Download

1 / 35
350 likes | 366 Views
This review provides an overview of Hidden Markov Models (HMMs) and their applications in tagging and segmentation. It explores the use of Maximum Entropy (MaxEnt) models as an alternative to generative models in HMMs.

E N D
Conditional Markov Models: MaxEnt Tagging and MEMMs William W. Cohen CALD
0.5 0.9 0.5 0.1 0.8 0.2 Review: Hidden Markov Models A C 0.6 0.4 • Efficient dynamic programming algorithms exist for • Finding Pr(S) • The highest probability path P that maximizes Pr(S,P) (Viterbi) • Training the model • (Baum-Welch algorithm) A C 0.9 0.1 S1 S2 S4 S3 A C 0.3 0.7 A C 0.5 0.5
HMM for Segmentation • Simplest Model: One state per entity type
HMM Learning • Manally pick HMM’s graph (eg simple model, fully connected) • Learn transition probabilities: Pr(si|sj) • Learn emission probabilities: Pr(w|si)
Learning model parameters • When training data defines unique path through HMM • Transition probabilities • Probability of transitioning from state i to state j = number of transitions from i to j total transitions from state i • Emission probabilities • Probability of emitting symbol k from state i = number of times k generated from i number of transition from I • When training data defines multiple path: • A more general EM like algorithm (Baum-Welch)
What is a “symbol” ??? Cohen => “Cohen”, “cohen”, “Xxxxx”, “Xx”, … ? 4601 => “4601”, “9999”, “9+”, “number”, … ? Datamold: choose best abstraction level using holdout set
What is a symbol? Bikel et al mix symbols from two abstraction levels
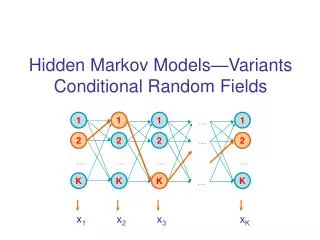
What is a symbol? Ideally we would like to use many, arbitrary, overlapping features of words. S S S identity of word ends in “-ski” is capitalized is part of a noun phrase is in a list of city names is under node X in WordNet is in bold font is indented is in hyperlink anchor … t - 1 t t+1 … is “Wisniewski” … part ofnoun phrase ends in “-ski” O O O t - t +1 t 1 Lots of learning systems are not confounded by multiple, non-independent features: decision trees, neural nets, SVMs, …
Pr(red|red) = 1 Pr(red) Pr(green|green) = 1 Pr(green) Stupid HMM tricks start
Pr(red|red) = 1 start Pr(red) Pr(green|green) = 1 Pr(green) Stupid HMM tricks Pr(y|x) = Pr(x|y) * Pr(y) / Pr(x) argmax{y} Pr(y|x) = argmax{y} Pr(x|y) * Pr(y) = argmax{y} Pr(y) * Pr(x1|y)*Pr(x2|y)*...*Pr(xm|y) Pr(“I voted for Ralph Nader”|ggggg) = Pr(g)*Pr(I|g)*Pr(voted|g)*Pr(for|g)*Pr(Ralph|g)*Pr(Nader|g)
From NB to Maxent Learning: set alpha parameters to maximize this: the ML model of the data, given we’re using the same functional form as NB. Turns out this is the same as maximizing entropy of p(y|x) over all distributions.
MaxEnt Comments • Implementation: • All methods are iterative • Numerical issues (underflow rounding) are important. • For NLP like problems with many features, modern gradient-like or Newton-like methods work well – sometimes better(?) and faster than GIS and IIS • Smoothing: • Typically maxent will overfit data if there are many infrequent features. • Common solutions: discard low-count features; early stopping with holdout set; Gaussian prior centered on zero to limit size of alphas (ie, optimize log likelihood - sum alpha)
MaxEnt Comments • Performance: • Good MaxEnt methods are competitive with linear SVMs and other state of are classifiers in accuracy. • Can’t easily extend to higher-order interactions (e.g. kernel SVMs, AdaBoost). • Training is relatively expensive. • Embedding in a larger system: • MaxEnt optimizes Pr(y|x), not error rate.
MaxEnt Comments • MaxEnt competitors: • Model Pr(y|x)with Pr(y|score(x)) using score from SVM’s, NB, … • Regularized Winnow, BPETs, … • Ranking-based methods that estimate if Pr(y1|x)>Pr(y2|x). • Things I don’t understand: • Why don’t we call it logistic regression? • Why is always used to estimate the density of (y,x) pairs rather than a separate density for each class y? • When are its confidence estimates reliable?
What is a symbol? Ideally we would like to use many, arbitrary, overlapping features of words. S S S identity of word ends in “-ski” is capitalized is part of a noun phrase is in a list of city names is under node X in WordNet is in bold font is indented is in hyperlink anchor … t - 1 t t+1 … is “Wisniewski” … part ofnoun phrase ends in “-ski” O O O t - t +1 t 1
What is a symbol? S S S identity of word ends in “-ski” is capitalized is part of a noun phrase is in a list of city names is under node X in WordNet is in bold font is indented is in hyperlink anchor … t - 1 t t+1 … is “Wisniewski” … part ofnoun phrase ends in “-ski” O O O t - t +1 t 1 Idea: replace generative model in HMM with a maxent model, where state depends on observations
What is a symbol? S S S identity of word ends in “-ski” is capitalized is part of a noun phrase is in a list of city names is under node X in WordNet is in bold font is indented is in hyperlink anchor … t - 1 t t+1 … is “Wisniewski” … part ofnoun phrase ends in “-ski” O O O t - t +1 t 1 Idea: replace generative model in HMM with a maxent model, where state depends on observations and previous state
What is a symbol? S S identity of word ends in “-ski” is capitalized is part of a noun phrase is in a list of city names is under node X in WordNet is in bold font is indented is in hyperlink anchor … S t - 1 t+1 … t is “Wisniewski” … part ofnoun phrase ends in “-ski” O O O t - t +1 t 1 Idea: replace generative model in HMM with a maxent model, where state depends on observations and previous state history
Ratnaparkhi’s MXPOST • Sequential learning problem: predict POS tags of words. • Uses MaxEnt model described above. • Rich feature set. • To smooth, discard features occurring < 10 times.
Feature selection GIS MXPOST: learning & inference
MXPost results • State of art accuracy (for 1996) • Same approach used successfully for several other sequential classification steps of a stochastic parser (also state of art). • Same approach used for NER by Bortwick, Malouf, Manning, and others.
Finding the most probable path: the Viterbi algorithm (for HMMs) • define to be the probability of the most probable path accounting for the first i characters of x and ending in state k • we want to compute , the probability of the most probable path accounting for all of the sequence and ending in the end state • can define recursively • can use dynamic programming to find efficiently
Finding the most probable path: the Viterbi algorithm for HMMs • initialization:
The Viterbi algorithm for HMMs • recursion for emitting states (i =1…L):
The Viterbi algorithm for HMMs and Maxent Taggers • recursion for emitting states (i =1…L):
MEMMs • Basic difference from ME tagging: • ME tagging: previous state is feature of MaxEnt classifier • MEMM: build a separate MaxEnt classifier for each state. • Can build any HMM architecture you want; eg parallel nested HMM’s, etc. • Data is fragmented: examples where previous tag is “proper noun” give no information about learning tags when previous tag is “noun” • Mostly a difference in viewpoint