Download
1 / 1
10 likes | 191 Views
Automatic Interesting Object Extraction from Images Using Complementary Saliency Maps Haonan Yu 1 , Jia Li 2,3 , Yonghong Tian 1 , Tiejun Huang 1 1 National Engineering Laboratory for Video Technology, School of EE & CS, Peking University, China

E N D
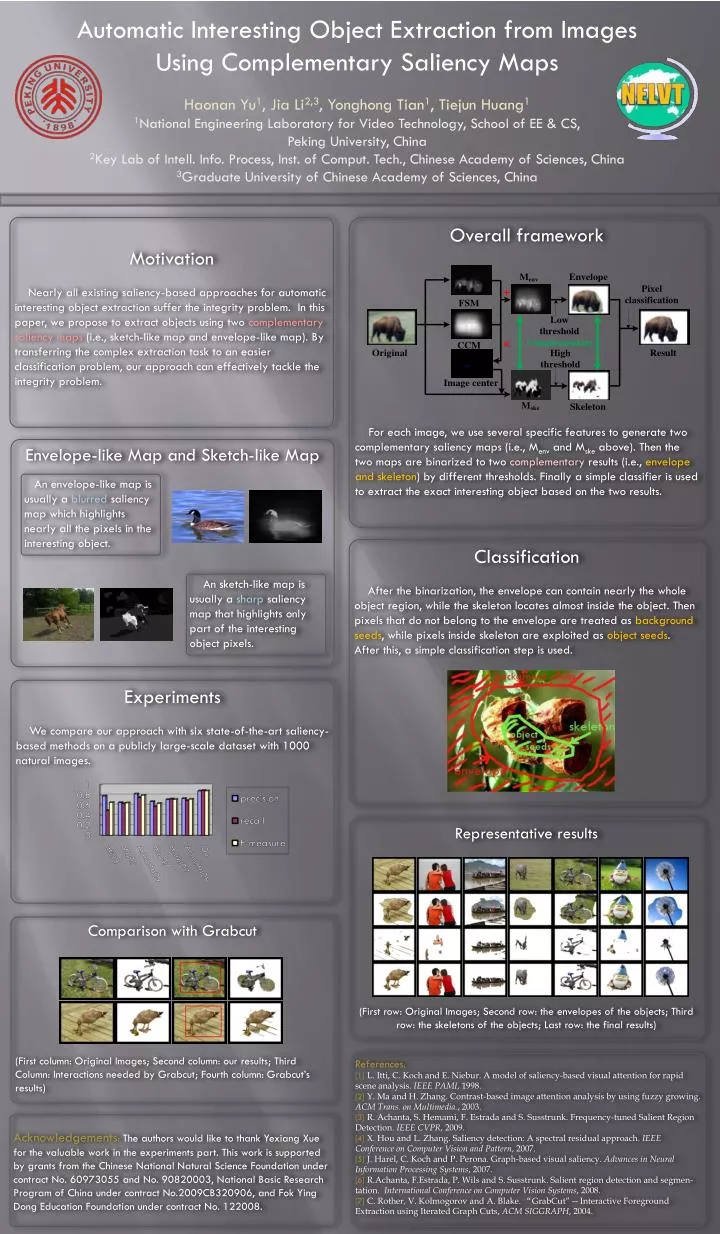
Automatic Interesting Object Extraction from Images Using Complementary Saliency Maps Haonan Yu1, Jia Li2,3, Yonghong Tian1, Tiejun Huang1 1National Engineering Laboratory for Video Technology, School of EE & CS, Peking University, China 2Key Lab of Intell. Info. Process, Inst. of Comput. Tech., Chinese Academy of Sciences, China 3Graduate University of Chinese Academy of Sciences, China Motivation Nearly all existing saliency-based approaches for automatic interesting object extraction suffer the integrity problem. In this paper, we propose to extract objects using two complementary saliency maps (i.e., sketch-like map and envelope-like map). By transferring the complex extraction task to an easier classification problem, our approach can effectively tackle the integrity problem. Overall framework For each image, we use several specific features to generate two complementary saliency maps (i.e., Menv and Mske above). Then the two maps are binarized to two complementary results (i.e., envelope and skeleton) by different thresholds. Finally a simple classifier is used to extract the exact interesting object based on the two results. Envelope-like Map and Sketch-like Map An envelope-like map is usually a blurred saliency map which highlights nearly all the pixels in the interesting object. Classification After the binarization, the envelope can contain nearly the whole object region, while the skeleton locates almost inside the object. Then pixels that do not belong to the envelope are treated as background seeds, while pixels inside skeleton are exploited as object seeds. After this, a simple classification step is used. An sketch-like map is usually a sharp saliency map that highlights only part of the interesting object pixels. Experiments We compare our approach with six state-of-the-art saliency-based methods on a publicly large-scale dataset with 1000 natural images. Representative results (First row: Original Images; Second row: the envelopes of the objects; Third row: the skeletons of the objects; Last row: the final results) Comparison with Grabcut (First column: Original Images; Second column: our results; Third Column: Interactions needed by Grabcut; Fourth column: Grabcut’s results) References: [1] L. Itti, C. Koch and E. Niebur. A model of saliency-based visual attention for rapid scene analysis. IEEE PAMI, 1998. [2] Y. Ma and H. Zhang. Contrast-based image attention analysis by using fuzzy growing. ACM Trans. on Multimedia., 2003. [3] R. Achanta, S. Hemami, F. Estrada and S. Susstrunk. Frequency-tuned Salient Region Detection. IEEE CVPR, 2009. [4] X. Hou and L. Zhang. Saliency detection: A spectral residual approach. IEEE Conference on Computer Vision and Pattern, 2007. [5] J. Harel, C. Koch and P. Perona. Graph-based visual saliency. Advances in Neural Information Processing Systems, 2007. [6] R.Achanta, F.Estrada, P. Wils and S. Susstrunk. Salient region detection and segmentation. International Conference on Computer Vision Systems, 2008. [7] C. Rother, V. Kolmogorov and A. Blake. “GrabCut” -- Interactive Foreground Extraction using Iterated Graph Cuts, ACM SIGGRAPH, 2004. Acknowledgements: The authors would like to thank Yexiang Xue for the valuable work in the experiments part. This work is supported by grants from the Chinese National Natural Science Foundation under contract No. 60973055 and No. 90820003, National Basic Research Program of China under contract No.2009CB320906, and Fok Ying Dong Education Foundation under contract No. 122008.





















