Download

1 / 19
190 likes | 352 Views
TRENDS in Cognitive Sciences vol. 10, no. 7, 2006. Probabilistic inference in human semantic memory Mark Steyvers , Tomas L. Griffiths, and Simon Dennis. 소프트컴퓨팅연구실 오근현. Overview . Relational models of memory The Retrieving Effectively from Memory(REM) Model

E N D
TRENDS in Cognitive Sciences vol. 10, no. 7, 2006 Probabilistic inference in human semantic memoryMark Steyvers, Tomas L. Griffiths, and Simon Dennis 소프트컴퓨팅연구실 오근현
Overview • Relational models of memory • The Retrieving Effectively from Memory(REM) Model • High-dimensional semantic spaces • Probabilistic topic models • Modeling semantic memory at the sentence level • Conclusion
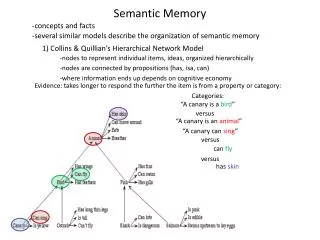
Relational Models of Memory • Encoding much knowledge stored in memory using language • Most of the stimuli used in memory experience are linguistic • How the statistics of language influence human memory? • Rational analysis • A framework for developing computational models of cognition • Making the working assumption • human cognition approximates an optimal response to the computational problems posed by the environmental • The role of probabilistic inference in memory • A history factor • The occurrence pattern of the item over time( Recent or frequent ) • A context factor • The association between items (Similar)
The Retrieving Effectively from Memory(REM) • Stronger assumptions • Encoding process • Representation of information • Emphasizing the role of probabilistic inference in explaining human memory • Recognition memory task(Application) • Discriminating between old items and new items • Assumptions • Words : Vectors of Features(noisy and incomplete) • A calculation of the likelihood ratio • Balancing the evidence for and ‘old’ decision against a ‘new’ decision • Degree of match between the memory probe and contents of memory
Example of Comparing a Test • 5 Features • Green box : Matches • Red box : Mismatches • Empty Positions : Missing Features • 3rd memory trace : the most evidence that test item is old • Data ‘D’ : Each trace
Posterior odds • Posterior Odds • Posterior : 증거(Evidence) 이후 • Odds :두 배반적 가설의 확률 비 • Prior odds is set at 1 # of old == # of new • An old decision • Exceeding some criterion(usually set at 1) An example distribution of log posterior odds
Mirror Effects • Increase in hit rate • Hit rate : correctly recognizing an old item as old • decrease in false alarm rates • False alarm rates : falsely recognizing a new item as old • Example • Low frequency words • More rare features are stored for low frequency words relative to high frequency words • How encoding conditions that improves the diagnosticity of feature matches for low frequency target items • lower the probability of chance matches by low frequency distractor items
The Hyperspace Analog to Language(HAL) • Each word by a vector where each element of the vector corresponds to a weighted co-occurrence value of that word with some other word
The Latent Semantic Analysis(LSA) • The co-occurrence information between words and passages • Applying matrix decomposition techniques • to reduce the dimensionality of the original matrix to a much smaller size • preserving as much as possible the covariation structure of words and documents
The Word Association Space(WAS) • Input a set of association norms • Formed by asking subjects to produce the first word that comes to mind in response to a given cue
Probabilistic Topic Models • The Focus on prediction as a central problem of memory • Emphasizing the role of context in guiding predictions • The latent structure of words using topics • Documents : mixtures of topics • A topic : A Probability distributions over words • Topic Model is a generative model for documents
Distributions for Topics • Different weight to thematically related words • P(z) : The distribution over topics z in a particular document • P(W|z) : The probability distribution over words w given topic z • P( =j) : the probability that the ‘j’th topic was sampled ‘i’th word • P( | =j) : the probability of word under topic j • T : The number of topics
Using Bayes’ Rule • The problem is to predict the conditional probability of word (the response word) given the cue word • Applying Bayes’s rule
The same word with two different meaning • Predictions about which words are likely to appear next in a document or conversation, based on the previous words • A rational model of how context should influence memory • The focus on the role of history in earlier models • The effects of context being appropriately modulated by the statistics of the environment
The Syntagmatic Paradigmatic(SP) Model • Modeling Semantic Memory at the sentence level • Specifying a simple probabilistic model of knowledge and allowing representational content • to emerge response to the structure of the environment • Syntagmatic Associations • Capturing structural and propositional knowledge between words that follow each other • Structural traces that correspond to individual sentence • Paradigmatic Associations • between words that fit in the same slots across sentences • combined to form relational(or propositional) traces that correspond to the same sentences
Sampling structural and relational exemplars • Mapping the two sentences to each other in a one to one fashion • Change : Sampras-Kuerten/ Agassi-Roddick • Match : defeated • Delete : Pete – ㅡ(symbol of deletion, empty words) • Priority • Match > change > insertion or deletion
The Architecture of SP Model • 4 and 5 traces in Sequential LTM • # containing the pattern {Roddick, Costa} • {Sampras} defeat {Agassi} Agassi need to align ‘#’ symbol • The pattern {Agassi, Roddick, Costa}
Conclusion • Probabilistic inference • A natural way to address problems of reasoning under uncertainty • A search for richer representations of the structure of linguistic stimuli • Contribution to the question • How linguistic stimuli might be represented in memory • Rational Analysis • A natural framework to understand the tight coupling between behavior and environmental staticstics • Linguistic stimuli form an excellent testing ground for rational model of memory