • Pfam B: domains built from Domainer algorithm from the remaining protein sequences with removal of Pfam-A domains
A multi-expert system from sequence information [Nagarajan 2003 (D3)] Intron Boundaries DNA DATA Seed Sequence blast search Sequence Participation Multiple Alignment Secondary Structure Entropy Neural Network Correlation Contact Profile Physio-Chemical Properties Putative Predictions