Download

1 / 71
710 likes | 878 Views
Chapter 3 Lexical analyzer. Zhang Jing, Yu SiLiang College of Computer Science & Technology Harbin Engineering University.

E N D
Chapter 3 Lexical analyzer Zhang Jing, Yu SiLiang College of Computer Science & Technology Harbin Engineering University
This chapter deals with the techniques of lexical analyzer. That is, how to build a lexical analyzer? How to construct a symbol table which includes the tokens coming from the source language? Then, how to produce lexical analyzer efficiently ? ? zhangjing@hrbeu.edu.cn
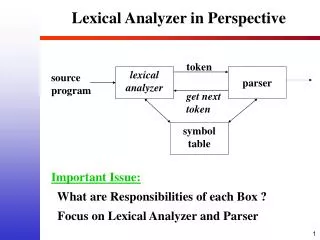
Role of lexical analyzer • The role of lexical analyzer is that it can recognize words—tokens from source program. The input of lexical analyzer is source program, the output of it are tokens. If we want to do lexical analyzer, we should firstly identify tokens and remove white space, enter, note and other information that are not related with parse and code generation. Second, we should divide the tokens into different types, namely, to judge if they are type of identifiers, constants, literal strings, operators, keywords and punctuation symbols (parentheses, commas and semicolons). Third, translate all the different type tokens into special expressions. Finally, put them into symbol table. zhangjing@hrbeu.edu.cn
Phase of lexical analyzer in compiler is shown in Fig. 3.1. zhangjing@hrbeu.edu.cn
1. Types and expression of token Actually, tokens in a program can be divided into 5 types; they are identifiers, constants, operators, keywords and punctuation symbols (parentheses, commas and semicolons) . . Type 1: Keywords. They are the word of command definition, such as “IF”, “FOR” . Type 2: Identifiers. They are the name of variable, procedure, function and so on, such as : “index”, “count”. Type 3: Constants. such as “65”, “-0.993”,“123.4” Type 4: Operators. For example, “+”, “*” and “>” are all operators. Type 5: Punctuation symbol. They are the symbols, such as “,” , “:” , “ ;”. zhangjing@hrbeu.edu.cn
Example 3.1 • This is one instruction in a program. Index := 2 * count +17; • After the process of lexical analyzer, the tokens of it are shown by Table 3.1. zhangjing@hrbeu.edu.cn
Role of buffer in lexical analyzing • Lexical analyzer needs buffer all the times when source program is compiled, because lexical analyzer should look ahead for several characters to judge if they are in same token. In addition, a great deal of time is spent in locating the characters. Buffering techniques can reduce the amount of time when scanning input characters, here we only outline one of them. . • The buffer we use is divided into two halves so that each half includes N-characters. When scanning, we should judge pointer “forward” if it reaches the end of the first half buffer, if yes, we should load the other half . . zhangjing@hrbeu.edu.cn
Example 3.2 There is a sentence in source program: Index := 2 * count +17; The buffer that stores the sentence is separated into two halves. The first half includes 4 characters, the second half also has 4 characters. . It is described below. zhangjing@hrbeu.edu.cn
The algorithm for storing sentence in buffer is shown as follows, zhangjing@hrbeu.edu.cn
Design of lexical analyzer • Before designing lexical analyzer, we should draw transition diagram first. We shall give several examples to explain how to draw the state diagram and how to obtain the lexical analysis. . zhangjing@hrbeu.edu.cn
1.Grammar of U::=aW|a • The state diagram of grammar U::=aW is written • Similarly, the state diagram of grammar U::= a is zhangjing@hrbeu.edu.cn
Example 3.3 Grammar G[S]: S::=aA | bB A::=aS | bC B::=bS | aC C::=bA | aB| The state diagram of example 3.3 is shown by Fig.3.2. zhangjing@hrbeu.edu.cn
Example 3.4 Grammar G[S]: S::=+N | -N S::=dN | d N::=dN | d The state diagram of example 3.4 is shown by Fig.3.3. Note: ◎ in Figure 3.3 and 3.4 represents the output— leaving state. zhangjing@hrbeu.edu.cn
2. Grammar of U::=a|Wa There is regular grammar: U::=Wa The state diagram of it is: The state diagram of grammar U::= a is: • For this grammar, we add a start state S (S VN)to the state diagram. zhangjing@hrbeu.edu.cn
Example 3.5 Grammar G[Z]: Z::=Za|Aa|Bb A::=Ba|a B::=Ab|b What we want to do is that to construct a state diagram from this grammar and judge if string “ababaaa” belongs to the language. Fig.3.4 are the procedure of generating the state diagram of example 3.5 from begin to end. . zhangjing@hrbeu.edu.cn
From the start state of S, we input the charaters “ababaaa” one by one, at last reach the end state Z. So string “ababaaa” is the sentence of the grammar . zhangjing@hrbeu.edu.cn
Finite Automata • The aim we study the language and grammar is to create a lexical analyzer. Actually, we first know a language, grammar, and then we can construct transition diagram from it. This section we go on forming automata from the transition diagram, and then design a program to realize the automata, namely, lexical analyzer. . zhangjing@hrbeu.edu.cn
Deterministic Finite Automata—DFA • The finite automata is a mathematical model of state transition, it can be described by five elements. (K , VT , M , S , Z) • While K is a set of states; VT is a set of input symbols; S is start state, S∈K;Z is leaving state which belongs to nonempty set, Z K; M is a transition function that is state-symbol pairs K×VT, M (W , a)=U. While W is the present state, when W accepts an input symbol “a”, W will move to next state U . . • If it has a unique and definite next state when it moves form one state to others, the FA is called definite finite automata—DFA. zhangjing@hrbeu.edu.cn
Example 3.5 can be described by DFA and it is shown below. ({S,Z,A,B},{a,b},M,S,{Z}) M : M(S,a)=A M(S,b)=B M(A,a)=Z M(A,b)=B M(B,a)=A M(B,b)=Z M(Z,a)=Z Now we can deduce to judge if string “ababaaa” can be recognized by the DFA. M(S, ababaa)=M(M(S, a), babaa)= M(A, babaa)=M(M(A,b), abaa)=M(B, abaa)=M(A, baa)=M(B, aa)=M(A, a)= Z zhangjing@hrbeu.edu.cn
Example 3.6 FA=({0, 1, 2, 3},{a, b}, M, 0,{3}) While, M: M (0, a) = 1 M (0, b) = 2 M (1, a) = 3 M (2, b) = 3 M (3, a) = 3 M (3, b) = 3 State set is K={0, 1, 2, 3},input symbol is VT={a, b},start state is 0;leaving state set is{3}. When we want to judge if the string “aab” would be accepted by the FA, the transition function M is M (0, a) = 1 M (1, a) = 3 M (3, b) = 3 zhangjing@hrbeu.edu.cn
So string “aab” can be accepted by the FA. Similarly, you can try if string “abab” would be recognized by the FA. . zhangjing@hrbeu.edu.cn
Example 3.7 FA=({A, B, C},{a , b}, M, A,{C}) While, M: M (A, a) = B M (A, b) = A M (B, a) = B M (B, b) = C M (C, a) = B M (C, b) = A “abab” can be accepted by FA, because the deduction from start state is. . M (A, a)=B M (B, b)=C M (C, a)=B M (B, b)=C zhangjing@hrbeu.edu.cn
The deduction can also be written as M (A, abab) = M (M (A, a) , bab) = M (B, bab) = M (M (B, b), ab) = M (C, ab) = M (M (C, a) , b) = M (B, b) = C zhangjing@hrbeu.edu.cn
Example 3.8 There is FA=({W, S, P},{t, x, ε}, M, W,{P}) M: M (W,ε) = W M (W,t) = S M (S,x) = P The question is to judge if “tx” is recognized by the FA. The deduction is as follows, M (W,ε) = W M (W, tx) = M( M (W , t) , x) M (S, x) = P Because P∈Z, we can say “tx” is recognized by the FA. zhangjing@hrbeu.edu.cn
The algorithm of DFA There is an input string “x”, the start symbol is S0, S is state set, G is set of leaving state. zhangjing@hrbeu.edu.cn
FA Program There is an FA=({0,1,2,3}, {a,b}, M, 0, {3}) M: M(0,a)=1 M(0,b)=2 M(1,a)=3 M(1,b)=2 M(2,a)=1 M(2,b)=3 M(3,a)=3 M(3,b)=3 The question is to judge if the string “abbb” would be identified or accepted by the FA? The FA program is as follows. zhangjing@hrbeu.edu.cn
Result of the FA program is shown by Fig.3.7. zhangjing@hrbeu.edu.cn
Nondeterministic Finite Automata (NFA) There is a grammar G: U::=Wa and V::=Wa The transition diagram of G is zhangjing@hrbeu.edu.cn
The FA of G: M (W, a) = U and M (W, a) = V Or M (W, a) = {U, V} So the state-symbol pair is not unique, the FA is named as Nondeterministic Finite Automata(NFA). . zhangjing@hrbeu.edu.cn
The definition of NFA is (K, VT, M, S, Z) While K is state set; VT is a set of input symbols; S is start state, S∈K;Z is leaving state which belongs to nonempty set, Z K; M is state-symbol pairs K× VT* M (W, ε) = {W} M (W, tx) = M{P1, x}∪M{P2, x}∪…M{Pn, x} While, P∈M(W, t);t∈VT;x∈VT. zhangjing@hrbeu.edu.cn
Example 3.9 Regular grammar G[Z]: P: Z::=U1|V0|Z0|Z1 U::=Q1|1 V::=Q0|0 Z::=Q1 Q::=0 The transition state diagram of example 3.9 is shown by Figure 3.8, Z is leaving state, S is start state. . zhangjing@hrbeu.edu.cn
From the transition state of example 3.9, we know that state-symbol pairs of M is not unique, so the G[Z]can be described by NFA. . NFA=({S, Q, U, V, Z},{0, 1}, M,{S},{Z}) While M: M (S, 0) ={V, Q} M (S, 1) ={U} M (U, 0) =Φ M (U, 1) ={Z} M (V, 0) ={Z} M (V, 1) =Φ M (Q, 0) ={V} M (Q, 1) ={U,Z} M (Z, 0) ={Z} M (Z, 1) ={Z} zhangjing@hrbeu.edu.cn
The state Φ is empty state that doesn’t include any state. The deduction of string “0111” begins from the start state S, the state-symbol pair M is M (S, 0111) = M (V, 111)∪M (Q, 111) =Φ∪M (U, 11) ∪ M (Z, 11) = M (Z, 1) ∪ M (Z, 1) = M (Z, 1) ={Z} So M (S, 0111) ={Z}, state Z is leaving state, namely, string “0111” can be accepted by the NFA. You can try string “101” by yourselves to judge if it will be accepted by the NFA. zhangjing@hrbeu.edu.cn
Constructing DFA from NFA Any NFA: N=(K, VT, M, S, F) can has an correspond DFA: N’=(K’, VT, M’, S’, F’). While K’ is the set coming from the subset of K. . [Q1,Q2,…,Qm] is the elements of K’, Qi∈K; M’([R1,R2,…,Ri],T)= [Q1,Q2,….Qj], [R1,R2,…,Ri] is the elements of K,T∈VT ;S’=[S1, S2, …, Sn]; F’={[Sj, Sk, …, Sl]|[Sj, Sk, …, Sl]∈K’, [Sj, Sk, …, Sl]∩F≠φ }; L(N)=L(N’). , zhangjing@hrbeu.edu.cn
Example 3.10 Grammar[Z]: Z:: =Za|Aa|Bb A::=Ba|Za|a B::=Ab|Ba|b The state set K={S, A, B, Z}; NFA of the grammar is shown by Figure 3.9. zhangjing@hrbeu.edu.cn
The NFA of grammar Z is N=({S,A,B,Z},{a,b},M,{S},{Z}) M: M(S,a)={A} M(S,b)={B} M(A,a)={Z} M(A,b)={B} M(B,a)={A,B} M(B,b)={Z} M(Z,a)={A,Z} zhangjing@hrbeu.edu.cn
Now what we want to do is that to construct DFA from NFA, We first begin from start state of S. K’={[S]} M([S],a)=[A] M([S],b)=[B] K’={[S],[A],[B]} M([A],a)=[Z] M([A],b)=[B] M([B],a)=[AB] M([B],b)=[Z] zhangjing@hrbeu.edu.cn
K’={S],[A],[B],[Z],[AB]} M([Z],a)=[AZ] M([Z],b)=φ M([AB],a)=[ABZ] M([AB],b)=[BZ] K’={S],[A],[B],[Z],[AB],[AZ],[BZ], [ABZ]} M([AZ],a)=[AZ] M([AZ],b)=[B] M([BZ],a)=[ABZ] M([BZ],b)=[Z] M([ABZ],a)=[ABZ] M([ABZ],b)=[BZ] According to the states transition above, we can obtain the state set of DFA, and they are shown by the left in the Table3.2, that is: : K’={[S],[A],[B],[Z],[AB],[AZ],[BZ],[ABZ]} zhangjing@hrbeu.edu.cn
The start state still is S, the leaving states are the states that include the leaving state Z in K, namely, [Z],[AZ],[BZ],[ABZ]. The DFA is shown by Fig.3.10. . zhangjing@hrbeu.edu.cn
Minimum DFA This section we want to make the DFA briefly, namely, to minimize DFA. First we introduce some concepts: : (1) Equivalence states: the next states of the states belong to same state set when input characters. . (2) Terminal states: states that include leaving state. . (3) Nonterminal states: states that do not include any leaving state. . (4) Dead state: the nonterminal states that can not reach any terminal states. . (5) Unreachable state: states that can not be reached from start state. . zhangjing@hrbeu.edu.cn
The algorithm of minimum DFA: (1)Divide the states into two state sets, namely, terminal state and nonterminal state. (2)Judge if states are equivalence states, if yes, we should merge equivalence states. (3)Remove dead states and unreachable states. zhangjing@hrbeu.edu.cn
:(1)States are divided into two state sets: nonterminal state set that include state 0,1,2,3, and terminal states are equivalence states and are merged into state 4,shown in Fig.3.11. • Fig.3.11 The DFA that is divided into two state sets • 图3.11被分为非终结符状态集和终结符状态集的确定有穷自动机 . zhangjing@hrbeu.edu.cn
(2) Judge if nonterminal states are equivalence states. For nonterminal states 0,1,2,3, we input character a and b. . M(0,a)={1} M(1,a)={1} M(2,a)={1} M(3,a)={1} M(0,b)={2} M(1,b)={3} M(2,b)={2} M(3,b)={4} zhangjing@hrbeu.edu.cn
From above, we know that the next state of state 3 is not in nonterminal states set when input character “b”, so the nonterminal states set is divided into state set 3 and state set 0,1,2. Again for state set 0,1,2, state 1 is not in the state set when input character “b”, so state set 0,1,2 is divided into set 1 and set 0,2. Till now, we know that state 0 and state 2 are equivalence states, and they should be merged,shown by Fig.3.12. .. zhangjing@hrbeu.edu.cn