Download

1 / 14
140 likes | 273 Views
Further Pipeline Issues. Cray 1. Designed in 1976 Cost $8,800,000 8MB Main Memory Max performance 160 MFLOPS Weight 5.5 Tons Power 115 KW (250KW inc Storage and cooling). Further Pipeline Issues. MUX. Data Cache. More Pipeline Detail.

E N D
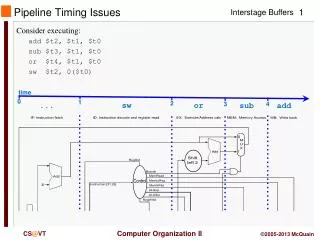
Further Pipeline Issues COMP25212
Cray 1 • Designed in 1976 • Cost $8,800,000 • 8MB Main Memory • Max performance 160 MFLOPS • Weight 5.5 Tons • Power 115 KW (250KW inc Storage and cooling) COMP25212
Further Pipeline Issues COMP25212
MUX Data Cache More Pipeline Detail IF ID EX MEM WB Register Bank Instruction Cache PC ALU COMP25212
Data Hazards • Pipeline can cause other problems • Consider ADD R1,R2,R3 MUL R0,R1,R1 • The ADD instruction is producing a value in R1 • The following MUL instruction uses R1 as input COMP25212
MUX Data Cache Instructions in the Pipeline IF ID EX MEM WB MUL R0,R1,R1 ADD R1,R2,R3 Register Bank Instruction Cache PC ALU COMP25212
The Data isn’t Ready • At end of ID cycle, MUL instruction should have selected value in R1 to put into buffer at input to EX stage • But the correct value for R1 from ADD instruction is being put into the buffer at output of EX stage at this time • It won’t get to input of Register Bank until one cycle later – then probably another cycle to write into R1 COMP25212
Insert Delays? • One solution is to detect such data dependencies in hardware and hold instruction in decode stage until data is ready – ‘bubbles’ & wasted cycles again • Another is to use the compiler to try to reorder instructions • Only works if we can find something useful to do – otherwise insert NOPs - waste COMP25212
MUX Data Cache Forwarding • We can add extra paths for specific cases • Control becomes more complex MUL R0,R1,R1 ADD R1,R2,R3 Register Bank Instruction Cache PC ALU COMP25212
Why did it Occur? • Due to the design of our pipeline • In this case, the result we want is ready one stage ahead of where it was needed, why pass it down the pipeline? • But what if we have the sequence LDR R1,[R2,R3] MUL R0,R1,R1 • LDR instruction means load R1 from memory address R2+R3 COMP25212
Pipeline Sequence for LDR • Fetch • Decode and read registers (R2 & R3) • Execute – add R2+R3 to form address • Memory access, read from address • Now we can write the value into register R1 • We have designed the ‘worst case’ pipeline to work for all instructions COMP25212
MUX Data Cache Forwarding • We can add extra paths for specific cases • Control becomes more complex • LDR R1,[R2,R3] MUL R0,R1,R1 NOP Register Bank Instruction Cache PC ALU
Longer Pipelines • As mentioned previously we can go to longer pipelines • Do less per pipeline stage • Each step takes less time • So can increase clock frequency • But greater penalty for hazards • More complex control • Negative returns? COMP25212
Where Next? • Despite these difficulties it is possible to build processors which approach 1 cycle per instruction (cpi) • Given that the computational model is one of serial instruction execution can we do any better than this? COMP25212