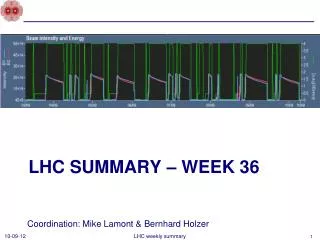
Download

1 / 11
110 likes | 288 Views
Michele Floris. Summary of first LHC logging DB meeting. Outline. Joint LHC machine experiments meeting: Interfacing to the LHC logging database for postprocessing (offline analysis). Goals of this meeting: Establish a first inventory of use cases and potential users

E N D
Michele Floris Summary of first LHC logging DB meeting
Outline • Joint LHC machine experiments meeting: Interfacing to the LHC logging database for postprocessing (offline analysis). • Goals of this meeting: • Establish a first inventory of use cases and potential users • Discussion on required functionality • How to continue this? • Talks: • Users (Machine + Experiments) • Logging and measurement service
LHC Beam Instrumentation • Quite some development already • Want at least same feature/performance
ALICE DIP DCS OCDB Post-processing/calibration should be done centrally Delay of publication? PROCESSING v1 API Logging Database raw What triggers the migration? Data format? Versions? Michele Floris
ATLAS Value based queries impossible • They also use DIP as primary data source Michele Floris
CMS Michele Floris
LHCb Current drawbacks • We are archiving everything on our own, including all beam and machine parameters, that we receive via DIP • advantage: we have the same access interface to ONE database • disadvantage: we always have to make sure we have everything and we clearly double the effort • the tool should be interfaced to ANY database, each parameter or condition in the right database • We don’t have direct access to nominal settings and nominal parameters, like collimators settings, golden orbit, etc • BLM thresholds we have but we archive the whole set ourselves… • We don’t have access to the corrected and calibrated data • May also allow correlating the whole set of data with shifters’ names in experiment control room and CCC…. Federico Alessio
f f FGC MK MS PIC WIC QPS ELEC TIM EAU BCT BLM BPM Cryo CIET Coll CV COMM BIC BETS Rad VAC SU Exp VAC CNGS f f f f f f f f f f f f f f f f f f f f f f f f Current Status > 300 extraction clients 0.4 2 million extraction requests per day PL/SQLfiltered data transfer 7 Days raw data ~20 Years filtered data ~ 800’000 signals ~ 300 data loading processes ~ 3.8 billion records per day ~ 105 GB per day 38 TB per year stored ~ 200’000 Signals ~ 50 data loading processes ~ 5.1 billion records per day ~ 130 GB per day 46 TB per year throughput MDB LDB Equipment – DAQ – FEC Equipment – DAQ – PLC Equipment – DAQ – PLC Forum on Interfacing to the Logging Database for Data Analysis
Spring HTTP Remoting Spring HTTP Remoting TIMBER Custom Java Applications (currently > 30) 10g AS Data Extraction – Java API CERN Accelerator Logging Service MDB JDBC TS Data LDB JDBC TS Data metadata JDBC Metadata They will only provide a JAVA interface (already used by timber and some 30 applications) We will need to implement a wrapper Forum on Interfacing to the Logging Database for Data Analysis
Misc from discussion • DIP not guaranteed to be reliable (uptime < 100%) • Access to DB mandatory • 2 main use cases • Running conditions (few users, lots of data) • Direct access to logging DB • Offline analysis (many users, less data) Backfill of OCDB? • Central post-processing: commonly requested • Versions! Format? Same Logging DB? • Concurrent R/W: will also provide mirror DB? Michele Floris
Most relevant variables • bunch/beam intensities • beam losses • beam positions • beam sizes (emittances) • collimator positions • some vacuum gauges • but also sporadically-measured quantities such as: • crossing angles • beta functions. Michele Floris