Download

1 / 44
530 likes | 997 Views
Beowulf. Pēteris Lediņš University of Latvia Nov 16, 2004. What is Beowulf. Historically

E N D
Beowulf Pēteris Lediņš University of Latvia Nov 16, 2004
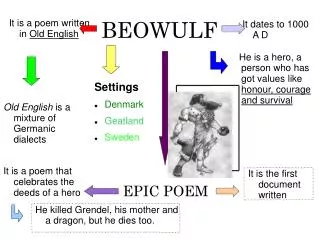
What is Beowulf • Historically Beowulf is the earliest surviving epic poem written in English. It is a story about a hero of great strength and courage who defeated a monster called Grendel. See History to find out more about the Beowulf hero. Famed was this Beowulf: far flew the boast of him, son of Scyld, in the Scandian lands. So becomes it a youth to quit him well with his father's friends, by fee and gift, that to aid him, aged, in after days, come warriors willing, should war draw nigh, liegemen loyal: by lauded deeds shall an earl have honor in every clan. • Computer related • The Beowulf architecture was first introduced by scientists(Thomas Sterling and Don Becker) at NASA who were trying to develop a supercomputer class of machine using inexpensive off-the-shelf computer technology.
COW • COW – cluster of Workstations • A set of computers with one server with user /home and /usr/local directories via NFS. • All clients have local *nix installed with rsh – remote shell • Workstations used by people at day, by computing processes at nights.
COW vs Beowulf • Ordinary nodes of Beowulf have no videocards, keyboards, etc. • Users see Beowulf as one computer • Global PID • Beowulf is dedicated for parallel computing
Beowulf vs. <openMosix|many processor server> • openMosix – in openMosix parallel computing supplied by kernel. Beowulf’s approach based on messaging between instances of process. • Many processor server – with Beowulf you have to different memory spaces, with many processor server – one memory space by hardware.
More or less precise def. The accepted definition of a true beowulf is that it is a cluster of computers (``compute nodes'') interconnected with a network with the following characteristics: • The nodes are dedicated to the beowulf and serve no other purpose. • The network(s) on which the nodes reside is(are) dedicated to the beowulf and serve(s) no other purpose. • An essential part of the beowulf definition (that distinguishes it from, for example a vendor-produced massively parallel processor - MPP - system) is that its compute nodes are mass produced commodities, readily available ``off the shelf'', and hence relatively inexpensive. • Ordinary network - at least to the extent that it must integrate with popular computers and hence must interconnect through a standard bus. The nodes all run open source software. • The resulting cluster is used for High Performance Computing (HPC, also called ``parallel supercomputing'' and other names).
Hardware classification • From Beowulf how-to: • A CLASS I Beowulf is a machine that can be assembled from parts found in at least 3 nationally/globally circulated advertising catalogs – “Computer shopper test” • A CLASS II Beowulf is simply any machine that does not pass the Computer Shopper certification test
Beowulfery • Explore the possibilities of building supercomputers out of the mass-market electronic equivalent of coat hangers and chewing gum. • Open source • Specific tasks – no standard solution • Beowulf design is best driven (and extended) by one's needs of the moment and vision of the future and not by a mindless attempt to slavishly follow the original technical definition anyway.
Software • Building clusters is straightforward, but managing its software can be complex. • Oscar (Open Source Cluster Application Resources) • Scyld – scyld.com from the scientists of NASA - commercial • true beowulf in a box • Beowulf Operating System • Rocks • OpenSCE • WareWulf • Clustermatic
OSCAR • http://oscar.openclustergroup.org/ • Cluster on a CD – automates cluster install process • Wizard driven • Can be installed on any Linux system, supporting RPMs • Components: Open source and BSD style license
Rocks • Award Winning Open Source High Performance Linux Cluster Solution • The current release of NPACI Rocks is 3.3.0. • Rocks is built on top of RedHat Linux releases • Two types of nodes • Frontend • Two ethernet interfaces • Lots of disk space • Compute • Disk drive for caching the base operating environment (OS and libararies) • Rocks uses an SQL database for global variable saving
Rocks frontend installation • 3 CD’s – • Rocks Base CD, HPC Roll CD and Kernel Roll CD • Bootable Base CD • User-friendly wizard mode installation • Cluster information • Local hardware • Both ethernet interfaces
Rocks compute nodes • Installation • Login frontend as root • Run insert-ethers • Run a program which captures compute node DHCP requests and puts their information into the Rocks MySQL database
Rocks compute nodes • Use install CD to boot the compute nodes • Insert-ethers also authenticates compute nodes. When insert-ethers is running, the frontend will accept new nodes into the cluster based on their presence on the local network. Insert-ethers must continue to run until a new node requests its kickstart file, and will ask you to wait until that event occurs. When insert-ethers is off, no unknown node may obtain a kickstart file.
Rocks compute nodes • Monitor installation • When finished do next node • Nodes divided in cabinets • Possible to install compute nodes of different architecture than frontend
MPI • MPI is a software systems that allows you to write message-passing parallel programs that run on a cluster, in Fortran and C. • MPI (Message Passing Interface) is a defacto standard for portable message-passing parallel programs standardized by the MPI Forum and available on all massively-parallel supercomputers.
Parallel programming • Mind that memory is distributed – each node has its own memory space • Decomposition – divide large problems into smaller • Use mpi.h for C programs
Message passing • Message Passing Program consists of multiple instance of serial program that communicate bylibrary calls. These calls may be roughly divided into four classes: • Calls used to initialise, manage and finally terminate communication • Calls used to communicate between pairs of processors • Calls that communicate operations among group of processors • Calls used to create arbitrary data type
Helloworld.c #include <stdio.h> #include <mpi.h> int main(int argc, char *argv[]) { int rank, size; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &size); printf("Hello world! I am %d of %d\n", rank, size); MPI_Finalize(); return(0); }
Communication /* * The root node sends out a message to the next node in the ring and * each node then passes the message along to the next node. The root * node times how long it takes for the message to get back to it. */ #include<stdio.h> /* for input/output */ #include<mpi.h> /* for mpi routines */ #define BUFSIZE 64 /* The size of the messege being passed */ main( int argc, char** argv) { double start,finish; int my_rank; /* the rank of this process */ int n_processes; /* the total number of processes */ char buf[BUFSIZE]; /* a buffer for the messege */ int tag=0; /* not important here */ MPI_Status status; /* not important here */ MPI_Init(&argc, &argv); /* Initializing mpi */ MPI_Comm_size(MPI_COMM_WORLD, &n_processes); /* Getting # of processes */ MPI_Comm_rank(MPI_COMM_WORLD, &my_rank); /* Getting my rank */
Communication again /* * If this process is the root process send a messege to the next node * and wait to recieve one from the last node. Time how long it takes * for the messege to get around the ring. If this process is not the * root node, wait to recieve a messege from the previous node and * then send it to the next node. */ start=MPI_Wtime(); printf("Hello world! I am %d of %d\n", my_rank, n_processes); if( my_rank == 0 ) { /* send to the next node */ MPI_Send(buf, BUFSIZE, MPI_CHAR, my_rank+1, tag, MPI_COMM_WORLD); /* receive from the last node */ MPI_Recv(buf, BUFSIZE, MPI_CHAR, n_processes-1, tag, MPI_COMM_WORLD, &status); }
Even more of communication if( my_rank != 0) { /* receive from the previous node */ MPI_Recv(buf, BUFSIZE, MPI_CHAR, my_rank-1, tag, MPI_COMM_WORLD, &status); /* send to the next node */ MPI_Send(buf, BUFSIZE, MPI_CHAR, (my_rank+1)%n_processes, tag, MPI_COMM_WORLD); } finish=MPI_Wtime(); MPI_Finalize(); /* I’m done with mpi stuff */ /* Print out the results. */ if (my_rank == 0) { printf("Total time used was %f seconds\n", finish-start); } return 0; }
Compiling • Compile code using mpicc – MPI C compiler. • /u1/local/mpich-pgi/bin/mpicc -o helloworld2 helloworld2.c • Run using mpirun.
Rocks computing • Mpirun on Rocks clusters is used to launch jobs that are linked with the Ethernet device for MPICH. • "mpirun" is a shell script that attempts to hide the differences in starting jobs for various devices from the user. On workstation clusters, you must supply a file that lists the different machines that mpirun can use to run remote jobs • MPICH is an implementation of MPI, the Standard for message-passing libraries.
Rocks computing example • High-Performance Linpack • software package that solves a (random) dense linear system in double precision (64 bits) arithmetic on distributed-memory computers. • Launch HPL on two processors: • Create a file in your home directory named machines, and put two entries in it, such as: • compute-0-0 • compute-0-1 • Download the the two-processor HPL configuration file and save it as HPL.dat in your home directory. • Now launch the job from the frontend: • $ /opt/mpich/gnu/bin/mpirun -nolocal -np 2 -machinefile machines /opt/hpl/gnu/bin/xhpl
Rocks cluster-fork • Same jobs of standard Unix commands on different nodes • By default, cluster-fork uses a simple series of ssh connections to launch the task serially on every compute node in the cluster. • My processes on all nodes: • $ cluster-fork ps -U$USER • Hostnames of nodes: • $ cluster-fork ps -U$USER
Rocks cluster-fork again • Often you wish to name the nodes your job is started on • $ cluster-fork --query="select name from nodes where name like 'compute-1-%'" [cmd] • Or use --nodes=compute-0-%d:0-2
Sun Grid Engine • Rocks ships with Sun Grid Engine • Grid Engine is Distributed Resource Management (DRM) software. • optimally place computing tasks and balance the load on a set of networked computers • allow users to generate and queue more computing tasks than can be run at the moment • ensure that tasks are executed with respect to priority and to providing all users with a fair share of access over time
Rocks and Grid engine • Jobs are submitted to Grid Engine via scripts • Give parameters for the processes to be executed and how should they be executed • Run script: qsub testjob.sh • Query status: qstat -f • STDOUT, STDERR output is kept in files using name of the script that is run
Grid Engine output • Grid Engine puts the output of job into 4 files. • $HOME/sge-qsub-test.sh.o<job id> for (STDOUT messages) • $HOME/sge-qsub-test.sh.e<job id> (STDERR messages). • The other 2 files pertain to Grid Engine status and they are named: • $HOME/sge-qsub-test.sh.po<job id> (STDOUT messages) • $HOME/sge-qsub-test.sh.pe<job id> (STDERR messages)
testjob.sh #!/bin/bash #$ -S /bin/bash # # Set the Parallel Environment and number of procs. #$ -pe mpi 2 # Where we will make our temporary directory. BASE="/tmp" # make a temporary key export KEYDIR=`mktemp -d $BASE/keys.XXXXXX` # Make a temporary password. // Makepasswd is quieter, and presumably more efficient. //We must use the -s 0 flag to make sure the password contains no quotes. if [ -x `which mkpasswd` ]; then export PASSWD=`mkpasswd -l 32 -s 0` else export PASSWD=`dd if=/dev/urandom bs=512 count=100 | md5sum | gawk '{print $1}'` fi
testjob.sh /usr/bin/ssh-keygen -t rsa -f $KEYDIR/tmpid -N "$PASSWD" cat $KEYDIR/tmpid.pub >> $HOME/.ssh/authorized_keys2 # make a script that will run under its own ssh-agent # cat > $KEYDIR/launch-script <<"EOF" #!/bin/bash expect -c 'spawn /usr/bin/ssh-add $env(KEYDIR)/tmpid' -c \ 'expect "Enter passphrase for $env(KEYDIR)/tmpid" \ { send "$env(PASSWD)\n" }' -c 'expect "Identity"' echo # Put your Job commands here. #------------------------------------------------ /opt/mpich/gnu/bin/mpirun -np $NSLOTS -machinefile $TMPDIR/machines \ /opt/hpl/gnu/bin/xhpl #------------------------------------------------ EOF chmod u+x $KEYDIR/launch-script
testjob.sh # start a new ssh-agent from scratch -- make it forget previous ssh-agent connections unset SSH_AGENT_PID unset SSH_AUTH_SOCK /usr/bin/ssh-agent $KEYDIR/launch-script # # cleanup # grep -v "`cat $KEYDIR/tmpid.pub`" $HOME/.ssh/authorized_keys2 \ > $KEYDIR/authorized_keys2 mv $KEYDIR/authorized_keys2 $HOME/.ssh/authorized_keys2 chmod 644 $HOME/.ssh/authorized_keys2 rm -rf $KEYDIR
Monitoring Rocks • Set of web pages to monitor activities and configuration • Apache webserver with access from internal network only • From outside - viewing webpages involves sending a web browser screen over a secure, encrypted SSH channel – • ssh frontendsite, start Mozilla there, see http://localhost • mozilla --no-remote • Access from public network (not recommended) • Modify IPtables
Rocks monitoring pages Should look like this:
More monitoring through web • Access through web pages includes PHPMyAdmin for SQL server • TOP command for cluster • Graphical monitoring of cluster • Ganglia is a scalable distributed monitoring system for high-performance computing systems such as clusters and Grids.
Default services • 411 Secure information service • Distribute files to nodes – password changes, login files • In cron – run every hour • DNS for local communication • Postfix mail software
Sources • http://www.tldp.org/HOWTO/Beowulf-HOWTO.html • http://www.cs.iusb.edu/beowulf.html • Indiana University South Bend • http://www.beowulf.org • http://www.rocksclusters.org/Rocks/ • NPACI Rocks Cluster Distribution: Users Guide • http://www.phy.duke.edu/~rgb/Beowulf/beowulf_book/beowulf_book/index.html • http://www.scyld.com/ • http://www.ganglia.info • http://www.sci.hkbu.edu.hk/mscsc/lab/cluster/cluster1.pdf