Download

1 / 10
100 likes | 192 Views
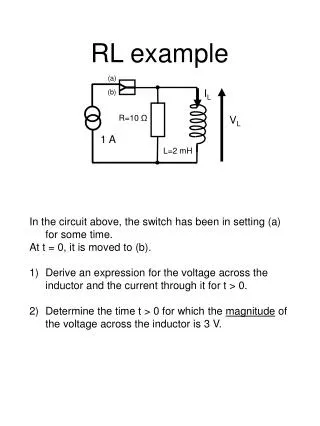
Ata Kaban A.Kaban@cs.bham.ac.uk School of Computer Science University of Birmingham. RL - Worksheet -worked exercise-. 2. 1. -10. 50. 50. -2. -10. -2. -2. 3. 4. -2. RL. Exercise.

E N D
Ata Kaban A.Kaban@cs.bham.ac.uk School of Computer Science University of Birmingham RL - Worksheet-worked exercise-
2 1 -10 50 50 -2 -10 -2 -2 3 4 -2 RL. Exercise The figure below depicts a 4-state grid world, which’s state 2 represents the ‘gold’. Using the immediate reward values shown on the figure and employing the Q-learning algorithm, do anti-clockwise circuits on the four states updating the action-state table. Note. Here, the Q-table will be updated after each cycle.
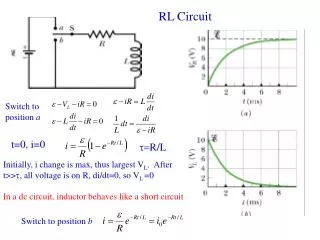
2 1 -10 50 50 -2 -10 -2 -2 3 4 -2 Solution Initialise each entry of the table of Q values to zero Iterate:
2 1 -10 50 50 -2 -10 -2 -2 3 4 -2 First circuit: Q(3, ) = -2 +0.9 max{Q(4, ),Q(4, )}= -2 Q(4, ) = 50 +0.9 max{Q(2, ),Q(2, )}= 50 Q(2, ) = -10 +0.9 max{Q(1, ),Q(1, )}= -10 Q(1, ) = -2 +0.9 max{Q(3, ),Q(3, )}= -2 Q(3, ) = -2 +0.9 max{Q(4, ),50}=43
Second circuit: Q(4, ) = 50 +0.9 max{Q(2, ),Q(2, )}= 50 +0.9 max{0,-10}=50 Q(2, ) = -10 +0.9 max{Q(1, ),Q(1, )}= -10 +0.9 max{0,-2}=-10 Q(1, ) = -2 +0.9 max{Q(3, ),Q(3, )}= -2 +0.9 max{0,43}= 36.7 Q(3, ) = -2 +0.9 max{Q(4, ), Q(4,)}=-2 +0.9 max{0,50}=43
Third circuit: Q(4, ) = 50 +0.9 max{Q(2, ),Q(2, )}= 50 +0.9 max{0,-10}=50 Q(2, ) = -10 +0.9 max{Q(1, ),Q(1, )}= -10 +0.9 max{0,36.7}=23.03 Q(1, ) = -2 +0.9 max{Q(3, ),Q(3, )}= -2 +0.9 max{0,43}= 36.7 Q(3, ) = -2 +0.9 max{Q(4, ), Q(4,)}=-2 +0.9 max{0,50}=43
Fourth circuit: Q(4, ) = 50 +0.9 max{Q(2, ),Q(2, )}= 50 +0.9 max{0,23.03}=70.73 Q(2, ) = -10 +0.9 max{Q(1, ),Q(1, )}= -10 +0.9 max{0,36.7}=23.03 Q(1, ) = -2 +0.9 max{Q(3, ),Q(3, )}= -2 +0.9 max{0,43}= 36.7 Q(3, ) = -2 +0.9 max{Q(4, ), Q(4,)}=-2 +0.9 max{0,70.73}=61.66
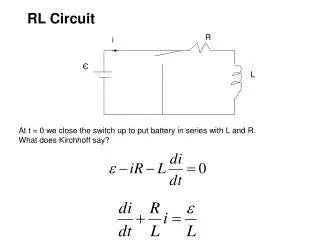
Optional material: Convergence proof of Q-learning • Recall: Sketch of proof • Consider the case of deterministic world, where each (s,a) is visited infinitely often. • Define a full interval as an interval during which each (s,a) is visited. • Show, that during any such interval, the absolute value of the largest error in Q table is reduced by a factor of . • Consequently, as <1, then after infinitely many updates, the largest error converges to zero.
Solution • Let be a table after n updates and en be the maximum error in this table: • What is the maximum error after the (n+1)-th update?
Obs. No assumption was made over the action sequence! Thus, Q-learning can learn the Q function (and hence the optimal policy) while training from actions chosen at random as long as the resulting training sequence visits every (state, action) infinitely often.