Download

1 / 16
160 likes | 360 Views
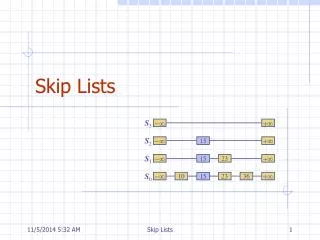
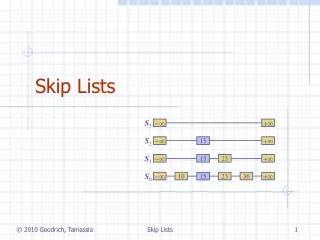
Skip Lists. 12. 23. 26. 31. 34. 44. 56. 64. 78. Skip List. Question: Can we create a structure that adds the best properties of Array and Linked list Data Structure? Query: O(log n) in sorted Arrays Insert/Removal: O(1) in Linked List.

E N D
12 23 26 31 34 44 56 64 78 Skip List • Question: • Can we create a structure that adds the best properties of Array and Linked list Data Structure? • Query: O(log n) in sorted Arrays • Insert/Removal: O(1) in Linked List
A skip list for a set S of distinct (key, element) items is a series of lists S0, S1 , … , Sh such that Each list Si contains the special keys + and - List S0 contains the keys of S in nondecreasing order Each list is a subsequence of the previous one, i.e.,S0 S1 … Sh List Sh contains only the two special keys We show how to use a skip list to implement the dictionary ADT - + - 12 23 26 31 34 44 56 64 78 + What is a Skip List S3 S2 - 31 + S1 - 23 31 34 64 + S0
We search for a key x in a skip list as follows: We start at the first position of the top list At the current position p, we compare x with y key(after(p)) x = y: we return element(after(p)) x > y: we “scan forward” x < y: we “drop down” If we try to drop down past the bottom list, we return NO_SUCH_KEY Example: search for 78 - + Search S3 S2 - 31 + S1 - 23 31 34 64 + S0 - 12 23 26 31 34 44 56 64 78 +
- + - 15 + - 15 23 + - 10 23 36 + 15 Insertion • To insert an item (x, o) into a skip list, we use a randomized algorithm: • We repeatedly toss a coin until we get tails, and we denote with i the number of times the coin came up heads • If i h, we add to the skip list new lists Sh+1, … , Si +1, each containing only the two special keys • We search for x in the skip list and find the positions p0, p1 , …, pi of the items with largest key less than x in each list S0, S1, … , Si • For j 0, …, i, we insert item (x, o) into list Sj after position pj • Example: insert key 15, with i= 2 S3 p2 S2 S2 - + p1 S1 S1 - + 23 p0 S0 S0 - 10 23 36 +
Deletion • To remove an item with key x from a skip list, we proceed as follows: • We search for x in the skip list and find the positions p0, p1 , …, pi of the items with key x, where position pj is in list Sj • We remove positions p0, p1 , …, pi from the lists S0, S1, … , Si • We remove all but one list containing only the two special keys • Example: remove key 34 S3 - + p2 S2 S2 - + - 34 + p1 S1 S1 - + - 23 34 + 23 p0 S0 S0 - 12 23 45 + - 12 23 45 + 34
We can implement a skip list with quad-nodes A quad-node stores: item link to the node before link to the node after link to the node below link to the node after Also, we define special keys PLUS_INF and MINUS_INF, and we modify the key comparator to handle them Implementation quad-node x
The space used by a skip list depends on the random bits used by each invocation of the insertion algorithm We use the following two basic probabilistic facts: Fact 1: The probability of getting i consecutive heads when flipping a coin is 1/2i Fact 2: If each of n items is present in a set with probability p, the expected size of the set is np Consider a skip list with n items By Fact 1, we insert an item in list Si with probability 1/2i By Fact 2, the expected size of list Si is n/2i The expected number of nodes used by the skip list is Space Usage • Thus, the expected space usage of a skip list with n items is O(n)
The running time of the search an insertion algorithms is affected by the height h of the skip list We show that with high probability, a skip list with n items has height O(log n) We use the following additional probabilistic fact: Fact 3: If each of n events has probability p, the probability that at least one event occurs is at most np Consider a skip list with n items By Fact 1, we insert an item in list Si with probability 1/2i By Fact 3, the probability that list Si has at least one item is at most n/2i By picking i= 3log n, we have the probability that S3log n has at least one item is at mostn/23log n= n/n3= 1/n2 Thus a skip list with n items has height at most 3log n with probability at least 1 - 1/n2 Height
The search time in a skip list is proportional to the number of drop-down steps, plus the number of scan-forward steps The drop-down steps are bounded by the height of the skip list and thus are O(log n) with high probability To analyze the scan-forward steps, we use yet another probabilistic fact: Fact 4: The expected number of coin tosses required in order to get tails is 2 When we scan forward in a list, the destination key does not belong to a higher list A scan-forward step is associated with a former coin toss that gave tails By Fact 4, in each list the expected number of scan-forward steps is 2 Thus, the expected number of scan-forward steps is O(log n) We conclude that a search in a skip list takes O(log n) expected time The analysis of insertion and deletion gives similar results Search and Update Times
A skip list is a data structure for dictionaries that uses a randomized insertion algorithm In a skip list with n items The expected space used is O(n) The expected search, insertion and deletion time is O(log n) Using a more complex probabilistic analysis, one can show that these performance bounds also hold with high probability Skip lists are fast and simple to implement in practice Summary
Many sorting algorithms are comparison based. They sort by making comparisons between pairs of objects Examples: bubble-sort, selection-sort, insertion-sort, heap-sort, merge-sort, quick-sort, ... Let us therefore derive a lower bound on the running time of any algorithm that uses comparisons to sort n elements, x1, x2, …, xn. Comparison-Based Sorting (§ 4.4) Is xi < xj? no yes
Let us just count comparisons then. Each possible run of the algorithm corresponds to a root-to-leaf path in a decision tree Example:xa, xb, xc Counting Comparisons xa <xb xb <xc xc <xb [xa, xb , xc] xa <xc [xc ,xb ,xa] xa <xc [xa ,xc ,xb] [xc ,xa ,xb] [xb ,xa ,xc] [xb ,xc ,xa]
Decision Tree Height • The height of this decision tree is a lower bound on the running time • Every possible input permutation must lead to a separate leaf output. • If not, some input …4…5… would have same output ordering as …5…4…, which would be wrong. • Since there are n!=1*2*…*n leaves, the height is at least log (n!)
The Lower Bound • Any comparison-based sorting algorithms takes at least log (n!) time • Therefore, any such algorithm takes time at least • That is, any comparison-based sorting algorithm must run in Ω(n log n) time.