Download

1 / 25
280 likes | 597 Views
The Dictionary ADT: Skip List Implementation. CSCI 2720 Eileen Kraemer Spring 2005. Definition of Dictionary. Primary use: to store elements so that they can be located quickly using keys

E N D
The Dictionary ADT:Skip List Implementation CSCI 2720 Eileen Kraemer Spring 2005
Definition of Dictionary • Primary use: to store elements so that they can be located quickly using keys • Motivation: each element in a dictionary typically stores additional useful information beside its search key. (eg: bank accounts) • Can be implemented using lists, binary search trees, Red/black trees, hash table, AVL tree, Skip lists
Dictionary ADT • Size(): Returns the number of items in D • IsEmpty(): Tests whether D is empty • FindElement(k): If D contains an item with a key equal to k, then it return the element of such an item • FindAllElements(k): Returns an enumeration of all the elements in D with key equal k • InsertItem(k, e): Inserts an item with element e and key k into D. • remove(k): Removes from D the items with keys equal to k, and returns an numeration of their elements
Performance considerations: lists • Size(): • O(1) if size is stored explicitly, else O(n) • IsEmpty(): • O(1) • FindElement(k): • O(n) • … and we’ll talk about variations lists that can improve this • InsertItem(k, e): • O(1) (assumes item already found) • Remove(k): • O(1) (assumes item already found)
Pros and cons: list and array implementations • Lists: • Efficient insertions/deletions -- O(1) • Inefficient searching – O(n) • Optimizations exist, but still …. • Arrays: • Efficient lookup/searching • On index O(1) • On key values (using Binary Search) -- O(log n) • Inefficient insertions/deletions -- O(n)
Skip List: characteristics of both lists and arrays • A list on which we can perform binary search • Skip Lists support O(log n) • Insertion • Deletion • Querying • A relatively recent data structure • “A probabilistic alternative to balanced trees”
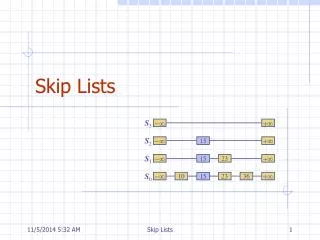
(Perfect) Skip Lists • A skip list is a collection of lists at different levels • The lowest level (0) is a sorted, singly linked list of all nodes • The first level (1) links alternate nodes • The second level (2) links every fourth node • In general, level i links every 2ith node • In total, log2 n levels (i.e. O(log2 n) levels). • Each level has half the nodes of the one below it
- + Example of a (perfect)Skip List S3 S2 - 31 + S1 44 - 23 31 64 + S0 - 12 23 26 31 34 44 56 64 +
Insertions/Deletions When we add a new node, our beautifully precise structure might become invalid. • We may have to change the level of every node • One (sneaky) option is to move all the elements around • Both options take O(n) time, which is back where we began • Is it possible to achieve a net gain?
- + - 12 23 26 31 34 44 56 64 78 + Example of a randomizedSkip List S3 S2 - 31 + S1 - 23 31 34 64 + S0
Definition of Skip List • A skip list for a set S of distinct (key, element) items is a series of lists S0, S1 , … , Sh such that: • Each list Si contains the special keys + and - • List S0 contains the keys of S in nondecreasing order • Each list is a subsequence of the previous one, i.e.,S0 S1 … Sh • List Sh contains only the two special keys
Initialization • A new list is initialized as follows: • 1) A node NIL (+ ) is created and its key is set to a value greater than the greatest key that could possibly used in the list • 2) Another node NIL (-) is created, value set to lowest key that could be used • 3) The level (high) of a new list is 1 • 4) All forward pointers of the header point to NIL
Searching in Skip List • We search for a key x in a skip list as follows: • We start at the first position of the top list • At the current position p, we compare x with y key(after(p)) x = y: we return element(after(p)) x > y: we “scan forward” x < y: we “drop down” • If we try to drop down past the bottom list, we return NO_SUCH_KEY • Example: search for 78
- + Searching in Skip List Example S3 S2 - 31 + S1 - 23 31 34 64 + S0 - 12 23 26 31 34 44 56 64 78 + • P is 64, at S1,+ is bigger than 78, we drop down • At S0, 78 = 78, we reach our solution
Insertion • The insertion algorithm for skip lists uses randomization to decide how many references to the new item (k,e) should be added to the skip list • We then insert (k,e) in this bottom-level list immediately after position p. After inserting the new item at this level we “flip a coin”. • If the flip comes up tails, then we stop right there. If the flip comes up heads, we move to next higher level and insert (k,e) in this level at the appropriate position.
A randomized algorithm performs coin tosses (i.e., uses random bits) to control its execution It contains statements of the type b random() if b= 0 do A … else { b= 1} do B … Its running time depends on the outcomes of the coin tosses Randomized Algorithms • We analyze the expected running time of a randomized algorithm under the following assumptions • the coins are unbiased, and • the coin tosses are independent • The worst-case running time of a randomized algorithm is large but has very low probability (e.g., it occurs when all the coin tosses give “heads”)
- + - 15 + - 15 23 + - 10 23 36 + 15 Insertion in Skip List Example • Suppose we want to insert 15 • Do a search, and find the spot between 10 and 23 • Suppose the coin come up “head” three times S3 p2 S2 S2 - + p1 S1 S1 - + 23 p0 S0 S0 - 10 23 36 +
Deletion • We begin by performing a search for the given key k. If a position p with key k is not found, then we return the NO SUCH KEY element. • Otherwise, if a position p with key k is found (it would be found on the bottom level), then we remove all the position above p • If more than one upper level is empty, remove it.
Deletion in Skip List Example • 1) Suppose we want to delete 34 • 2) Do a search, find the spot between 23 and 45 • 3) Remove all the position above p S3 - + p2 S2 S2 - + - 34 + p1 S1 S1 - + - 23 34 + 23 p0 S0 S0 - 12 23 45 + - 12 23 45 + 34
Randomized Skip Lists • We sacrifice “perfection” in order to improve our performance of Insert/Remove. • So our array of lists is no longer going to be that of exact traversals of successive mid-points but it’s going to be approximately so. • We choose the height of a new node randomly. We want the proportion of number of level-0 nodes, level-1 nodes, etc. to be similar to the Perfect list.
Randomized Skip Lists • In Randomized Skip Lists, when we Insert a new node we no longer shift values but instead we insert the node and simply generate a “random” level for it. • This works well when we have a large number of nodes which gives a fairly uniform mix of node levels. • Not perfect but we can still skip over large groups of nodes
Generating Random Heights • Consider this pseudo-code snippet (assume n is the no. of nodes) NodeLevel = 0; x = rand( ); while( x < 0.5 && NodeLevel < log2 n ) { NodeLevel++; x = rand( ); } • This generates a good mix if rand( ) works correctly
Analysis (Randomized) • Expected height of a node: E[h] = 0.5 * 0 + 0.5 * (1 + E[h]) • Very high probability that maximum height is O(log n) • Probability h > 2 log n = 1/n • Probability h > c log n = 1/nc-1 • Expected number of nodes on level i is n/2i • Expected time for Find( ), Insert( ), Remove( ) is O(log n)
Analysis of Find( ) • Consider traversing the list backwards • Assume the list has up and left pointers • Algorithm p = CurrentNode level 0 pointer while (p != Head) if up(p) exists p = up(p) else p = left(p)
Analysis of Find( ) • Probability that up(p) exists is 0.5 • Therefore, we expect to take each branch of the loop an equal number of times • So the total number of moves is 2 * the number of upward moves • But the height is only O(log n) • So, the total number of moves is O(log n)