Download

1 / 8
130 likes | 474 Views
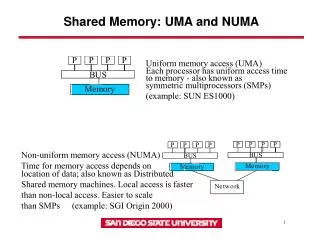
Non-Uniform Memory Access Computers (NUMA). Cache-Coherent NUMA Computers. Scalable machine, like CRAY T3E, disable caching of remote addresses. Every access goes over the network or Programmer responsible to keep copies coherent.

E N D
Cache-Coherent NUMA Computers • Scalable machine, like CRAY T3E, disable caching of remote addresses. • Every access goes over the network or • Programmer responsible to keep copies coherent. • Requirements for implicit caching and coherence on physically distributed memory machines: • Latency and bandwidth scale well • Protocol scales well • In contrast to cache-only memory architectures (COMA), the home location of an address is fixed. • Focus will here be on hardware-based directory-based cache coherence. • A directory is a place where the state of a block in the caches is stored.
Simple Directory-Based Cache Coherence Protocol • Single writer - multiple reader • Cache miss leads to transaction to home of the memory block • Remote node checks state and performs protocol actions • Invalidating copies on write • Returning value on read • All requests, replies, invalidations etc. are network transactions • Questions: • How is the directory information stored? • How may efficient protocols be designed?
Classification of Directory Implementations Directory Storage Schemes Finding source of directory information Centralized Hierarchical Flat Hierarchy of caches with inclusion property. Memory-based Cache-based Information co-located with memory block that is home of that location Caches with a copy form a linked list. Memory holds head pointer only. Locating Copies
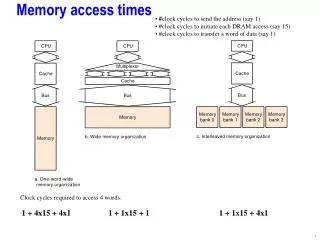
Protocol Scalability • Precondition for application: Small number of sharers • Performance depends on • Number of transactions (bandwidth requirements) • Number of transactions on the critical path (latency) • Storage overhead • It can be quite severe since presence bits scale linearly with memory size and number of processors • Example: Block size 64 byte
Properties of Hierarchical Schemes • Advantages: • Transactions need not go to home • Multiple requests from different nodes can be combined • Disadvantages: • Number of transactions to traverse tree might be greater than in flat schemes. • If startup costs are high, this is worse than traversing long distance • Each transaction needs to look up the directory information which increases latency of transactions. • Summary • Hierarchical schemes are not popular due to latency and bandwidth characteristics. • They have been used in systems providing data migration
Flat Memory-based Directory Schemes • Properties • The number of transactions to invalidate sharers is proportional to the number of sharers. • The invalidation transaction can be overlapped or sent in parallel so that latency is reduced. • The main disadvantage is the memory overhead • Reduction of memory overhead: • Increase cache-line size • Increase number of processors per directory (two-level protocol) • Example: • Four processor nodes and 128 byte cache blocks lead to only 6.25% on a 256 processor system instead of 50%. • Overhead is still proportional to P*M (P is the number of processors and M is memory size)