Download

1 / 31
310 likes | 415 Views
Crescando : Predictable Performance for Unpredictable Workloads. G. Alonso , D. Fauser , G. Giannikis, D. Kossmann, J. Meyer, P. Unterbrunner Amadeus S.A. ETH Zurich, Systems Group ( Funded by Enterprise Computing Center) . Overview. Background & Problem Statement Approach

E N D
Crescando: Predictable Performance forUnpredictableWorkloads G. Alonso, D. Fauser, G. Giannikis, D. Kossmann, J. Meyer, P. Unterbrunner Amadeus S.A. ETH Zurich, Systems Group (Fundedby Enterprise Computing Center)
Overview • Background & Problem Statement • Approach • Experiments & Results
Amadeus Workload • Passenger-Booking Database • ~ 600 GB of rawdata (twoyears of bookings) • singletable, denormalized • ~ 50 attributes: flight-no, name, date, ..., manyflags • Query Workload • up to 4000 queries / second • latencyguarantees: 2 seconds • today: onlypre-cannedqueriesallowed • Update Workload • avg. 600 updates per second (1 update per GB per sec) • peak of 12000 updates per second • datafreshnessguarantee: 2 seconds
Amadeus Query Examples • Simple Queries • Printpassenger list of Flight LH 4711 • Giveme LH honcirclefrom Frankfurt to Delhi • ComplexQueries • Giveme all Heathrow passengersthatneedspecialassistance (e.g., afterterrorwarning) • Problems withState-of-the Art • Simple queriesworkonlybecause of mat. views • multi-monthproject to implementnewquery / process • Complexqueries do notwork at all
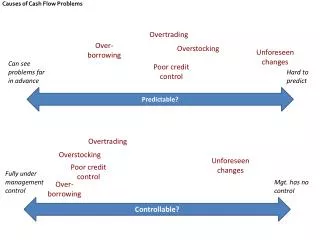
Why trad. DBMS are a pain? • Performance depends on workloadparameters • changes in update rate, queries, ... -> hugevariance • impossible / expensive to predict and tune correctly
Goals • Predictable (= constant) Performance • independent of updates, querytypes, ... • MeetSLAs • latency, datafreshness • AffordableCost • ~ 1000 COTS machinesare okay • (compare to mainframe) • MeetConsistencyRequirements • monotonicreads (ACID notneeded) • Respect Hardware Trends • main-memory, NUMA, large datacenters
SelectedRelatedWork • L. Qiao et. al. Main-memory scan sharing for multi-core CPUs. VLDB '08 • Cooperative main-memory scans for ad-hoc OLAP queries (read-only) • P. Boncz, M. Zukowski, and N. Nes. MonetDB/X100: Hyper-pipelining query execution. CIDR ’05 • Cooperative scans over vertical partitions on disk • K. A. Ross. Selection conditions in main memory. In ACM TODS, 29(1), 2004. • S. Chandrasekaran and M. J. Franklin. Streaming queries over streaming data VLDB '02 • “Query-data join” • G. Candea, N. Polyzotis, R. Vingralek. A Scalable, Predictable Join Operator for Highly Concurrent Data Warehouses. VLDB ’09 • An “always on” join operator based on similar requirements and design principles
Overview • Background & Problem Statement • Approach • Experiments & Results
WhatisCrescando? • A distributed (relational) table: MM on NUMA • horizontallypartitioned • distributedwithin and acrossmachines • Query / update interface • SELECT * FROM table WHERE <anypredicate> • UPDATE table SET <anything> WHERE <anypredicate> • monotonicreads / writes (SI within a singlepartition) • Someniceproperties • constant / predictablelatency & datafreshness • solvesthe Amadeus usecase
Design • Operate MM likedisk in shared-nothingarchitect. • Core ~ Spindle(manycores per machine & datacenter) • all datakept in mainmemory (log to diskforrecovery) • eachcorescansonepartition of data all the time • Batchqueries and updates: sharedscans • do trivial MQO (at scanlevel on systemwithsingletable) • controlread/updatepattern -> no datacontention • Index queries / notdata • just as in thestreamprocessingworld • predictable+optimizable: rebuildindexesevery second • Updates areprocessedbeforereads
{record, {query-ids} } results Queries + Upd. records Crescando on 1 Core datapartition
Scanning a Partition Merge cursors
Scanning a Partition Build indexes for next batch of queries and updates Merge cursors
Crescando @ Amadeus Transactions (OLTP) Queries (Oper. BI) Mainframe Aggregator Aggregator Key / Value Aggregator Aggregator Aggregator Query / {Key} Update stream (queue) Store (e.g., S3) Store (e.g., S3) CrescandoNodes
Implementation Details • Optimization • decideforbatch of querieswhichindexes to build • runsonceevery second (mustbe fast) • Query + update indexes • different indexesfor different kinds of predicates • e.g., hashtables, R-trees, tries, ... • must fit in L2 cache (better L1 cache) • Probe indexes • Updates in right order, queries in any order • Persistence & Recovery • Log updates / inserts to disk (not a bottleneck)
Crescando in the Cloud Client HTTP XML, JSON, HTML Web Server FCGI, ... XML, JSON, HTML App Server SQL records DB Server get/put block Store
Crescando in the Cloud Client Client Client Client HTTP XML, JSON, HTML Web Server Workload Splitter XML, JSON, HTML FCGI, ... XML, JSON, HTML Web/AppAggregator Web/AppAggregator App Server queries/updates <-> records SQL records Store (e.g., S3) Store (e.g., S3) CrescandoNodes DB Server get/put block Store
Overview • Background & Problem Statement • Approach • Experiments & Results
Benchmark Environment • Crescando Implementation • Shared library for POSIX systems • Heavily optimized C++ with some inline assembly • Benchmark Machines • 16 core Opteron machine with 32 GB DDR2 RAM • 64-bit Linux SMP kernel, ver. 2.6.27, NUMA enabled • Benchmark Database • The Amadeus Ticket view (one record per passenger per flight) • ~350byte per record; 47 attributes, many of them flags • Benchmarks use 15 GB of net data • Query + Update Workload • Current: Amadeus Workload (from Amadeus traces) • Predicted: Synthetic workload with varying predicate selectivity
Multi-core Scale-up 558.5 Q/s 10.5 Q/s 1.9 Q/s Round-robin partitioning, read-only Amadeus workload, vary number of threads
Latency vs. Query Volume thrashing, queueoverflows L1 cache L2 cache base latencyof scan Hash partitioning, read-only Amadeus workload, vary queries/sec
Latency vs. Concurrent Writes Hash partitioning, Amadeus workload, 2000 queries/sec, vary updates
Crescando vs. MySQL - Latency updates + big queries cause massive queuing s = 1.4: 1 / 3,000 queriesdo not hit an index s = 1.5: 1 / 10,000 queriesdo not hit an index 16s = time for full-tablescan in MySQL Amadeus workload, 100 q/sec, vary updates Synthetic read-only workload, vary skew
Crescando vs. MySQL - Throughput read-only workload! Amadeus workload, vary updates Synthetic read-only workload, vary skew
Summary of Experiments • high concurrent query + update throughput • Amadeus: ~4000 queries/sec + ~1000 updates/sec • updates do not impact latency of queries • predictable and guaranteed latency • depends on size of partition: not optimal, good enough • cost and energy effeciency • depends on workload: great for hot data, heavy WL • consistency: write monotonicity, can build SI on top • works great on NUMA! • controls read+write pattern • linear scale-up with number of cores
Status & Outlook • Status • Fully operational system • Extensive experiments at Amadeus • Production: Summer 2011 (planned) • Outlook • Columnstorevariant of Crescando • Compression • E-cast: flexible partitioning & replication • Joinsovernormalizeddata, Aggregation, ...
Conclusion • A new way to processqueries • Massively parallel, simple, predictable • Not always optimal, butalways good enough • Ideal for operational BI • High querythroughput • Concurrentupdateswithfreshnessguarantees • Great building block formanyscenarios • Rethinkdatabase and storagesystemarchitecture