Download

1 / 20
210 likes | 526 Views
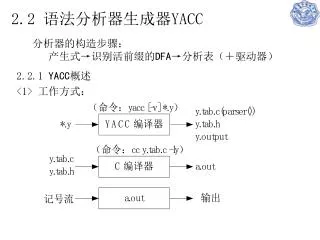
Lex & Yacc. Compilation Process. Lex. Yacc. Lexical Analyzer. Syntax Analyzer. Intermed. Code Gen. Code Generator. Machine Code. Source Code. Symbol Table. Lexical Analyzer (Scanner, Lexer). A pattern matcher Extracts lexeme in a given string Produces corresponding token

E N D
Compilation Process Lex Yacc Lexical Analyzer Syntax Analyzer Intermed. Code Gen. Code Generator Machine Code Source Code Symbol Table
Lexical Analyzer (Scanner, Lexer) • A pattern matcher • Extracts lexeme in a given string • Produces corresponding token • Detects errors in token • Front-end of a syntax analyzer • Serves as a finite state automata
Syntax Analyzer (Parser) • Checks the syntactic correctness of input string • Produces a complete parse tree or trace structure of it • In case of error displays message and tries recover to detect as many errors as it can
LEX • A tool for automatically generating a lexer or scanner given a lex specification (.l file) • A lexer or scanner is used to perform lexical analysis, or the breaking up of an input stream into meaningful units, or tokens. • Takes a set of descriptions of possible tokens (i.p. Regular expressions)
lex.yy.c is generated after running > lex x.l x.l %{ < C global variables, prototypes, comments > %} [DEFINITION SECTION] %% [RULES SECTION] %% C auxiliary subroutines This part will be embedded into lex.yy.c substitutions, code and start states; will be copied into lex.yy.c define how to scan and what action to take for each token any user code. For example, a main function to call the scanning function yylex(). Skeleton of a lex specification (.l file)
The rules section %% [RULES SECTION] <pattern> { <action to take when matched> } <pattern> { <action to take when matched> } … %% Patterns are specified by regular expressions. For example: %% [A-Za-z]* { printf(“this is a word”); } %%
The rule of lex specification file Rule section is list of rules <pattern> { corresponding actions } <pattern> { corresponding actions } … … … [1-9][0-9]* { yylval = atoi (yytext); return NUMBER; } Actions are C statements Pattern in regular expr form
Lex Reg Exp (cont) x|yx or y {i} definition of i x/yx, only if followed by y (y not removed from input) x{m,n} m to n occurrences of x xx, but only at beginning of line x$ x, but only at end of line "s" exactly what is in the quotes (except for "\" and following character) A regular expression finishes with a space, tab or newline
Meta-characters • meta-characters (do not match themselves, because they are used in the preceding reg exps): • ( ) [ ] { } < > + / , ^ * | . \ " $ ? - % • to match a meta-character, prefix with "\" • to match a backslash, tab or newline, use \\, \t, or \n
Two Rules • lex will always match the longest (number of characters) token possible. • 2. If two or more possible tokens are of the same length, then the token with the regular expression that is defined first in the lex specification is favored.
LEX Rules Disambiguation • “ali” “aliye” “[a-zA-Z]+” • Rules defined before have precedence over rules defined after • An input is matched with at most one pattern • Action for the longest possible match among the patterns executed
LEX: A Simple Example %{ /* firstlexer.l : Our First Lexer */ #include <stdio.h> }% %% [\t ]+ ; /* Ignore whitespace */ like|need|love|care {printf(“%s: verb\n”, yytext); } [a-zA-Z]+ { printf(“%s: yet not defined\n”, yytex); } .|\n { ECHO; } %% main() { yylex(); }
LEX Compilation >lex firstlexer.l #Generates lex.yy.c >cc lex.yy.c -lfl
LEX Built-in Functions & Variables • yymore() • append next string matched to current contents of yytext • yyless(n) • remove from yytext all but the first n characters • unput(c) • return character c to input stream • yywrap() • may be replaced by user • The yywrap method is called by the lexical analyser whenever it inputs an EOF as the first character when trying to match a regular expression
LEX Built-in Functions & Variables • yytext • where text matched most recently is stored • yyleng • number of characters in text most recently matched • yylval • associated value of current token • yyin - points current file parsed by the lexer • yyout - points file that output of the lexer will be written