Download

1 / 35
360 likes | 563 Views
Hidden Markov Models (HMMs). Probabilistic Automata Ubiquitous in Speech/Speaker Recognition/Verification Suitable for modelling phenomena which are dynamic in nature Can be used for handwriting, keystroke biometrics. Classification with Static Features. Simpler than dynamic problem

E N D
Hidden Markov Models (HMMs) • Probabilistic Automata • Ubiquitous in Speech/Speaker Recognition/Verification • Suitable for modelling phenomena which are dynamic in nature • Can be used for handwriting, keystroke biometrics
Classification with Static Features • Simpler than dynamic problem • Can use, for example, MLPs • E.g. In two dimensional space: o x x o o x o x o x o x x o
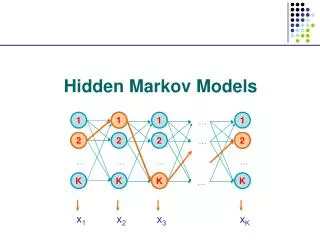
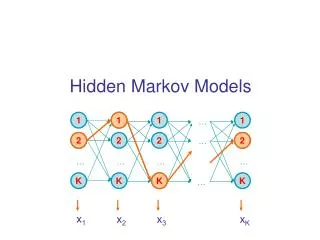
Hidden Markov Models (HMMs) • First: Visible VMMs • Formal Definition • Recognition • Training • HMMs • Formal Definition • Recognition • Training • Trellis Algorithms • Forward-Backward • Viterbi
Visible Markov Models • Probabilistic Automaton • Ndistinct statesS = {s1, …, sN} • M-element output alphabetK = {k1, …, kM} • Initial state probabilitiesΠ = {πi}, i S • State transition att = 1, 2,… • State trans. probabilitiesA = {aij}, i,j S • State sequenceX = {X1, …, XT}, Xt S • Output seq.O = {o1, …, oT}, ot K
Generative VMM • We choose the state sequenceprobabilistically… • We could try this using: • the numbers 1-10 • drawing from a hat • an ad-hoc assignment scheme
2 Questions • Training Problem • Given an observation sequenceOand a “space” of possible models which spans possible values for model parameters w = {A, Π}, how do we find the model that best explains the observed data? • Recognition (decoding) problem • Given a modelwi = {A, Π}, how do we compute how likely a certain observation is, i.e. P(O | wi) ?
Training VMMs • Given observation sequencesOs, we want to find model parameters w = {A, Π} which best explain the observations • I.e. we want to find values forw = {A, Π} that maximisesP(O | w) • {A, Π} chosen = argmax {A, Π} P(O | {A, Π})
Training VMMs • Straightforward for VMMs • frequency in state i at time t =1 (number of transitions fromstate i to state j) ------------------------------------------------------------------------------------------------------------------------------------------------------------------------- (number of transitions fromstatei) = (number of transitions fromstate i to statej) ------------------------------------------------------------------------------------------------------------------------------------------------------------------------- (number of times in statei)
Recognition • We need to calculate P(O | wi) • P(O | wi)is handy for calculatingP(wi|O) • If we have a set of modelsL = {w1,w2,…,wV} then if we can calculateP(wi|O) we can choose the model which returns the highest probability, i.e. • wchosen = argmax wi L P(wi|O)
Recognition • Why is P(O | wi) of use? • Let’s revisit speech for a moment. • In speech we are given a sequence of observations, e.g. a series of MFCC vectors • E.g. MFCCs taken from frames of length 20-40ms, every 10-20 ms • If we have a set of modelsL = {w1,w2,…,wV} and if we can calculateP(wi|O) we can choose the model which returns the highest probability, i.e. wchosen = argmax wi L P(wi|O)
wchosen = argmax wi L P(wi|O) • P(wi|O) difficult to calculate as we would have to have a model for every possible observation sequence O • Use Bayes’ rule: P(x | y) = P (y | x) P(x) / P(y) • So now we have wchosen = argmax wi L P(O |wi) P(wi) / P(O) • P(wi) can be easily calculated • P(O) is the same for each calculation and so can be ignored • SoP(O |wi) is the key!!!
Hidden Markov Models • Probabilistic Automaton • Ndistinct statesS = {s1, …, sN} • M-element output alphabetK = {k1, …, kM} • Initial state probabilitiesΠ = {πi}, i S • State transition att = 1, 2,… • State trans. probabilitiesA = {aij}, i,j S • Symbol emission probabilities B = {bik}, i S, k K • State sequenceX = {X1, …, XT}, Xt S • Output sequenceO = {o1, …, oT}, ot K
State Emission Distributions Discrete probability distribution
State Emission Distributions Continuous probability distribution
Generative HMM • Now we not only choose the state sequence probabilistically… • …but also the state emissions • Try this yourself using the numbers 1-10 and drawing from a hat...
3 Questions • Recognition (decoding) problem • Given a modelwi = {A, B, Π}, how do we compute how likely a certain observation is, i.e.P(O | wi) ? • State sequence? • Given the observation sequence and a model how do we choose a state sequenceX = {X1, …, XT} that best explains the observations • Training Problem • Given an observation sequenceOand a “space” of possible models which spans possible values for model parameters w = {A, B, Π}, how do we find the model that best explains the observed data?
ComputingP(O | w) • For any particular state sequenceX = {X1, …, XT} we have and
ComputingP(O | w) • This requires(2T) NTmultiplications • Very inefficient!
Trellis Algorithms • Array of states vs. time
Trellis Algorithms • Overlap in paths implies repetition of the same calculations • Harness the overlap to make calculations efficient • A node at (si , t) stores info about state sequences that contain Xt = si
Trellis Algorithms • Consider 2 states and 3 time points:
Forward Algorithm • A node at(si , t)stores info about state sequences up to timetthat arrive at si s1 sj s2
Backward Algorithm • A node at(si , t)stores infoabout state sequences from timetthat evolve fromsi s1 si s2
Forward & Backward Algorithms • P(O | w) as calculated from the forward and backward algorithms should be the same • FB algorithm usually used in training • FB algorithm not suited to recognition as it considers all possible state sequences • In reality, we would like to only consider the “best” state sequence (HMM problem 2)
“Best” State Sequence • How is “best” defined? • We could choose most likely individual state at each timet:
Viterbi Algorithm …may produce an unlikely or even invalid state sequence • One solution is to choose the most likely state sequence:
Viterbi Algorithm • Define is the best score along a single path, at time t, which accounts for the firsttobservations and ends in statesi By induction we have:
Viterbi vs. Forward Algorithm • Similar in implementation • Forward sums over all incoming paths • Viterbi maximises • Viterbi probability Forward probability • Both efficiently implemented using a trellis structure