Download

1 / 34
360 likes | 527 Views
The x86 Server Platform. .. Resistance is futile…. Dec 6, 2004. Server shipments – Total vs x86. Market Share: Servers, United States, 2Q04 . Michael McLaughlin, Market Share: Servers, United States, 2Q04 7 October 2004, Gartner. x86 Platform CPUs. Intel

E N D
The x86 Server Platform .. Resistance is futile…. Dec 6, 2004
Market Share: Servers, United States, 2Q04 Michael McLaughlin, Market Share: Servers, United States, 2Q04 7 October 2004, Gartner
x86 Platform CPUs • Intel • Xeon MP – Gallatin (future is Potomac) • Xeon SP/DP – EM64T - Nacona • Itanium II MP – Madison (future is Montecito) • AMD • Opteron
130 nm 3 GHz 4 MB L3 Cache FSB - 400 MHz Gallatin - MP
90 nm Clock Speed – 3.2-3.6 GHz L3 – 4 MB FSB – 800 Mhz Nacona – Single Processor with EM64T
130 nm 9 MB L3 cache 1.6 GHz FSB – 400 MHz Itanium II - Madison
STOP • Why Multi-Core? • .. And while we’re at it, why Multi-Threading? • It’s all about the balance of • Silicon real estate • Compiler technology • Cost • Power …. to meeting the constant pressure to double performance every 18 months
Memory Latency vs CPU Speed MicroprocessorOperating Frequency (GHz) DRAM AccessFrequency (10-9 sec)-1 10.0 10.0 1.0 1.0 Microprocessor on-chip clock Commodity DRAM 0.1 0.1 0.01 0.01 1990 1995 2000 2005 2010 Production Year
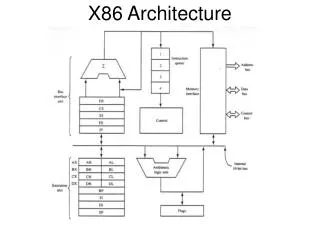
Processor Architecture • When latency ↓ Ø and bandwidth ↑∞we will have the perfect CPU • A great deal of innovation has centered around approximating this perfect world • CISC • CPU Cache • RISC • EPIC • Multi-Threading • Multiple Cores
Complex Instruction Set Computer • Hardware implements assembler instructions • MULT A, B • hardware loads registers, multiplies and stores results • Multiple clocks needed for an instruction • RAM requirements are relatively small • Compilers translate high level languages down to assembler instructions – Von Neumann hardware http://www.hardwarecentral.com/hardwarecentral/tutorials/2427
CPU Cache • When CPU speeds started to increase, memory latency emerged as a bottleneck • CPU caches were used to keep local references “close” to the CPU • For SMP systems, memory banks were more than a clock away • It is not uncommon today to find 3 orders of magnitude between the fastest and slowest memory latency
Reduced Instruction Set Computer • Hardware is simplified – fewer transistors are needed for full instruction set • RAM requirements are higher to store intermediate results and more code • Compilers are more complex • Clock speeds increase because instructions are simpler • Deterministic, simple instructions allow pipelining
Pipelining 25% busy Higher Clock Speeds! 100% busy 80% busy 60% busy 40% busy
Branch Prediction • While processing in parallel, branches occur • Branch prediction is used to increase the probability that a specific branch will be followed • If incorrect, the pipeline is “dead” and the CPU stalls • Statistics • 10%-20% of instructions are branches • Predictions are incorrect about 10% of the time • As the pipeline increases, probability of miss increases and cycles will be discarded • 80-deep pipeline / 20% branches / 10% miss => 80% chance of miss and a penalty of 80 cycles
Itanium II Epic Instruction SetExplicitly Parallel Instruction Computing • Compiler can indicate code that can be executed in parallel • Both branches are pipelined • No lost cycles due to miss-prediction • Pipeline can be deeper • Complexity continues to move into the compiler
Multiple Cores • Fabrication sizes continue to diminish • The additional real estate has been used to put more and more memory on the die • Multi-core technology provides a new way to exploit the additional space • The clock rates cannot continue to climb due to the excessive heat • P = C * V2 * f C - switch capacitance V – Supply Voltage f – clock frequency • Multiple cores is the next step to providing faster execution times for applications
130 nm Clock Speed – 1.4-2.4 GHz L2 – 1 MB 6.4 GB/s Hypertransport AMD Opteron 800 Series
Architectural Comparison Hypertransport™ - 6.4 GB/s Opteron Opteron Xeon Xeon Xeon Xeon 6.4 GB/s Opteron Opteron PCI-XBridge MemoryAddressBuffer DDR 144-bit PCI-XBridge SNC PCI-XBridge PCI-XBridge MemoryAddressBuffer PCI-XBridge I/OHub OtherBridge MemoryAddressBuffer I/OHub MemoryAddressBuffer
Mapping Workloads onto Architecture • Consider a dichotomy of workloads: • Large Memory Model – This needs a large, single system image and a large amount of coherent memory • Database apps - SQL Server / Oracle • Business Intelligence – Data Warehousing + Analytics • Memory-resident databases • 64 bit architectures allow memory addressability above 1 TB • Small/Medium Memory Model – This can be cost-effective in workloads that do not require extensive shared memory/state • Stateless Applications and Web Services • Web Servers • Clusters of systems for parallelized applications and grids
Large Server Vendors • Intel Announcement (Nov 19) Otellini said product development, marketing and software efforts (for Itanium) will all now be aimed at "greater than four-way systems". He also said, "The mainframe isn't dead. That's where I'd like to push Itanium over time." • The size of the SMP is affected by Intel’s chip set support for coherent memory • OEM Vendors (Unisys, HP, SGI, Fujitsu, IBM) • Each has unique “chip set” to build basic four-ways into large SMP systems • IBM has Power5, which is a direct competitor • Intel 32-bit and EM674T • This could emerge as the flagship product
Where Are We Going? • Since the early CISC computers, we have moved more and more of the complexity out to the compiler to achieve parallelism and fully exploit the silicon “real estate” • The power requirements, along with the smaller fabrication sizes, have pushed the CPU vendors to exploit multiple cores • The key to performance for these future machines will be the application’s ability to exploit parallelism