Download

1 / 32
330 likes | 565 Views
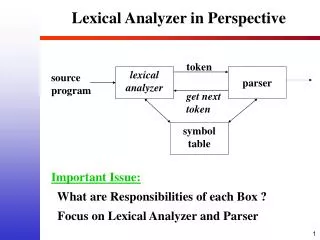
Lexical Analyzer (Checker). Lexical Analyzer. Lexical Analyzer reads the source program character by character to produce tokens. Normally a lexical analyzer doesn’t return a list of tokens at one shot, it returns a token when the parser asks a token from it. Tokens, Lexemes, and Patterns.

E N D
Lexical Analyzer • Lexical Analyzer reads the source program character by character to produce tokens. • Normally a lexical analyzer doesn’t return a list of tokens at one shot, it returns a token when the parser asks a token from it.
Tokens, Lexemes, and Patterns • Tokens include keywords, operators, identifiers, constants, literal strings, punctuation symbols • e.g: identifier, number, addop, assgop • A lexeme is a sequence of characters in the source program representing a token • e.g: newval, oldval • A pattern is a rule describing a set of lexemes that can represent a particular token • e.g: Identifier represents a set of strings which start with a letter continues with letters and digits
Attributes • Since a token can represent more than one lexeme, attributes provide additional information about tokens • For simplicity, a token may have a single attribute. • For an identifier, attribute is a pointer to the symbol table • Examples of some attributes: • <id,attr> where attr is pointer to the symbol table • <assgop,_> no attribute is needed (only one assignment operator) • <num,val> where val is the actual value of the number. • Token and its attribute uniquely identifies a lexeme.
Strings and Languages • Alphabet – any finite set of symbols (e.g. ASCII, binary alphabet, or a set of tokens) • String – A finite sequence of symbols drawn from an alphabet • Language – A set of strings over a fixed alphabet
Operations on Languages • Union: • Concatenation: • Kleene closure: • Zero or more concatenations • Positive closure: • One or more concatenations
Regular Expressions • Can give “names” to regular expressions • Convention: names in boldface (to distinguish them from symbols) letter A|B|…|Z|a|b|…|z digit 0|1|…|9 idletter (letter | digit)*
Notational Shorthands • One or more instances: r+ denotes rr* • Zero or one Instance: r? denotes r|ε • Character classes: [a-z] denotes [a|b|…|z] digit [0-9] digits digit+ optional_fraction (. digits )? numdigitsoptional_fraction
Limitations • Can not describe balanced or nested constructs • Example, all valid strings of balanced parentheses • This can be done with Context Free Grammar ( CFG)
Grammar Fragment (Pascal) stmt ifexprthenstmt | ifexprthenstmtelsestmt | ε expr termrelopterm | term term id | num
Related Regular Expression Definitions if if then then else else relop < | <= | = | <> | > | >= idletter ( letter | digit )* numdigit+ (. digit+ )? ws delim+ delim blank | tab | newline
Transition Diagrams • A stylized flowchart • Transition diagrams consist of states connected by edges • Edges leaving a state s are labeled with input characters that may occur after reaching state s • Assumed to be deterministic • There is one start state and at least one accepting (final) state
Identifiers and Keywords • Share a transition diagram • After reaching accepting state, code determines if lexeme is keyword or identifier
Finding the Next Token token nexttoken(void) { while (1) { switch (state) { case 0: c = nextchar(); if (c == ' ' || c=='\t' || c == '\n') { state = 0; lexeme_beginning++; } else if (c == '<') state = 1; else if (c == '=') state = 5 else if (c == '>') state = 6 else state = next_td(); break; … /* other cases here */
Trying Transition Diagrams int next_td(void) { switch (start) { case 0: start = 9; break; case 9: start = 20; break; case 20: start = 25; break; case 25: recover(); break; default: error("invalid start state"); } /* Possibly additional actions here */ return start; }
Finite Automata • Generalized transition diagrams that act as “recognizer” for a language • Can be nondeterministic (NFA) or deterministic (DFA) • NFAs can have ε-transitions, DFAs can not • NFAs can have multiple edges with same symbol leaving a state, DFAs can not • Both can recognize exactly what regular expressions can denote
NFAs • A set of states S • A set of input symbols Σ (input alphabet) • A transition function move that maps state, symbol pairs to a set of states • A single start state s0 • A set of accepting (or final) states F • An NFA accepts a string s if and only if there exists a path from the start state to an accepting state such that the edge labels spell out s
NFA (Example) • 0 is the start state s0 • {2} is the set of final states F • = {a,b} S = {0,1,2} a start a b 0 1 2 b Transition graph of the NFA The language recognized by this NFA is (a|b) * ab
DFAs • No state has an ε-transition • For each state s and input symbol a, there as at most one edge labeled a leaving s
Functions ε-closure and move • ε-closure(s) is the set of NFA states reachable from NFA state s on ε-transitions alone • move(T,a) is the set of NFA states to which there is a transition on input a from any NFA state s in T
Simulating a DFA s := s0 c := nextchar while c != eof do s := move(s, c) c := nextchar end if s is in F then return “yes” else return “no”
Simulating an NFA S := ε-closure({s0}) a := nextchar while a != eof do S := ε-closure(move(S,a)) a := nextchar if S ∩ F != Ø return “yes” else return “no”
Simulating a Regular Expression • First use Thompson’s Construction to convert RE to NFA • Then there are two choices: • Use subset construction to convert NFA to DFA, then simulate the DFA • Simulate the NFA directly
Some Other Issues in Lexical Analyzer • The lexical analyzer has to recognize the longest possible string. • Ex: identifier newval -- n ne new newvnewvanewval • What is the end of a token? Is there any character which marks the end of a token?
Some Other Issues in Lexical Analyzer (cont.) • Skipping comments • Normally we don’t return a comment as a token. • So, the comments are only processed by the lexical analyzer, and don’t complicate the syntax of the language. • Symbol table interface • symbol table holds information about tokens (at least lexeme of identifiers) • how to implement the symbol table, and what kind of operations. • hash table – open addressing, chaining • putting into the hash table, finding the position of a token from its lexeme. • Positions of the tokens in the file (for the error handling).