Download
1 / 44
440 likes | 559 Views
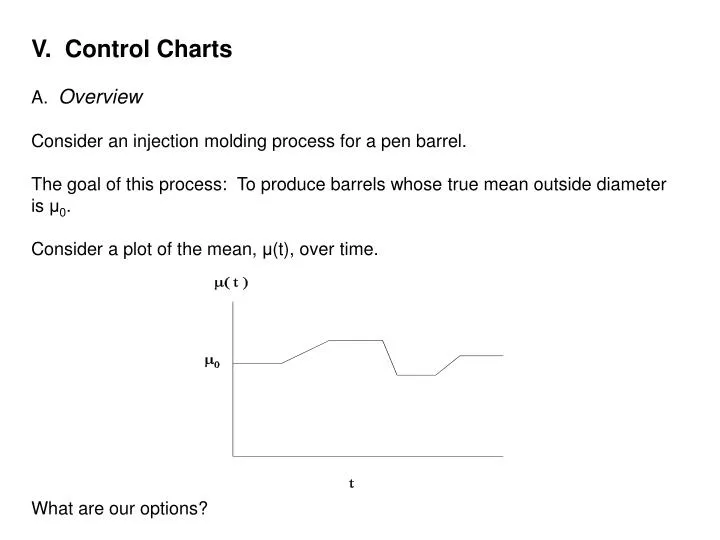
V. Control Charts A. Overview Consider an injection molding process for a pen barrel. The goal of this process: To produce barrels whose true mean outside diameter is μ 0 . Consider a plot of the mean, μ (t), over time. What are our options?. Caveat emptor . “Let the buyer beware.”

E N D
V. Control Charts A. Overview Consider an injection molding process for a pen barrel. The goal of this process: To produce barrels whose true mean outside diameter is μ0. Consider a plot of the mean, μ(t), over time. What are our options?
Caveat emptor. “Let the buyer beware.” • Basic attitude: The customer will buy whatever we make. • Therefore, let the process mean drift! • Let μ(t) wander and perform 100% inspection expansion. • Basic idea: Inspect out the bad barrels. • Problems: • Very expensive in terms of inspector's time. • Lots of wasted barrels. • Even 100% inspection is not 100% effective!
Use a statistical sampling plan. • Basic idea: Use statistics to suggest ways to cut down the inspection costs. • Advantage: Generally cheaper than 100% inspection. • Problems: • Lots of wasted barrels. • Definitely not 100% effective.
Statistical Process Control • Basic idea: Constantly monitor the process; adjust the process once a drift is detected. • Advantage: Stops problems before they become serious. • Drawback: Does not directly deal with the sources of problems. • Create processes which do not produce unacceptable product. • Basic idea: Identify sources of problems; set up safeguards to prevent their occurrence. • Primary statistical tool: Experimental Designs (Chapter 7)
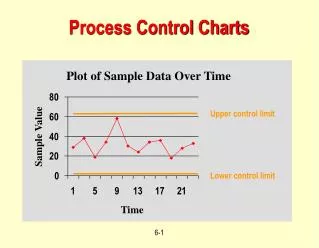
Consider monitoring a process. Recall, our goal is to keep μ(t) at some target value, μ0. Note: μ0 may or may not be the “ideal” value for our characteristic of interest. The first goal in any quality improvement program is to get the process stable. Only after the process is stable, can we begin to move μ0 to its “ideal” value. When μ(t) = μ0, we say that the process is in control. The process is assumed to remain in control until acted upon by an assignable cause. The assignable cause shifts μ(t) to some other value μ1 and the process is said to be out of control.
Our goal, then, is to develop a method for monitoring μ(t). Problem: Do we ever see μ(t)? No, but we do see estimates of μ(t)! Therefore, what should we do? Assume that we are concerned with the mean of the characteristic of interest, and that the characteristics variance is known. What seems reasonable?
Step 1: Take samples at regular intervals. Step 2: Perform hypothesis tests of the form H0: μ = μ0 process is in control H1: μ ≠ μ0 process is out of control Step 3: The appropriate test statistic Step 4: The critical region We reject if H0 What does this critical region mean?
We conclude the process is out of control if Equivalently, we act as if the process is in control (we have insufficient evidence to conclude the process is out of control) if
As a result, we conclude that the process is out of control if either • or • We call • the upper control limit (UCL) and • the lower control limit (LCL). • What about ? • Traditionally, , which corresponds to an =.0027.
We summarize this sequence of tests by a graphical procedure. Any observed sample mean above or below the control limits is considered evidence that the process is out of control. If a “out of control” condition signals, then we must search for the assignable cause, correct it, and restart the chart.
Note: It is possible for a “false alarm” to occur. False alarm: The chart indicates that the process is out of control when it is not. What is P(false alarm)? Let N be the number of samples until the process signals an out of control condition. If the process is in control and we use ,
It is important to note: A control chart will signal on out of control situation at some point in time even if the process remains in control the entire time. was chosen to insure that the process will signal very infrequently when it is in control. On the other hand, if μ1 is significantly different from μ0, then the chart will signal quickly. How quickly depends upon
The general form of our control charts is • θ represents the characteristic of interest we wish to monitor. • We shall consider the cases of: • sample mean, • sample range, • sample proportion • sample “counts”. • θ0 represents the target value for θ. • represents the standard error for our estimator of θ.
B. - and R-Charts Consider monitoring the ash contents for a pencil lead process. Suppose we take a sample of 5 lots each shift. 1. The R-Chart First, consider monitoring the within sample variability. Thus, at each time period, we need to estimate σ. Let yij be the jth observation (j = 1, …, n) taken at the ith interval (i = 1,2, …, ). Let Ri be the sample range of these n observations.
We note that Ri is a measure of the “spread” or variability at the ith times interval. Also, it is easy to calculate. If our data follow a normal distribution, then Ri is an estimate of a multiple of σ. Typically, we do not know the true in control value for σ. Problem: How should we estimate it? Solution: A “base period”. We use an initial base period of m samples. m may be as small as 20 intervals. Personally, I recommend 40-60 intervals.
We then base our control limits for the sample ranges on the average sample range from this base period, , given by The control limits for the range are: where D3 and D4 are appropriate constants. (see the text). Note: for n ≤ 6, D3 = 0. For our example, the data follow. Let the first 20 samples form the base period.
Example: the data are: Let the first 20 samples form the base period.
In this example, n = 5 D4 = 2.115 D3 = 0 The control limits are: The resulting chart is:
2. The -Chart The -Chart simply refers to a control chart for sample means or averages. Let be the sample mean of the n observations taken at the ith time interval; thus, Often, both μ0 and σ0 are unknown. In such situations, we use a base period of m samples to estimate it by
Traditionally, people have used to estimate σ. Actually a better estimate of σ is based on , where the is the sample standard deviation for the ith sample. See the text for details.
It can be shown that which is an estimate of and which is an estimate of where A2 is a constant which comes from the Table 5 in the Appendix. Note: A2 depends upon the number of observations in each sample.
The center line for this chart is . The control chart thus will have the form: ________________________________ ________________________________ ________________________________ As an example, again consider the pencil lead ash data set. The observations are ash contents for lots of pencil lead. Five lots constitute a sub-group or sample.
Again, we shall use the first 20 samples as our base period. Since n=5, A2 = 0.577, and . Thus, our control limits are
3. Comments or and R charts: 1. Typically both charts are run simultaneously. Recall, a basis assumption of the chart is that σ2 is constant. Thus, the chart assumes that the R chart is in control. 2. In general the R chart is more stable than the chart. Generally, the mean tends to change more frequently then the variance. 3. In some cases, the R chart will signal a shift in the mean before the chart. This can occur if the shift in the mean happens during a particular sample. In such a case, the Range, which is sensitive to “outliers”, may pick up the shift while may not.
4. The R-chart assumes that the data come from a normal distribution (quite restrictive!). 5. The -chart assumes the Central Limit Theorem. We should use graphical techniques such as the stem-and-leaf, boxplot and the normal probability plot on the observations in the base period to determine how reasonable these assumptions are.
Once again, consider the pencil lead ash data. The stem-and-leaf for the base period follows. N = 100 Median = 42.1 Quartiles = 41.3, 42.5 Decimal point is at the colon 40 : 1223333 40 : 5556778899 41 : 00002233344 41 : 555566777789 42 : 000000111112222223333333334444 42 : 555555555666666777789 43 : 0012234 43 : 77
The boxplot follows. The normal probability plot follows.
C. The np-chart In class, simulate a process which produces good/bad data. A prime example is Deming's Red Bead Experiment, available from several sources (check the periodical Quality Progress published by the American Society for Quality). The basic idea: The experiment uses a container filled with 500 red and 2500 white beads (20% red beads). Using a special paddle with 50 holes in it, students sample from the population. Someone records the number of red beads on each paddle drawn. An inexpensive variant is to use red and white poker chips. In class, construct the appropriate control chart.
yi represents the number of red beads on the ith paddle drawn. • p is the true proportion of red beads which should be drawn. • Note: As a first approximation, p is 0.2, but as Deming pointed out every time he conducted the experiment, the true value of p is actually something different, close but different. • The red and white beads are actually different sizes, so there is no reason to expect that the true proportion is exactly .2. • Deming's paddle actually had a true proportion of something less than 0.2, based on the many times he conducted the experiment! • n is the number of beads drawn each time. Usually, n = 50.
The number of red beads per paddle follows a binomial distribution; thus, • E(yi) = np, and • var(yi) = np(1-p). • If p is unknown, then we can use a base period of m samples to estimate p by • where • The appropriate control limits are
D. The c-Chart Consider items which we evaluated in terms of the number of defects present. Let ci represent the “count” for the number of defects found in the ith sample of n items inspected. Note: n may be one. Assume that n is fixed and constant for all samples. What is an appropriate distribution for ci? Poisson
Let λ be the expected number of defects per samples. What is a reasonable procedure for monitoring ci? A sequence of hypothesis tests of the form H0: λ = λ0 Ha: λ ≠ λ0.
The Test Statistic: Critical Region Reject H0 if |Zi| > 3 This leads to the following control limits Problem: Do we know ?
No, therefore we must estimate it. Again use a base period of m samples. Therefore,
The following data represent the number of contaminating particles on silicon wafers after a rinsing operation. Base Period 7 4 9 9 2 10 3 6 6 5 5 7 5 7 3 4 8 4 5 5 Next 40 samples 9 8 8 8 13 10 6 10 11 3 11 13 9 11 13 15 6 10 11 12 12 2 4 7 2 4 7 6 7 4 6 4 6 6 8 5 6 9 3 6
For our data, m = 20 and ; thus, The resulting control limits are
E. CUSUM and EWMA Charts Standard control charts use only the information in the current subgroup. This leads to them having problems detecting small shifts. Another approach is to use information from successive groups. Let’s start with the CUSUM (cumulative sum) chart. Consider the hypotheses Let Si be the CUSUM statistic for the ith observation where Si-1 is the value of the CUSUM statistic from previous observation, Zi=(yi-μ0)/σ, d is an appropriate constant.
If Si>0, the current information suggests the process might be out-of-control. How large is large? We need a threshold, so if Si>h, we will claim the process has shifted. We typically choose h=5 along with S0=0 and d=0.5. Consider testing: then we say the process is out-of control if Si>5. We estimate the standard deviation from our data as , then The data and the CUSUM values are shown below:
The CUSUM chart is typically used for one-sided tests, but can be used for two-sided alternatives by plotting the values we discussed and comparing them to h=5 and plotting using h=-5 as the threshold. An alternative time-weighted chart is the EWMA (exponentially weighted moving average) chart. This chart is typically used for two-sided alternatives. The EWMA statistic is where Xi is ith observation, Zi-1 is value of the EWMA statistic for the previous observation and 0 < Φ≤ 1 is weighting constant. We will let Z0=μ0.
The control limits for the EWMA are with the center line at μ0. Using k=2.7 and Φ=0.1 is approximately equal to the CUSUM with h=5 and d=0.5. Consider the previous example: