Download
1 / 24
240 likes | 469 Views
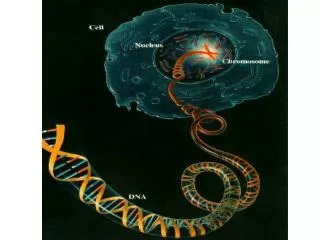
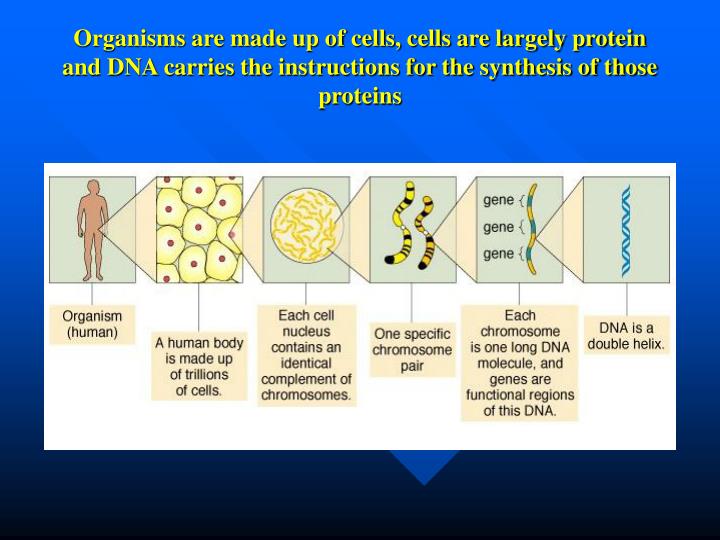
Organisms are made up of cells, cells are largely protein and DNA carries the instructions for the synthesis of those proteins. DNA is made up of subunit building blocks called nucleotides. Nucleotides are joined into chains and two such chains associate with eachother by base pairing.

E N D
Organisms are made up of cells, cells are largely protein and DNA carries the instructions for the synthesis of those proteins
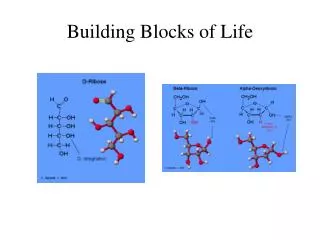
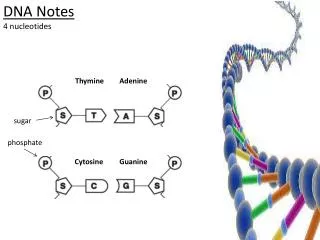
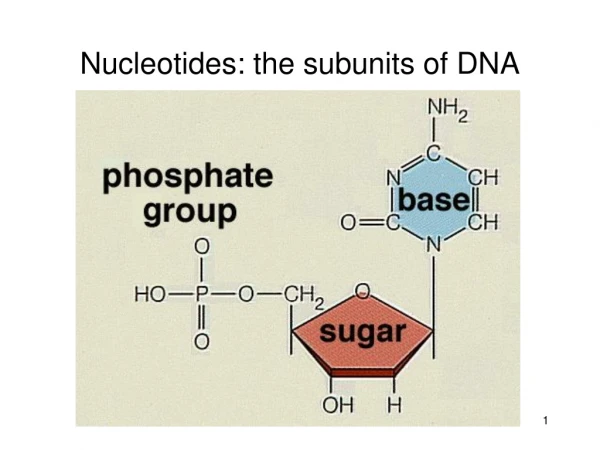
DNA is made up of subunit building blocks called nucleotides
Nucleotides are joined into chains and two such chains associate with eachother by base pairing
The sequence information in DNA is copied into RNA (mRNA) which then directs protein synthesis
Amino acid assembly during translation occurs on ribosomes; tRNA serves as the crucial adaptor molecule
Proteins are composed of subunits called amino acids; mRNA directs the synthesis of an amino acid polymer
Rare mutations in DNA are changes in its nucleotide sequence, leading to an altered mRNA and an altered protein
A brief overview of the human genome • Size = 3x109 base pairs (bp), A paired with T and G paired with C, distributed over 23 chromosomes (this is for a haploid, or germ cell; double those numbers for a diploid somatic cell) • Nucleotide changes occur in DNA via mutations; the spontaneous mutation rate is approx. 10-8 per germ cell per year • Base composition: 40% GC base pairs; less than 2% in the format CpG; this is b/c of mutation at such sites, CpG -> TpG, especially so when C is methylated • Genic content of our genome: 3-5% of genome = “genes”; this represents about 1.5x107 bp and includes approx. 40,000 genes • What’s in the remaining 95% of the genome? About 40% is retroelements, remnants of retroviruses (much like computer viruses). Retroelements are usually highly methylated at the C in CpG doublets • About 30% of the genome = variable, simple repeat sequences in DNA
Genes include both coding regions as well as control regions
Consensus sequences identify evolutionarily conserved sequences that are likely to be important; eg, the promoter
Overview of the Prokaryotic Promoter Region Promoter Met -10 TATAa +1 ATG
Eukaryotic Promoter Structure Met TATAaA ATG A -30 +1 ACCATGG +50 Alternative promoter structures Initiator (Inr) YY A N T/A YYY +1 CpG Islands (CpG)20-50-----+1
Some general landmarks that characterize transcription and translation
Genomic DNA cDNA mRNA aa1-aa2-aa(n)
G G TATAa……..ATG GU…..AG Start Intron #1 GU………AGG UAA UAA……..AAUAAA G Poly A tail Intron (n) STOP
Repetitive DNA sequences comprise much of the non-coding segment of the genome 30% 1-3%
A brief overview of the human genome • Size = 3x109 base pairs (bp), A paired with T and G paired with C, distributed over 23 chromosomes (this is for a haploid, or germ cell; double those numbers for a diploid somatic cell) • Nucleotide changes occur in DNA via mutations; the spontaneous mutation rate is approx. 10-8 per germ cell per year • Base composition: 40% GC base pairs; less than 2% in the format CpG; this is b/c of mutation at such sites, CpG -> TpG, especially so when C is methylated • Genic content of our genome: 3-5% of genome = “genes”; this represents about 1.5x107 bp and includes approx. 40,000 genes • What’s in the remaining 95% of the genome? About 40% is retroelements, remnants of retroviruses (much like computer viruses). Retroelements are usually highly methylated at the C in CpG doublets • About 30% of the genome = variable, simple repeat sequences in DNA
Gene identification can begin with mRNA isolation and formation of copy DNA (cDNA)
Large-scale gene analysis can be performed using DNA microarrays, or chips
Human CF gene, approx. 250kb 4kb Approx. 1 mutation per 1kb in noncoding regions; if 80% of the genome is noncoding: 3x109bp x 0.8 = 2.4x109 x 1/1,000 = 2.4x106 mut. differing between any two individuals