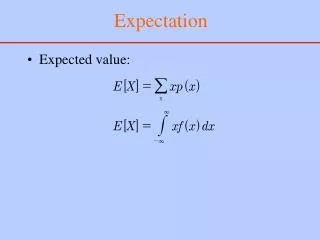Download

1 / 84
880 likes | 1.09k Views
Expectation. for multivariate distributions. Definition. Let X 1 , X 2 , …, X n denote n jointly distributed random variable with joint density function f ( x 1 , x 2 , …, x n ) then. Example.

E N D
Expectation for multivariate distributions
Definition Let X1, X2, …, Xn denote n jointly distributed random variable with joint density function f(x1, x2, …, xn ) then
Example Let X, Y, Z denote 3jointly distributed random variable with joint density function then Determine E[XYZ].
Thus you can calculate E[Xi] either from the joint distribution of X1, … , Xn or the marginal distribution of Xi. Proof:
The Linearity property Proof:
(The Multiplicative property)Suppose X1, … , Xq are independent of Xq+1, … , Xk then In the simple case when k = 2 if X and Y are independent
Proof Thus
Definition: For any two random variables X and Y then define the correlation coefficient rXY to be: if X and Y are independent
Properties ofthe correlation coefficient rXY The converse is not necessarily true. i.e. rXY= 0 does not imply that X and Y are independent.
More properties ofthe correlation coefficient rXY if there exists a and b such that where rXY = +1 if b > 0 and rXY = -1 if b< 0 Proof: Let Let for all b. Consider choosing b to minimize
Consider choosing b to minimize or Since g(b) ≥ 0, then g(bmin) ≥ 0
Hence g(bmin) ≥ 0 Hence
or Note If and only if This will be true if i.e.
Summary if there exists a and b such that where
Proof Thus
Some Applications (Rules of Expectation & Variance) Let X1, … , Xn be n mutually independent random variables each having mean mand standard deviation s(variance s2). Let Then
Also or Thus Hence the distribution of is centered at mand becomes more and more compact about mas n increases
Tchebychev’s Inequality Let X denote a random variable with mean m =E(X) and variance Var(X) = E[(X – m)2] = s2 then Note: Is called the standard deviation of X,
Tchebychev’s inequality is very conservative • k =1 • k = 2 • k = 3
The Law of Large Numbers Let X1, … , Xn be n mutually independent random variables each having mean m. Let Then for any d> 0 (no matter how small)
Proof We will use Tchebychev’s inequality which states for any random variable X. Now
Thus Thus
A Special case Let X1, … , Xn be n mutually independent random variables each having Bernoulli distribution with parameter p. Thus the Law of Large Numbers states
Thus the Law of Large Numbers states that converges to the probability of success p Some people misinterpret this to mean that if the proportion of successes is currently lower that p then the proportion of successes in the future will have to be larger than p to counter this and ensure that the Law of Large numbers holds true. Of course if in the infinite future the proportion of successes is p than this is enough to ensure that the Law of Large numbers holds true.
Some more applications Rules of expectation and Rules of Variance
The mean and variance of a Binomial Random variable We have already computed this by other methods: • Using the probability function p(x). • Using the moment generating function mX(t). Suppose that we have observed n independent repetitions of a Bernoulli trial. Let X1, … , Xn be n mutually independent random variables each having Bernoulli distribution with parameter pand defined by
Now X = X1 + … + Xn has a Binomial distribution with parameters n and p. X is the total number of successes in the n repetitions.
The mean and variance of a Hypergeometric distribution The hypergeometric distribution arises when we sample with replacement n objects from a population of N = a + b objects. The population is divided into to groups (group A and group B). Group A contains a objects while group B contains b objects Let Xdenote the number of objects in the sample of n that come from group A. The probability function of X is:
Therefore and
Also and We need to also calculate Note:
Thus and Note:
Thus and
Thus with and
Thus if X has a hypergeometric distribution with parameters a, b and n then
The mean and variance of a Negative Binomial distribution The Negative Binomial distribution arises when we repeat a Bernoulli trial until k successes (S) occur. Then X = the trial on which the kth success occurred. The probability function of X is: Let X1= the number of trial on which the 1st success occurred. and Xi= the number of trials after the (i -1)stsuccess on which the ithsuccess occurred (i ≥ 2)
Then X = X1 + … + Xk and X1, … , Xk are mutually independent Xieach have a geometric distribution with parameter p.