Download

1 / 24
240 likes | 352 Views
DNA Classifications with Self-Organizing Maps (SOMs). Thanakorn Naenna Mark J. Embrechts Robert A. Bress. May 2003 IEEE International Workshop on Soft Computing in Industrial Application. Presentation Outline. Introduction to DNA Splice Junctions Data Collection Introduction to SOMs

E N D
DNA Classifications with Self-Organizing Maps (SOMs) Thanakorn Naenna Mark J. Embrechts Robert A. Bress May 2003 IEEE International Workshop on Soft Computing in Industrial Application
Presentation Outline • Introduction to DNA Splice Junctions • Data Collection • Introduction to SOMs • SOM for DNA Splice Junction Classification • Results • Conclusions
Human genome in a nutshell • Human : 23 chromosomes • Chromosomes thousands of genes • Gene info : exons , comments : introns Splice junction are like /* comment flags */ in C-code • Exons and introns codons • Codon bases
Exon Splice Junction Splice Junction Intron Intron ….GTGAAGGTTAA AGATGTAGATGT ATTG… DNA Splice Junctions • DNA billions of nucleotides ( A, C, G, T) • Genes sequences of amino acids (exons) that are often interrupted by non-coding nucleotides (introns) • <.1% of human DNA is made up of exons • 99% of splice junctions have the same motif, for • Exon to intron it is GT • Intron to exon it is AG
Splice Junction Exon Intron …TGTAAGG AGACGAGTT… DNA Splice Junction (Cont.) • A complete gene is made up of different exons • Splice junction identification aids in the discovery of new genes • The dataset used for this study is made up of 1,424 sequences • Data were created ab initio from GENBANK • Each sequence is 32 nucleotides long with regions comprising -15 to +15 nucleotides from the splice-junction
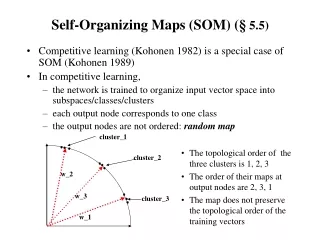
i w i 1 Component 1 w Component 2 i 2 w c c 1 w Component 3 c 2 w i 3 w c 3 Component 4 w c 4 w i 4 Component 5 w 5 c w i 5 Output layer Input layer Self-Organizing Maps (SOM) Network • Unsupervised learning neural network • Projects high-dimensional input data onto two-dimensional output map • Preserves the topology of the input data • Visualizes structures and clusters of the data
B C A Use of SOM for DNA Splice Junction Classification Model Neuron identification methods - Highest frequency class - Closest neuron DNA test set SOM Classification Map U-Matrix Map SOM DNA training set Classification Class A: intron to exon Class B: exon to intron Class C: no transition
B C Confusion matrix of 424-DNA test set A SOM Results for DNA Splice Junction Data The U-matrix of the DNA training set
Conclusions • SOM is effective in DNA splice junction classification • SOM is powerful visualization for high dimensional data
Demo with Analyze Code • 800 training data, 324 test data (160 features) • 96% correct overall classification on test data Confusion Matrix
THE END GATCAATGAGGTGGACACCAGAGGCGGGGACTTGTAAATAACACTGGGCTGTAGGAGTGA TGGGGTTCACCTCTAATTCTAAGATGGCTAGATAATGCATCTTTCAGGGTTGTGCTTCTA TCTAGAAGGTAGAGCTGTGGTCGTTCAATAAAAGTCCTCAAGAGGTTGGTTAATACGCAT GTTTAATAGTACAGTATGGTGACTATAGTCAACAATAATTTATTGTACATTTTTAAATAG CTAGAAGAAAAGCATTGGGAAGTTTCCAACATGAAGAAAAGATAAATGGTCAAGGGAATG GATATCCTAATTACCCTGATTTGATCATTATGCATTATATACATGAATCAAAATATCACA CATACCTTCAAACTATGTACAAATATTATATACCAATAAAAAATCATCATCATCATCTCC ATCATCACCACCCTCCTCCTCATCACCACCAGCATCACCACCATCATCACCACCACCATC ATCACCACCACCACTGCCATCATCATCACCACCACTGTGCCATCATCATCACCACCACTG TCATTATCACCACCACCATCATCACCAACACCACTGCCATCGTCATCACCACCACTGTCA TTATCACCACCACCATCACCAACATCACCACCACCATTATCACCACCATCAACACCACCA CCCCCATCATCATCATCACTACTACCATCATTACCAGCACCACCACCACTATCACCACCA CCACCACAATCACCATCACCACTATCATCAACATCATCACTACCACCATCACCAACACCA CCATCATTATCACCACCACCACCATCACCAACATCACCACCATCATCATCACCACCATCA CCAAGACCATCATCATCACCATCACCACCAACATCACCACCATCACCAACACCACCATCA CCACCACCACCACCATCATCACCACCACCACCATCATCATCACCACCACCGCCATCATCA TCGCCACCACCATGACCACCACCATCACAACCATCACCACCATCACAACCACCATCATCA CTATCGCTATCACCACCATCACCATTACCACCACCATTACTACAACCATGACCATCACCA CCATCACCACCACCATCACAACGATCACCATCACAGCCACCATCATCACCACCACCACCA CCACCATCACCATCAAACCATCGGCATTATTATTTTTTTAGAATTTTGTTGGGATTCAGT ATCTGCCAAGATACCCATTCTTAAAACATGAAAAAGCAGCTGACCCTCCTGTGGCCCCCT TTTTGGGCAGTCATTGCAGGACCTCATCCCCAAGCAGCAGCTCTGGTGGCATACAGGCAA CCCACCACCAAGGTAGAGGGTAATTGAGCAGAAAAGCCACTTCCTCCAGCAGTTCCCTGT GATCAATGAGGTGGACACCAGAGGCGGGGACTTGTAAATAACACTGGGCTGTAGGAGTGA TGGGGTTCACCTCTAATTCTAAGATGGCTAGATAATGCATCTTTCAGGGTTGTGCTTCTA TCTAGAAGGTAGAGCTGTGGTCGTTCAATAAAAGTCCTCAAGAGGTTGGTTAATACGCAT GTTTAATAGTACAGTATGGTGACTATAGTCAACAATAATTTATTGTACATTTTTAAATAG CTAGAAGAAAAGCATTGGGAAGTTTCCAACATGAAGAAAAGATAAATGGTCAAGGGAATG GATATCCTAATTACCCTGATTTGATCATTATGCATTATATACATGAATCAAAATATCACA CATACCTTCAAACTATGTACAAATATTATATACCAATAAAAAATCATCATCATCATCTCC ATCATCACCACCCTCCTCCTCATCACCACCAGCATCACCACCATCATCACCACCACCATC ATCACCACCACCACTGCCATCATCATCACCACCACTGTGCCATCATCATCACCACCACTG TCATTATCACCACCACCATCATCACCAACACCACTGCCATCGTCATCACCACCACTGTCA TTATCACCACCACCATCACCAACATCACCACCACCATTATCACCACCATCAACACCACCA CCCCCATCATCATCATCACTACTACCATCATTACCAGCACCACCACCACTATCACCACCA CCACCACAATCACCATCACCACTATCATCAACATCATCACTACCACCATCACCAACACCA CCATCATTATCACCACCACCACCATCACCAACATCACCACCATCATCATCACCACCATCA CCAAGACCATCATCATCACCATCACCACCAACATCACCACCATCACCAACACCACCATCA CCACCACCACCACCATCATCACCACCACCACCATCATCATCACCACCACCGCCATCATCA TCGCCACCACCATGACCACCACCATCACAACCATCACCACCATCACAACCACCATCATCA CTATCGCTATCACCACCATCACCATTACCACCACCATTACTACAACCATGACCATCACCA CCATCACCACCACCATCACAACGATCACCATCACAGCCACCATCATCACCACCACCACCA CCACCATCACCATCAAACCATCGGCATTATTATTTTTTTAGAATTTTGTTGGGATTCAGT ATCTGCCAAGATACCCATTCTTAAAACATGAAAAAGCAGCTGACCCTCCTGTGGCCCCCT TTTTGGGCAGTCATTGCAGGACCTCATCCCCAAGCAGCAGCTCTGGTGGCATACAGGCAA CCCACCACCAAGGTAGAGGGTAATTGAGCAGAAAAGCCACTTCCTCCAGCAGTTCCCTGT DDASSL Drug Design and Semi-Supervised Learning