Download

1 / 23
230 likes | 400 Views
Data-Centric Reconfiguration with Network-Attached Disks. Alex Shraer ( Technion ). Joint work with: J.P. Martin, D. Malkhi, M. K. Aguilera (MSR) I. Keidar ( Technion ). Preview. The setting: data-centric replicated storage Simple network-attached storage-nodes Our contributions:

E N D
Data-Centric Reconfiguration with Network-Attached Disks Alex Shraer (Technion) Joint work with: J.P. Martin, D. Malkhi, M. K. Aguilera (MSR) I. Keidar (Technion)
Preview • The setting: data-centric replicated storage • Simple network-attached storage-nodes • Our contributions: • First distributed reconfigurable R/W storage • Asynch. VS. consensus-based reconfiguration Allows to add/remove storage-nodes dynamically
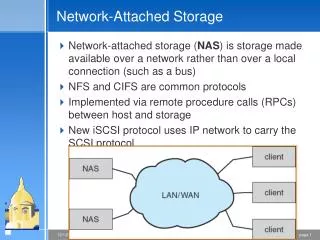
Enterprise Storage Systems • Highly reliable customized hardware • Controllers, I/O ports may become a bottleneck • Expensive • Usually not extensible • Different solutions for different scale • Example(HP): High end - XP (1152 disks), Mid range – EVA (324 disks)
Alternative – Distributed Storage • Made up of many storage nodes • Unreliable, cheap hardware • Failures are the norm, not an exception • Challenges: • Achieving reliability and consistency • Supporting reconfigurations
Distributed Storage Architecture write read • Unpredictable network delays (asynchrony) Storage Clients Cloud Storage Dynamic, Fault-prone LAN/ WAN Storage Nodes Fault-prone
A Case for Data-Centric Replication • Client-side code runs replication logic • Communicates with multiple storage nodes • Simple storage nodes (servers) • Can be network-attached disks • Not necessarily PCs with disks • Do not run application-specific code • Less fault-prone components • Simply respond to client requests • High throughput • Do not communicate with each other • If storage-nodes communicate, their failure is likely to be correlated! • Oblivious to where other replicas of each object are stored • Scalable, same storage node can be used for many replication sets not-so-thinclient thin storage node
RealSystemsAreDynamic reconfig {–C, +F,…, +I} reconfig{–A, –B} F LAN/ WAN A E G H D B C I The challenge: maintain consistency , reliability,availability
Pitfall of Naïve Reconfiguration E {A, B, C, D, E} {A, B, C, D, E} {A, B, C, D} D reconfig {+E} {A, B, C, D} {A, B, C, D, E} C delayed delayed {A, B, C, D, E} {A, B, C, D} B delayed delayed {A, B, C} {A, B, C, D} A reconfig {-D} {A, B, C} {A, B, C, D} {A, B, C} {A, B, C, D}
Pitfall of Naïve Reconfiguration E X = “Spain”, 2 X = “Italy”, 1 {A, B, C, D, E} {A, B, C, D, E} D write x “Spain” Split Brain! X = “Spain”, 2 X = “Italy”, 1 {A, B, C, D, E} C X = “Spain”, 2 X = “Italy”, 1 Returns “Italy”! {A, B, C, D, E} B X = “Italy”, 1 {A, B, C} A read x X = “Italy”, 1 {A, B, C} {A, B, C}
Reconfiguration Option 1: Centralized • Tomorrow Technion servers will be down for maintenance from 5:30am to 6:45am • Virtually Yours, • Moshe Barak • Can be automatic • E.g., Ursa Minor [Abd-El-Malek et al., FAST 05] • Downtime • Most solutions stop R/W while reconfiguring • Single point of failure • What if manager crashes while changing the system?
Reconfiguration Option 2: Distributed Agreement • Servers agree on next configuration • Previous solutions not data-centric • No downtime • In theory, might never terminate [FLP85] • In practice, we have partial synchrony so it usually works
Reconfiguration Option 3: DynaStore[Aguilera, Keidar, Malkhi, S., PODC09] • Distributed & completely asynchronous • No downtime • Always terminates • Not data-centric
In this work: DynaDiskdynamic data-centric R/W storage • First distributed data-centric solution • No downtime • Tunable reconfiguration method • Modular design, coordination is separate from data • Allows easily setting/comparing the coordination method • Consensus-based VS. asynchronous reconfiguration • Many shared objects • Running a protocol instance per object too costly • Transferring all state at once might be infeasible • Our solution: incremental state transfer • Built with an external (weak) location service • We formally state the requirements from such a service
Location Service • Used in practice, ignored in theory • We formalize the weak external service as an oracle: • Not enough to solve reconfiguration • oracle.query( ) returns some “legal” configuration • If reconfigurations stop and oracle. query() invoked infinitely many times, it eventually returns last system configuration
The Coordination Module in DynaDisk Storage devices in a configuration conf = {+A, +B, +C} A B C y x z x y y x z z next config: next config: next config: Distributed R/W objects Updated similarly to ABD Distributed “weak snapshot” object API: update(set of changes)→OK scan() → set of updates
Coordination with Consensus update : scan: read & write-back next config from majority • every scan returns +D or A B C next config: next config: next config: +D +D +D z x y x y x y z z +D +D +D Consensus –C +D reconfig({+D}) reconfig({–C})
Weak Snapshot – Weaker than consensus • No need to agree on the next configuration, as long as each process has a set of possible next configurations, and all such sets intersect • Intersection allows to converge and again use a single config • Non-empty intersection property of weak snapshot: • Every two non-empty sets returned by scan( ) intersect • Example: Client 1’s scan Client 2’s scan {+D} {+D} {–C} {+D, –C} {+D} {–C} Consensus
Coordination without consensus update : scan: read & write-back proposals from majority (twice) A B C next config: next config: next config: +D –C –C z z y y z y x 2 1 1 0 1 2 2 0 0 WRITE ({–C}, 0) OK OK CAS({–C}, , 0) CAS({–C}, , 1) +D reconfig({+D}) reconfig({–C})
Tracking Evolving Config’s • With consensus: agree on next configuration • Without consensus – usually a chain, sometimes a DAG: +D C • A,B,C,D • A, B, C • A, B, D • Inconsistent updates found and merged scan() returns {+D} weak snapshot • A,B,C,D C +D • A, B, C • A, B, D C scan() returns {+D, -C} • A,B +D • All non-empty scans intersect
Consensus-based VS. Asynch. Coordination • Two implementations of weak snapshots • Asynchronous • Partially synchronous (consensus-based) • Active Disk Paxos[Chockler, Malkhi, 2005] • Exponential backoff for leader-election • Unlike asynchronous coordination, consensus-based might not terminate [FLP85] • Storage overhead • Asynchronous: vector of updates • vector size ≤ min(#reconfigs, #members in config) • Consensus-based: 4 integers and the chosen update • Per storage device and configuration
Strong progress guarantees are not for free Slightly better,much more predictable reconfig latency when many reconfig execute simultaneously Consensus-based Asynchronous (no consensus) Significant negative effect on R/W latency The same when no reconfigurations
Future & Ongoing Work • Combine asynch. and partially-synch. coordination • Consider other weak snapshot implementations • E.g., using randomized consensus • Use weak snapshots to reconfigure other services • Not just for R/W
Summary • DynaDisk – dynamic data-centric R/W storage • First decentralized solution • No downtime • Supports many objects, provides incremental reconfig • Uses one coordination object per config. (not per object) • Tunable reconfiguration method • We implemented asynchronous and consensus-based • Many other implementations of weak-snapshots possible • Asynchronous coordination in practice: • Works in more circumstances → more robust • But, at a cost – significantly affects ongoing R/W ops