Download

1 / 74
740 likes | 888 Views
Speech and Music Retrieval. LBSC 796/CMSC828o Session 12, April 19, 2004 Douglas W. Oard. Agenda. Questions Speech retrieval Music retrieval. Spoken Word Collections. Broadcast programming News, interview, talk radio, sports, entertainment Scripted stories

E N D
Speech and Music Retrieval LBSC 796/CMSC828o Session 12, April 19, 2004 Douglas W. Oard
Agenda • Questions • Speech retrieval • Music retrieval
Spoken Word Collections • Broadcast programming • News, interview, talk radio, sports, entertainment • Scripted stories • Books on tape, poetry reading, theater • Spontaneous storytelling • Oral history, folklore • Incidental recording • Speeches, oral arguments, meetings, phone calls
Some Statistics • 2,000 U.S. radio stations webcasting • 250,000 hours of oral history in British Library • 35 million audio streams indexed by SingingFish • Over 1 million searches per day • ~100 billion hours of phone calls each year
Audio Retrieval • Retrospective retrieval applications • Search music and nonprint media collections • Electronic finding aids for sound archives • Index audio files on the web • Information filtering applications • Alerting service for a news bureau • Answering machine detection for telemarketing • Autotuner for a car radio
The Size of the Problem • 30,000 hours in the Maryland Libraries • Unique collections with limited physical access • Over 100,000 hours in the National Archives • With new material arriving at an increasing rate • Millions of hours broadcast each year • Over 2,500 radio stations are now Webcasting!
Speech Retrieval Approaches • Controlled vocabulary indexing • Ranked retrieval based on associated text • Automatic feature-based indexing • Social filtering based on other users’ ratings
Search System Query Formulation Query Search Ranked List Selection Query Reformulation and Relevance Feedback Recording Examination Recording Source Reselection Delivery Supporting Information Access Source Selection
Description Strategies • Transcription • Manual transcription (with optional post-editing) • Annotation • Manually assign descriptors to points in a recording • Recommender systems (ratings, link analysis, …) • Associated materials • Interviewer’s notes, speech scripts, producer’s logs • Automatic • Create access points with automatic speech processing
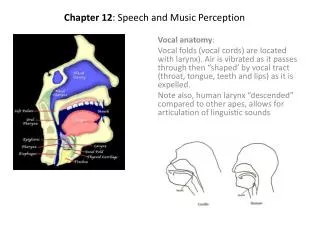
Detectable Speech Features • Content • Phonemes, one-best word recognition, n-best • Identity • Speaker identification, speaker segmentation • Language • Language, dialect, accent • Other measurable parameters • Time, duration, channel, environment
How Speech Recognition Works • Three stages • What sounds were made? • Convert from waveform to subword units (phonemes) • How could the sounds be grouped into words? • Identify the most probable word segmentation points • Which of the possible words were spoken? • Based on likelihood of possible multiword sequences • All three stages are learned from training data • Using hill climbing (a “Hidden Markov Model”)
Using Speech Recognition Phone n-grams Phone Detection Phone lattice Word Construction Transcription dictionary Word lattice One-best transcript Word Selection Language model Words
ETHZ Broadcast News Retrieval • Segment broadcasts into 20 second chunks • Index phoneme n-grams • Overlapping one-best phoneme sequences • Trained using native German speakers • Form phoneme trigrams from typed queries • Rule-based system for “open” vocabulary • Vector space trigram matching • Identify ranked segments by time
Phoneme Trigrams • Manage -> m ae n ih jh • Dictionaries provide accurate transcriptions • But valid only for a single accent and dialect • Rule-base transcription handles unknown words • Index every overlapping 3-phoneme sequence • m ae n • ae n ih • n ih jh
Cambridge Video Mail Retrieval • Added personal audio (and video) to email • But subject lines still typed on a keyboard • Indexed most probable phoneme sequences
Key Results from TREC/TDT • Recognition and retrieval can be decomposed • Word recognition/retrieval works well in English • Retrieval is robust with recognition errors • Up to 40% word error rate is tolerable • Retrieval is robust with segmentation errors • Vocabulary shift/pauses provide strong cues
Cambridge Video Mail Retrieval • Translate queries to phonemes with dictionary • Skip stopwords and words with 3 phonemes • Find no-overlap matches in the lattice • Queries take about 4 seconds per hour of material • Vector space exact word match • No morphological variations checked • Normalize using most probable phoneme sequence • Select from a ranked list of subject lines
IBM Broadcast News Retrieval • Large vocabulary continuous speech recognition • 64,000 word forms covers most utterances • When suitable training data is available • About 40% word error rate in the TREC 6 evaluation • Slow indexing (1 hour per hour) limits collection size • Standard word-based vector space matching • Nearly instant queries • N-gram triage plus lattice match for unknown words • Ranked list showing source and broadcast time
Comparison with Text Retrieval • Detection is harder • Speech recognition errors • Selection is harder • Date and time are not very informative • Examination is harder • Linear medium is hard to browse • Arbitrary segments produce unnatural breaks
Speaker Identification • Gender • Classify speakers as male or female • Identity • Detect speech samples from same speaker • To assign a name, need a known training sample • Speaker segmentation • Identify speaker changes • Count number of speakers
A Richer View of Speech • Speaker identification • Known speaker and “more like this” searches • Gender detection for search and browsing • Topic segmentation via vocabulary shift • More natural breakpoints for browsing • Speaker segmentation • Visualize turn-taking behavior for browsing • Classify turn-taking patterns for searching
Other Possibly Useful Features • Channel characteristics • Cell phone, landline, studio mike, ... • Accent • Another way of grouping speakers • Prosody • Detecting emphasis could help search or browsing • Non-speech audio • Background sounds, audio cues
Competing Demands on the Interface • Query must result in a manageable set • But users prefer simple query interfaces • Selection interface must show several segments • Representations must be compact, but informative • Rapid examination should be possible • But complete access to the recordings is desirable
Iterative Prototyping Strategy • Select a user group and a collection • Observe information seeking behaviors • To identify effective search strategies • Refine the interface • To support effective search strategies • Integrate needed speech technologies • Evaluate the improvements with user studies • And observe changes to effective search strategies
Broadcast News Retrieval Study • NPR Online • Manually prepared transcripts • Human cataloging • SpeechBot • Automatic Speech Recognition • Automatic indexing
Study Design • Seminar on visual and sound materials • Recruited 5 students • After training, we provided 2 topics • 3 searched NPR Online, 2 searched SpeechBot • All then tried both systems with a 3rd topic • Each choosing their own topic • Rich data collection • Observation, think aloud, semi-structured interview • Model-guided inductive analysis • Coded to the model with QSR NVivo
Shoah Foundation’s Collection • Enormous scale • 116,000 hours; 52,000 interviews; 180 TB • Grand challenges • 32 languages, accents, elderly, emotional, … • Accessible • $100 million collection and digitization investment • Annotated • 10,000 hours (~200,000 segments) fully described • Users • A department working full time on dissemination
English ASR Accuracy Training: 200 hours from 800 speakers
ASR Game Plan HoursWord LanguageTranscribedError Rate English 200 39.6% Czech 84 39.4% Russian 20 (of 100) 66.6% Polish Slovak As of May 2003
History Linguistics Journalism Material culture Education Psychology Political science Law enforcement Book Documentary film Research paper CDROM Study guide Obituary Evidence Personal use Who Uses the Collection? Discipline Products Based on analysis of 280 access requests
Question Types • Content • Person, organization • Place, type of place (e.g., camp, ghetto) • Time, time period • Event, subject • Mode of expression • Language • Displayed artifacts (photographs, objects, …) • Affective reaction (e.g., vivid, moving, …) • Age appropriateness
8 independent searchers Holocaust studies (2) German Studies History/Political Science Ethnography Sociology Documentary producer High school teacher 8 teamed searchers All high school teachers Thesaurus-based search Rich data collection Intermediary interaction Semi-structured interviews Observational notes Think-aloud Screen capture Qualitative analysis Theory-guided coding Abductive reasoning Observational Studies
“Old Indexing” Location-Time Subject Person Berlin-1939 Employment Josef Stein Berlin-1939 Family life Gretchen Stein Anna Stein interview time Dresden-1939 Relocation Transportation-rail Dresden-1939 Schooling Gunter Wendt Maria
Table 5. Mentions of relevance criteria by searchers Workshops 1 and 2
Topicality Total mentions by 8 searchers Workshops 1 and 2