Download

1 / 55
610 likes | 1.25k Views
UNIT - 2. SYNTAX ANALYSIS - 1. OBJECTIVES. The Role of Parser Context Free Grammars Writing a Grammar Parsing – Top Down and Bottom Up Simple LR Parser Powerful LR Parser Using Ambiguous Grammars Parser Generators. Syntax Analysis and Parsing. Syntax

E N D
UNIT - 2 SYNTAX ANALYSIS - 1 -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
OBJECTIVES • The Role of Parser • Context Free Grammars • Writing a Grammar • Parsing – Top Down and Bottom Up • Simple LR Parser • Powerful LR Parser • Using Ambiguous Grammars • Parser Generators -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
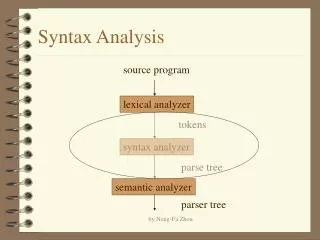
Syntax Analysis and Parsing • Syntax • The way in which words are stringed together to form phrases, clauses and sentences • Syntax Analysis • The task concerned with fitting a sequence of tokens into a specified sequence • Parsing • To break a sentence down into its component parts with an explanation of the form, function, and syntactical relationship of each part -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Syntax Analysis • Every PL has rules that describe the syntactic structure of well-formed programs • In C, a program is made up of functions, declarations, statements etc • Syntax can be specified using context-free grammars or BNF • Grammars offer benefits to both designers & compiler writers • Gives precise yet easy-to-understand syntactic specification of PL’s • Helps construct efficient parsers automatically • Provides a good structure to the language which in turn helps generate correct object code • Allows a language to be evolved iteratively by adding new constructs to perform new tasks -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
The Role of a Parser • Parser obtains a string of tokens from the lexical analyzer • Verifies that the string of token names can be generated by the grammar • Constructs a parse tree and passes it to the rest of the compiler • Reports errors when the program does not match the syntactic structure of the source language -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Parsing Methods • Universal Parsing Method • Can parse any grammar, but too inefficient to use in any practical compilers • Example: Earley’s Algorithm • Top-Down Parsing • Build parse trees from the root to the leaves • Can be generated automatically or written manually • Example : LL Parser • Bottom-Up Parsing • Starts from the leaves and work their way up to the root • Can only be generated automatically • Example : LR Parser -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Representative Grammars • Some of the grammars used in the discussion • LR grammar for bottom-up parsing E E + T | T T T * F | F F ( E ) | id • Non-recursive variant of the grammar E T E` E` + T E` | ε T F T` T * F T` | ε F ( E ) | id -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Syntax Error Handling • A compiler must locate and track down errors but the error handling is left to the compiler designer • Common PL errors at many different levels • Lexical Errors • Misspellings of identifiers, keywords or operators • Syntactic Errors • Misplaced semicolons or extra or missing braces, that is “{“ or “}” • Semantic Errors • Type mismatches between operators and operands • Logical Errors • Incorrect reasoning by the programmer or use of assignment operator (=) instead of comparison operator (==) -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Syntax Error Handling • Parsing methods detect errors as soon as possible, i.e., when stream of tokens cannot be parsed further • Have the viable-prefix property • Detect an error has occurred as soon as a prefix of the input that cannot be completed to form a string is seen • Errors appear syntactic and are exposed when parsing cannot continue • Goals of error handler in a parser • Report the presence of errors clearly and accurately • Recover from each error quickly enough to detect subsequent errors • Add minimal overhead to the processing of correct programs -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Error-Recovery Strategies • How should the parser recover once an error is detected? • Quit with an informative error message when it detects the first error • Additional errors are uncovered if parser can restore to a state where processing of the input can continue • If errors pile up, its better to stop after exceeding some error limit • Four error-recovery strategies • Panic-Mode Recovery • Phrase-Level Recovery • Error Productions • Global Correction -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Error-Recovery Strategies • Panic-Mode Recovery • Parser discards input symbols one at a time until one of a designated set of synchronizing tokens is found • Synchronizing tokens – delimiters like semicolon or “}” • Compiler designer must select the synchronizing tokens appropriate for the source language • Advantage of simplicity and is guaranteed not to go into an infinite loop • Phrase-Level Recovery • Perform local correction on remaining input, that is, may replace a prefix of the remaining input by some string that allows the parser to continue • Choose replacements that do not lead to infinite loops • Drawback is the difficulty to cope up with situations in which actual error has occurred before the point of detection -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Error-Recovery Strategies • Error Productions • Anticipate the common errors that might be encountered • Augment grammar for language with productions that generate erroneous constructs • Such a parser detects anticipated errors when error production is used during parsing • Global Correction • Make as few changes in processing an incorrect input string • Use algorithms for choosing a minimal sequence of changes to obtain a globally least-cost correction • Given an incorrect input string x and grammar G, these algorithms find a parse tree for a related string y, such that the number of changes required to transform x to y is small • Too costly to implement in terms of time and space -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Context-Free Grammars- Formal Definition • A context-free grammar G= (T, N, S, P) consists of: • T, a set of terminals (scanner tokens - symbols that may not appear on the left side of rule,). • N, a set of nonterminals(syntactic variables generated by productions – symbols on left or right of rule). • S, a designated start symbol nonterminal. • P, a set of productions (Rules). Each production consists of • A nonterminal called the left side of the production • The symbol • A right side consisting of zero or more terminals and non-terminals -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Context-Free Grammars- Formal Definition • Example grammar for simple arithmetic expressions expression expression + term expression expression – term expression term term term * factor term term / factor term factor factor ( expression ) factor id -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Notational Conventions • Terminal symbols • Lowercase letters early in the alphabet like a,b,c • Operator symbols such as +, * • Punctuation symbols such as parentheses, and comma • Digits 0,1,….,9 • Nonterminal symbols • Uppercase letters early in the alphabet like A,B,C • Letter S, which, when used stands for the start symbol • Lowercase letters late in the alphabet like u,v,..z represent string of terminals • Uppercase letters late in the alphabet such as X, Y, Z represent grammar symbols that is either terminal or nonterminal -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Notational Conventions • Lower case Greek letters α, β, γrepresent strings of grammar symbols • If A → α1 ,, A → α2 …….. A → αn are all Productions with A on the LHS ( known as A-productions), then, A → α1 | α2 …| αn (α1 , α2 … αn are alternatives of A) • Unless otherwise stated , the LHS of the first production is the start nonterminals • Example: previous grammar written using these conventions E E + T | E – T | T T T * F | T / F | F F ( E ) | id` -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Derivations • A way of showing how an input sentence is recognized with a grammar • Beginning with the start symbol, each rewriting step replaces a nonterminal by the body of one of its productions • Consider the following grammar E E + E | E * E | – E | ( E ) | id • “E derives –E” can be denoted by E ==> – E • A derivation of – ( id ) from E E ==> – E ==> – ( E ) ==> – ( id) -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Derivations • Symbols to indicate derivation • ==> denotes “derives in one step” • ==> denotes “derives in zero or more steps” • ==> denotes “derives in one or more steps” • Given the grammar G with start symbol S, a string ω is part of the language L (G), if and only if S ==> ω • If S ==> α and αcontains • Only terminals then it is a sentence of G • Both terminals and nonterminals then it is a Sentential form of G • Two choices to be made at each step in the derivation • Choose which nonterminal to replace • Pick a production with that nonterminal as head * + * * -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Derivations • Leftmost Derivation • The leftmost nonterminal in each sentential form is always chosen to be replaced • If α==> β, is a step in which the leftmost nonterminal in αis replaced, we write α==> β • Rightmost Derivation • Replace the rightmost nonterminal in each sentential form • Written as α==> β • If S ==> α, then we can say that αis left-sentential form of the grammar lm rm * lm -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Parse Trees and Derivations • A graphical representation for a derivation showing how to derive the string of a language from grammar starting from Start symbol • The interior node is labeled with the nonterminal in the head of the production • Children are labeled by the symbols in the RHS of the production • Yield of the tree • The string derived or generated from the nonterminal at the root of the tree • Obtained by reading the leaves of the parse tree from left to right -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Parse Trees and Derivations Fig: Parse tree for – (id +id) -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Ambiguity • A grammar that produces more than one parse tree for some sentence is said to be ambiguous • Can be a leftmost derivation or a rightmost derivation for the same sentence Fig: Two Parse trees for id+id*id -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
CFG’s Versus Regular Expressions • Every construct that can be described by a regular expression can be described by a grammar, but not vice-versa. • Grammar construction from the NFA • For each state i of the NFA, create a nonterminalAi • If state i has a transition to state j on input a, add the production Ai aAj If state i goes to state j on input ε, add the production Ai Aj • If i is an accepting state, add Ai ε • If i is the start state, make Ai the start symbol of the grammar -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Exercises -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
-Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Writing a Grammar • Lexical versus Syntactic Analysis • Why use RE’s to define lexical syntax of a language? • Separating syntactic structure into lexical and non-lexical parts modularizes a compiler into two components • Lexical rules are simple and easy to describe • RE’s provide a concise and easier-to-understand notation for tokens than grammars • Efficient lexical analyzers can be constructed automatically from RE’s than from arbitrary grammars • RE’s are most useful for describing the structure of constructs such as identifiers, constants, keywords and whitespace • Grammars are useful for describing nested structures such as balanced parentheses, matching begin-end’s, corresponding if-then-else’s -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Eliminating Ambiguity • Ambiguous grammars can be rewritten to eliminate ambiguity • Example : “Dangling-else” grammar stmt ifexprthenstmt | if exprthenstmt elsestmt | other • Parse tree for the statement: if E1 then S1 else if E2 then S2else S3 -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Eliminating Ambiguity • Grammar is ambiguous since the following string has two parse trees if E1 then if E2 then S1else S2 -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Eliminating Ambiguity • Rewriting the “dangling-else” grammar • General rule is, “Match each else with the closest unmatched then” • Idea is that statement appearing between a then and else must be “matched” • That is, each interior statement must not end with an unmatched or open then • A matched statement is either an if-then-else statement containing no open statements or any other kind of unconditional statement -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Eliminating Left Recursion • Left-recursive grammar • Grammar that has a nonterminal A such that there is a derivation A ==>A for some string • Top-down parsing methods cannot handle left-recursive grammars • Immediate Left recursion : a production of the form A A • Left-recursive pair of productions, A A | βcan be replaced by: A βA′ A′ A′ | ε • Eliminating immediate left recursion • First group the A-productions as A A1 | A2 | . . . | Am | β1 | β2 | . . . | βn Where no βibegins with an A • Replace the A-productions by A β1 A′ | β2 A′ | . . . | βn A′ A 1 A′ | 2 A′ | . . . | m A′ | ε + -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Eliminating Left Recursion • Algorithm to eliminate left recursion from a grammar -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Left Factoring • When choice between two alternative A-productions is not clear, • We rewrite the grammar to defer the decision until enough of the input has been seen • Two productions as below: • In general, if A αβ1 | αβ2 are two A-productions • We do not know whether to expand A to αβ1 or αβ2 • Defer the decision by expanding A to αA′ • After seeing the input derived from α, we expand Á toβ1or to β2 • Left-factored the original productions become A α A′ A′ β1 | β2 -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Left Factoring • Algorithm for left-factoring a grammar • For each nonterminalA, find the longest prefix αcommon to two or more alternatives • If α ≠ ε – replace all of the A-productions A αβ1 | αβ2 | . . . | αβn | γ, where γ represents alternatives that do not begin with α, by A αA′ | γ A′ β1 | β2 | . . . | βn • Repeatedly apply this transformation until no two alternatives for a nonterminal have a common prefix -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Non-Context Free Language Constructs • Some syntactic constructs found in PL cannot be specified using grammars alone • Example 1: Problem of checking that identifiers are declared before they are used in the program The abstract language is L1 = {wcw | w is in (a|b)*} • Example 2: Problem of checking that number of formal parameters in the declaration of a function agrees with the number of actual parameters in a use of the function The abstract language is L2 = {anbmcndm | n ≥ 1 and m ≥ 1} -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Top-Down Parsing • Constructing a parse tree for the input string starting from the toot and creating nodes in preorder • Can be viewed as finding a leftmost derivation for an input string • Consider the grammar below E T E′ E′ + T E′ | ε T F T′ T′ * F T′ | ε F ( E ) | id Sequence of parse trees for the input id+id*id -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Top-Down Parsing -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Top-Down Parsing • Determining the production to be applied for a nonterminalA is the key problem at each step of top-down parse • Once an A-production is chosen, the parsing process consists of “matching” the terminal symbols in production with input string • Two types • Recursive-descent parsing • May require backtracking to find the correct A-production to be applied • Predictive Parsing • No backtracking is requires • Chooses the correct A-production by looking ahead at the input a fixed number of symbols • LL(k) Grammars : Construct predictive parsers that look k symbols ahead in the input -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Recursive-Descent Parsing • The parsing program consists of a set of procedures, one for each nonterminal • Execution begins with the procedure for the start symbol, which halts and announces success if its procedure body scans the input -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Recursive-Descent Parsing • To allow backtracking, the code needs to be modified • Cannot choose a unique A-production at line (1), so must try each of the several productions in some order • Failure at line (7) is not ultimate failure, but tells that we need to return to line (1) and try another A-production • Only if there are no more A-productions to try, we declare that an input error has been found • To try another A-production, we need to be able to reset the input pointer to where it was when we first reached line (1) • A local variable is needed to store this input pointer -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Recursive-Descent Parsing • Consider the grammar: S c A d A a b | a And input string w = cad -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
FIRST and FOLLOW • During parsing, FIRST and FOLLOW allow us to choose which production to apply, based on the next input symbol • FIRST(α) • Set of terminals that begin strings derived from α. If α derives ε, then ε is also in FIRST(α) • Example : A ==> c γ, so c is in FIRST(A) • Consider two A-productions A α | β, where FIRST(α) and FIRST(β) are disjoint sets • Choose between these by looking at the next input symbol a, since a can be in at most one of FIRST(α) and FIRST(β) , not both * -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
FIRST and FOLLOW • FOLLOW(A), for a nonterminalA • Set of terminals a that can appear immediately to the right of A in some sentential form • That is, set of terminals a such that there exists a derivation of the form S ==>αAaβ • If A can be the rightmost symbol in some sentential form, then $ is in FOLLOW(A) * -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
FIRST and FOLLOW • To compute FIRST(X), apply following rules until no more terminals or ε can be added to any FIRST set • If X is a terminal, then FIRST(X) = { X } • If X is a nonterminal and X Y1Y2 . . . Ykis a production for some k≥1 • Place a in FIRST(X) if for some i, a is in FIRST(Yi) , and εis in all of FIRST(Y1), . . . , FIRST(Yi-1); i.e., Y1. . . Yi-1 ==> ε • If ε is in FIRST(Yj) for all j = 1, 2, . . ., k, then add ε to FIRST(X) • If Y1does not derive ε, then we add nothing more to FIRST(X), but if Y1 ==> ε, then we add FIRST(Y2) and so on • If X ε is a production, then add εto FIRST(X) * * -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
FIRST and FOLLOW • To compute FOLLOW(A) for all nonterminalsA, apply following rules until nothing can be added to any FOLLOW set • Place $ in FOLLOW(S), where S is the start symbol, and $ is the input right endmarker • If there is production , A αBβ, then everything in FIRST(β) except ε is in FOLLOW(B) • If there is a production, A αB, or a production A αBβ, where FIRST(β) contains ε, then everything in FOLLOW(A) is in FOLLOW(B) -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
LL(1) Grammars • Predictive parsers needing no backtracking are constructed for a class of grammars called LL(1) grammars • First “L” stands for scanning the input from left to right • Second “L” stands for producing a leftmost derivation • “1” for using one input symbol of look ahead at each step to make parsing decisions • A grammar G is LL(1) if and only if whenever A α | β , are two distinct productions, the following hold: • For no nonterminala do both αandβderive strings beginning with a • At most one of αandβcan derive the empty string • If β ==> ε, then α does not derive any string beginning with a terminal in FOLLOW(A). Likewise, if α ==> ε, then β does not derive an string beginning with a terminal in FOLLOW(A) * * -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
LL(1) Grammars • Predictive parsers can be constructed for LL(1) grammars since the proper production to apply can be selected by looking only at the current input symbol • Next algorithm collects information from FIRST and FOLLOW sets • Into a predictive parsing table M[A,a], where A is the nonterminal and a is terminal • IDEA • Production A αis chosen if the next input symbol a is in FIRST(α) • If α = ε, we again choose A α , if the current input symbol is in FOLLOW(A), or if the $ on the input has been reached and $ is in FOLLOW(A) -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
LL(1) Grammars Algorithm: Construction of Predictive Parsing Table Input : Grammar G Output: Parsing Table M Method : For each production A αof the grammar do the • For each terminal a in FIRST(A), add A αto M[A,a]. • If ε is in FIRST(α), then for each terminal b in FOLLOW(A), add A α to M[A,b]. If ε is in FIRST(α) and $ is in FOLLOW(A), add A α to M[A,$] as well If after performing the above, there is no production at all in M[A,a], then set M[A,a] to error -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Nonrecursive Predictive Parsing • Built by maintaining a stack explicitly rather than recursive calls • Parser mimics a leftmost derivation • If w is the input that has been matched so far, then the stack holds a sequence of grammar symbols α such that S ==> w α * lm -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Nonrecursive Predictive Parsing -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers
Nonrecursive Predictive Parsing -Compiled by: Namratha Nayak www.Bookspar.com | Website for Students | VTU - Notes - Question Papers