Download

1 / 132
1.32k likes | 1.35k Views
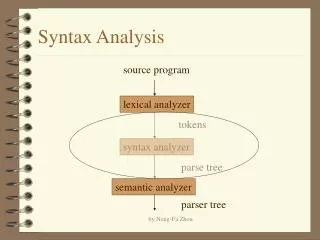
Syntax Analysis. Syntax Analysis. Introduction to parsers Context-free grammars Push-down automata Top-down parsing Buttom-up parsing Bison - a parser generator. Semantic Analyzer. Lexical Analyzer. Introduction to parsers. token. source. syntax. Parser. code. tree. next token.

E N D
Syntax Analysis • Introduction to parsers • Context-free grammars • Push-down automata • Top-down parsing • Buttom-up parsing • Bison - a parser generator
Semantic Analyzer Lexical Analyzer Introduction to parsers token source syntax Parser code tree next token Symbol Table
Context-Free Grammars • A set of terminals: basic symbols from which sentences are formed • A set of nonterminals: syntactic categories denoting sets of sentences • A set of productions: rules specifying how the terminals and nonterminals can be combined to form sentences • The start symbol: a distinguished nonterminal denoting the language
An Example • Terminals: id, ‘+’, ‘-’, ‘*’, ‘/’, ‘(’, ‘)’ • Nonterminals: expr, op • Productions:expr expropexprexpr ‘(’ expr ‘)’ expr ‘-’ expr expr idop ‘+’ | ‘-’ | ‘*’ | ‘/’ • The start symbol: expr
Derivations • A derivation step is an application of a production as a rewriting ruleE - E • A sequence of derivation stepsE - E - ( E ) - ( id ) is called a derivation of “- ( id )” from E • The symbol * denotes “derives in zero or more steps”; the symbol + denotes “derives in one or more stepsE * - ( id ) E + - ( id )
Context-Free Languages • A context-free language L(G) is the language defined by a context-free grammar G • A string of terminals is in L(G) if and only if S+, is called a sentence of G • If S*, where may contain nonterminals, then we call a sentential form of GE - E - ( E ) - ( id ) • G1 is equivalent to G2 if L(G1) = L(G2)
Left- & Right-most Derivations • Each derivation step needs to choose • a nonterminal to rewrite • a production to apply • A leftmost derivation always chooses the leftmost nonterminal to rewriteElm - Elm - ( E ) lm - ( E + E )lm - ( id + E ) lm - ( id + id ) • A rightmost derivation always chooses the rightmost nonterminal to rewriteErm - Erm - ( E ) rm - ( E + E )rm - (E +id ) rm - ( id + id )
Parse Trees • A parse tree is a graphical representation for a derivation that filters out the order of choosing nonterminals for rewriting • Many derivations may correspond to the same parse tree, but every parse tree has associated with it a unique leftmost and a unique rightmost derivation
E - E ( E ) E + E id id An Example E lm - E lm - ( E ) lm - ( E + E )lm - ( id + E ) lm - ( id + id ) E rm - E rm - ( E ) rm - ( E + E )rm - ( E +id ) rm - ( id + id )
Ambiguous Grammar • A grammar is ambiguousif it produces more than one parse tree for some sentence E E + E id + E id + E * E id + id * E id + id * id E E * E E + E * E id + E * E id + id * E id + id * id
E E E E E E * + + * E E E E id id id id id id Ambiguous Grammar
Resolving Ambiguity • Use disambiguiting rules to throw away undesirable parse trees • Rewrite grammars by incorporating disambiguiting rules into grammars
An Example • The dangling-else grammarstmt if expr then stmt| if expr then stmt else stmt| other • Two parse trees for if E1 then if E2 then S1 else S2
S if if E E then then S S if E then S else S S if E then S else S An Example
Disambiguiting Rules • Rule: match each else with the closest previous unmatched then • Remove undesired state transitions in the pushdown automaton
Grammar Rewriting stmt m_stmt| unm_stmt m_stmt ifexprthenm_stmtelsem_stmt|other unm_stmt ifexprthenstmt|ifexprthenm_stmtelseunm_stmt
RE vs. CFG • Every language described by a RE can also be described by a CFG • Why use REs for lexical syntax? • do not need a notation as powerful as CFGs • are more concise and easier to understand than CFGs • More efficient lexical analyzers can be constructed from REs than from CFGs • Provide a way for modularizing the front end into two manageable-sized components
Push-Down Automata Input $ Stack Finite Automaton Output $
(a, a) (b, a) a a 1 2 3 0 start (a, $) (b, a) ($, $) a a ($, $) An Example S’ S $ S a S bS
Nonregular Constructs • REs can denote only a fixed number of repetitions or an unspecified number of repetitions of one given construct:an, a* • A nonregular construct: • L = {anbn | n 0}
Non-Context-Free Constructs • CFGs can denote only a fixed number of repetitions or an unspecified number of repetitions of oneor two given constructs • Some non-context-free constructs: • L1 = {wcw | w is in (a | b)*} • L2 = {anbmcndm | n 1 and m 1} • L3 = {anbncn | n 0}
共勉 大學之道︰ 在明明德,在親民,在止於至善。 -- 大學
S S S S 1 2 3 4 c A B c A B c A B c A B a d a b a backtrack Top-Down Parsing • Construct a parse tree from the root to the leaves using leftmost derivation1. S c A B input: cad2. A a b 3. A a4. B d S
Predictive Parsing • A top-down parsing without backtracking • there is only one alternative production to choose at each derivation stepstmtifexprthenstmtelsestmt | whileexprdostmt | beginstmt_listend
LL(k) Parsing • The first L stands for scanning the input from leftto right • The second L stands for producing a leftmost derivation • The k stands for the number of lookahead input symbols used to choose alternative productions at each derivation step
LL(1) Parsing • Use one input symbol of lookahead • Recursive-descent parsing • Nonrecursive predictive parsing
An Example LL(1): Sab e | cd e LL(2): Sabe | ad e
Recursive Descent Parsing • The parser consists of a set of (possibly recursive) procedures • Each procedure is associated with a nonterminal of the grammar that is responsible to derive the productions of that nonterminal • Each procedure should be able to choose a unique production to derive based on the current token
An Example typesimple | id | array [ simple ] oftype simpleinteger | char | numdotdotnum {integer, char, num}
Recursive Descent Parsing • For each terminal in the production, the terminal is matched with the current token • For each nonterminal in the production, the procedure associated with the nonterminal is called • The sequence of matchings and procedure calls in processing the input implicitly defines a parse tree for the input
array [ simple ] of type num dotdot num simple integer An Example array [ numdotdotnum ] ofinteger type
An Example procedurematch(t: terminal); begin iflookahead = tthen lookahead := nexttoken elseerror end;
An Example proceduretype; begin iflookahead is in { integer, char, num } then simple else iflookahead = idthen match(id) else iflookahead = arraythen begin match(array); match('['); simple; match(']'); match(of); type end elseerror end;
An Example proceduresimple; begin iflookahead = integerthen match(integer) else iflookahead = charthen match(char) else iflookahead = numthen begin match(num); match(dotdot); match(num) end elseerror end;
First Sets • The first set of a string is the set of terminals that begin the strings derived from. If * , then is also in the first set of .
First Sets • If X is terminal, then FIRST(X) is {X} • If X is nonterminal and X is a production, then add to FIRST(X) • If X is nonterminal and X Y1Y2 ... Yk is a production, then add a to FIRST(X) if for some i, a is in FIRST(Yi) and is in all of FIRST(Y1), ..., FIRST(Yi-1). If is in FIRST(Yj) for all j, then add to FIRST(X)
An Example E T E' E' + T E' | T F T' T' * F T' | F ( E ) | id FIRST(F) = { (, id } FIRST(T') = { *, }, FIRST(T) = { (, id } FIRST(E') = { +, }, FIRST(E) = { (, id }
Follow Sets • The follow set of a nonterminal A is the set of terminals that can appear immediately to the right of A in some sentential form, namely,S *Aaa is in the follow set of A.
Follow Sets • Place $ in FOLLOW(S), where S is the start symbol and $ is the input right endmarker • If there is a production A B , then everything in FIRST() except for is placed in FOLLOW(B) • If there is a production A B or A B where FIRST() contains , then everything in FOLLOW(A) is in FOLLOW(B)
An Example E T E' E' + T E' | T F T' T' * F T' | F ( E ) | id FIRST(E) = FIRST(T) = FIRST(F) = { (, id } FIRST(E') = { +, }, FIRST(T') = { *, } FOLLOW(E) = { ), $ }, FOLLOW(E') = { ), $ } FOLLOW(T) = { +, ), $ }, FOLLOW(T') = { +, ), $ } FOLLOW(F) = { +, *, ), $ }
Nonrecursive Predictive Parsing Input Parsing driver Stack Output Parsing table
Stack Operations • Match • when the top stack symbol is a terminal and it matches the input token, pop the terminal and advance the input pointer • Expand • when the top stack symbol is a nonterminal, replace this symbol by the right hand side of one of its productions (pop the nonterminal and push the right hand side of a production in reverse order)
An Example typesimple | id | array [ simple ] oftype simpleinteger | char | numdotdotnum
An Example ActionStackInput E type array [ num dotdot num ] of integer M type of ] simple [ array array [ num dotdot num ] of integer M type of ] simple [ [ num dotdot num ] of integer E type of ] simple num dotdot num ] of integer M type of ] num dotdot num num dotdot num ] of integer M type of ] num dotdot dotdot num ] of integer M type of ] num num ] of integer M type of ] ] of integer M type of of integer E type integer E simple integer M integer integer
Parsing Driver push $S onto the stack, where S is the start symbol set ip to point to the first symbol of w$; repeat let X be the top stack symbol and a the symbol pointed to by ip; ifX is aterminalor $then ifX = athen pop X from the stack and advance ip elseerror else /* X is a nonterminal */ ifM[X, a] = XY1Y2 ... Ykthen pop X from the stack and push Yk ... Y2Y1 onto the stack elseerror untilX = $ and a = $
Constructing Parsing Table • Input. Grammar G. • Output. Parsing Table M. • Method. • For each production A , do steps 2 and 3. • 2. For each terminal a in FIRST( ), add A to M[A, a]. • 3. If is in FIRST( ), add A to M[A, b] for each • symbol b in FOLLOW(A). • 4. Make each undefined entry of M be error.
id + * ( ) $ E E TE' E TE' E' E' +TE' E' E' T T FT' T FT' T' T' T' *FT'T' T' F F id F (E) An Example FIRST(E) = FIRST(T) = FIRST(F) = { (, id } FIRST(E') = { +, }, FIRST(T') = { *, } FOLLOW(E) = { ), $ }, FOLLOW(E') = { ), $ } FOLLOW(T) = { +, ), $ }, FOLLOW(T') = { +, ), $ } FOLLOW(F) = { +, *, ), $ }
An Example Stack Input Output $E id + id * id$ $E'T id + id * id$ E TE' $E'T'F id + id * id$ T FT' $E'T'id id + id * id$ F id $E'T' + id * id$ $E' + id * id$ T' $E'T+ + id * id$ E' +TE' $E'T id * id$ $E'T'F id * id$ T FT' $E'T'id id * id$ F id $E'T' * id$ $E'T'F* * id$ T' *FT' $E'T'F id$ $E'T'id id$ F id $E'T' $ $E' $ T' $ $ E'
LL(1) Grammars • A grammar is an LL(1) grammar if its LL(1) parsing table has no multiply-defined entries