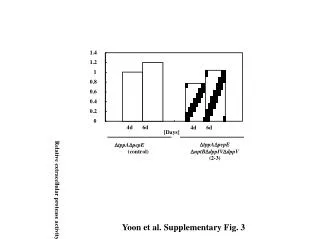
Download

1 / 34
340 likes | 487 Views
4D v11 SQL. Unicodeの手引き. Unicode (4D)といえば. Char(2) = Char(3). Char(4) = ””. Position(Char(0);”abc”)= 1. Character code(“ゔ”) # Character code(“ゔ”). Length(“ゔ”) # Length(“ゔ”). ...原理を理解することが肝心です。. Unicode 基本用語. 基本用語. コードポイント グリフ 面 サロゲート 結合文字 互換合成文字 正規化 修飾字 非文字. コードポイント. 定義.

E N D
4D v11 SQL Unicodeの手引き
Unicode (4D)といえば... Char(2)=Char(3) Char(4)=”” Position(Char(0);”abc”)=1 Character code(“ゔ”)#Character code(“ゔ”) Length(“ゔ”)#Length(“ゔ”) ...原理を理解することが肝心です。
Unicode 基本用語
基本用語 • コードポイント • グリフ • 面 • サロゲート • 結合文字 • 互換合成文字 • 正規化 • 修飾字 • 非文字
コードポイント 定義 文字の識別番号 形式 Unicodeでは, すべての文字に特有の名前と特有の番号つまりコードポイントが割り当てられている。例... 名前 : LATIN CAPITAL LETTER A 番号 : 0x41 U+ _ _ _ _ _ _ 範囲 U+0000 〜 U+10FFFF U+0000 〜 U+007F (127) = ASCII U+0000 〜 U+FFFF (65,535) = 基本 Unicode U+0000 〜 U+10FFFF (1,048,576) = 拡張 Unicode
コードポイント A U+0041 LATIN CAPITAL LETTER A あ U+3042 HIRAGANA LETTER A U+20BB7 𠮷 CJK IDEOGRAPH #20BB7
グリフ 定義 文字の画面または紙面における視覚的な表現。 同一のグリフが異なるコードポイントで使用される場合もある。
グリフ a U+0061 LATIN SMALL LETTER A a U+0430 CYRILLIC SMALL LETTER A コードポイントは言語系 (スクリプト) 別に分類されている。ラテンとキリルは別スクリプト。
グリフ 語 U+8A9E CJK IDEOGRAPH #8A8E 语 U+8BED CJK IDEOGRAPH #8BED 中国語, 日本語, 韓国朝鮮語, ベトナム語は統一スクリプト; 簡体字と繁体字は別コードポイント。
面 定義 65,535 コードポイントの集合。 全部で 16 面が定義されている。 当初の Unicode は現在の面 #0, BMP。 (Basic Multilingual Planeの略)
面 a U+0061 = 面 #0 𝄞 U+1D11E = 面 #1 𠮷 U+20BB7 = 面 #2
UTF-16 定義 2 バイト (=16 ビット) を基本単位とする Unicode の符号方式。 UTF-16 は Mac OS X および Windows XP/Vista のネイティブ文字エンコーディング。
サロゲート 定義 高次の面に位置する別のコードポイントを差している一組のBMP コードポイント。 UTF-16 で拡張 Unicode を扱うために使用する。
サロゲート U+D842 上位サロゲート 𠮷 U+20BB7 U+DFB7 下位サロゲート
組合文字 定義 文字に文字の部品を追加または調合するためのコードポイント。 ひとつの文字に任意の数の結合文字を適用することができる。
組合文字 う U+304C HIRAGANA LETTER U U+3099 COMBINING HIRAGANA KATAKANA VOICED SOUND MARK ゙ ゔ
互換合成文字 定義 BMP のコードポイントひとつで表現できる結合済みの文字。 もっぱら Unicode 以前のエンコーディングとの互換性のために存在する。
互換合成文字 う U+304C HIRAGANA LETTER U U+3099 COMBINING HIRAGANA KATAKANA VOICED SOUND MARK ゙ U+3094 ゔ HIRAGANA LETTER VU
正規化 定義 等価とみなすことができる文字列を標準の形式で統一整理する。 4 種類の正規化形式; NFC, NFCK, NFD, NFDK
正規化 ゔ ゔ U+3094 U+3094 NFD NFC NFKC NFKD ゔ ゔ U+304C U+304C U+3099 U+3099
エンディアン abc リトルエンディアン 41 00 42 00 43 00 U+0041 ビッグエンディアン U+0042 U+0043 00 41 00 42 00 43
Unicode 4Dのコマンド
Replace string 定義 自立した文字列を置換する。修飾字の評価はロケールに依存する。 非文字は空の文字 (“”) と等価。 修飾字の例 : あ 非文字の例 : e ー ´
Replace string a c U+0041 U+0000 U+0043 Char(0) を ”b” で置換 a c
Replace string(*) 定義 Unicode の規則(前後性)を無視し, 修飾字や非文字であっても, 強制的に置換する。
Replace string(*) a c U+0041 U+0000 U+0043 Char(0) を ”b” で置換 abc
Length 定義 文字列に含まれる UTF-16 コードポイントの数。 サイズ(バイト数)/2と同じ。 文字(グリフクラスタ)の数であるとは限らない。
Length ça 2 U+00E7 U+0041 ça U+0063 3 U+0323 U+0041
Position 定義 特定した文字列の前に存在するUTF-16 コードポイント数。修飾字の評価はロケールに依存する。 非文字は空の文字 (“”) と等価。
Position あー 0 U+3042 U+30FC U+00E9 éte ´ 1 U+0074 U+0065 U+0301
Position(*) 定義 Unicode の規則(前後性)を無視し, 修飾字や非文字であっても, コードポイントを扱う。
Position(*) あー 2 U+3042 U+30FC U+00E9 éte ´ 4 U+0074 U+0065 U+0301