Download

1 / 56
570 likes | 792 Views
SZTUCZNE SIECI NEURONOWE. dr hab.inż. Krzysztof Zaremba Instytut Radioelektroniki Politechnika Warszawska. Historia dziedziny. „Prehistoria” Początki 1943 – W.McCulloch, W.Pitts – pierwszy formalny model neuronu;

E N D
SZTUCZNE SIECI NEURONOWE dr hab.inż. Krzysztof Zaremba Instytut Radioelektroniki Politechnika Warszawska
Historia dziedziny • „Prehistoria” • Początki • 1943 – W.McCulloch, W.Pitts – pierwszy formalny model neuronu; • 1949 – Donald Hebb – „The organization of behaviour” – reguła uaktualniania wag połączeń neuronów.
Historia dziedziny • Pierwsze sukcesy • 1957-58 – F.Rosenblatt, Ch. Wightman – PERCEPTRON; • 1960 – B.Widrow, M.Hoff – ADALINE; • 1965 – N.Nillson – publikacja „Learning Machines”
Historia dziedziny • Okres zastoju • 1969 – M.Minsky, S.Papert – publikacja „Perceptrons” • 1972, 1977 – Sun Ichi Amari – matematyczny opis sieci; • 1980 - K. Fukushima – NEOCOGNITRON; • 1972-82 - T.Kohonen – pamięć skojarzeniowa • 1977 – J.A.Anderson – pamięć skojarzeniowa. • 1974,82 – S.Grossberg, G.Carpenter – teoria sieci rezonansowych.
Historia dziedziny • Ponowny rozkwit • ??????????????????????????? • 1983-86 – prace Johna Hopfielda; • 1986 - James McCleeland, David Rumelhard „Parallel Distributed Processing” – „odkrycie” metody uczenia perceptronów wielowarstwowych.
Historia dziedziny • Ponowny rozkwit • ??????????????????????????? • 1983-86 – prace Johna Hopfielda; • 1986 - James McCleeland, David Rumelhard „Parallel Distributed Processing” – „odkrycie” metody uczenia perceptronów wielowarstwowych. Metoda opublikowana wcześniej w pracy doktorskiej Paula Werbosa (1974 – Harvard).
Historia dziedziny • Ponowny rozkwit • DARPA (Defense Advanced Research Project Agency) – dr Ira Skurnick – finansowanie badań; • 1983-86 – prace Johna Hopfielda; • 1986 - James McCleeland, David Rumelhard „Parallel Distributed Processing” – „odkrycie” metody uczenia perceptronów wielowarstwowych. Metoda opublikowana wcześniej w pracy doktorskiej Paula Werbosa (1974 – Harvard).
Przykłady zastosowań: • Rozpoznawanie obrazów; • Rozpoznawanie i synteza mowy; • Analiza sygnałów radarowych; • Kompresja obrazów; • Prognozowanie sprzedaży; • Prognozowanie giełdy; • Interpretacja badań biologicznych i medycznych; • Diagnostyka układów elektronicznych; • Typowania w wyścigach konnych; • Dobór pracowników; • Selekcja celów śledztwa w kryminalistyce; • Typowanie w wyścigach konnych.....
KILKA PODSTAWOWYCH CECH MÓZGU • ODPORNY NA USZKODZENIA; • ELASTYCZNY – ŁATWO DOSTOSOWUJE SIĘ DO ZMIENNEGO OTOCZENIA; • UCZY SIĘ - NIE MUSI BYĆ PROGRAMOWANY; • POTRAFI RADZIĆ SOBIE Z INFORMACJĄ ROZMYTĄ, LOSOWĄ, ZASZUMIONĄ LUB NIESPÓJNĄ; • W WYSOKIM STOPNIU RÓWNOLEGŁY; • MAŁY, ZUŻYWA BARDZO MAŁO ENERGII.
KILKA PODSTAWOWYCH CECH MÓZGU Komputer „widzi” inaczej
KILKA PODSTAWOWYCH CECH MÓZGU Komputer „widzi” inaczej
KILKA PODSTAWOWYCH CECH MÓZGU • LICZBA POŁĄCZEŃ SYNAPTYCZNYCH W MÓZGU: 1010 – 1011; • GĘSTOŚĆ POŁĄCZEŃ SYNAPTYCZNYCH: ~ 104/NEURON; • CZĘSTOTLIWOŚĆ GENERACJI SYGNAŁÓW PRZEZ NEURON: ~ 1 – 100 Hz; • SZACUNKOWA SZYBKOŚĆ PRACY: ~ 1018 OPERACJI/S • (DLA PORÓWNANIA NAJSZYBSZE KOMPUTERY ~ 1012 OPERACJI/S.
PRZYSZŁOŚĆ - SZTUCZNY MÓZG ????? „If the human brain were so simple that we could undrestand it, we would be so simple that we couldn’t” - Emerson Pugh -
INSPIRACJE NEUROFIZJOLOGICZNE Neuron (komórka nerwowa)
INSPIRACJE NEUROFIZJOLOGICZNE Neuron (komórka nerwowa)
Model neuronu McCullocha-Pittsa w1 x0 Wi = 1 i=1,2,....,n x1 w2 T w3 x2 y . . . . . . xn wn Reguła pobudzenia neuronu:
Model neuronu McCullocha-PittsaPRZYKŁADY ELEMENTARNYCH FUNKTORÓW LOGICZNYCH x0 1 T=1 T=0 NOR x1 1 -1 y 1 x2 x0 -1 T=0 1 NAND T=1 x1 -1 T=0 1 y T=0 x2 -1 1
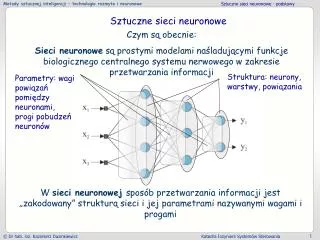
SZTUCZNA SIEĆ NEURONOWA Zbiór prostych elementów przetwarzających informację (sztucznych neuronów), które komunikują się między sobą za pomocą dużej liczby połączeń o zróżnicowanych wagach, zmienianych w procesie uczenia • GŁÓWNE ASPEKTY MODELOWANIA SIECI NEURONOWYCH: • Architektura (topologia) sieci • Strategia (reguła) uczenia sieci
SZTUCZNY NEURON x1 x2 . . . F(neti) yi wij yj xn i neti – efektywny stan wejścia neuronu i - zewnętrzne wzbudzenie (offset, bias)
TYPY NEURONÓW (TOPOLOGIA):- wejściowe; - ukryte;- wyjściowe. • SPOSÓB AKTUALIZACJI STANÓW NEURONÓW: • SYNCHRONICZNY – wszystkie neurony uaktualniają stan równocześnie; • ASYNCHRONICZNY: • w każdym kroku aktualizujemy stan jednego, losowo wybranego neuronu; • każdy neuron aktualizuje swój stan w sposób niezależny od innych, z pewnym, z reguły stałym, prawdopodobieństwem modyfikacji w czasie t.
FUNKCJA WZBUDZENIA NEURONU Przykładowe funkcje wzbudzenia: (a) (b) Funkcja progowa (a) i funkcja aktywacji perceptronu (b)
FUNKCJA WZBUDZENIA NEURONU Przykładowe funkcje wzbudzenia: y x Funkcja logistyczna (sigmoidalna): f(x) = 1/(1+e-x)
FUNKCJA WZBUDZENIA NEURONU Przykładowe funkcje wzbudzenia: y y (a) (b) x x Funkcja tangens hiperboliczny (a) i przeskalowany arcus tangens (b)
TOPOLOGIE (ARCHITEKTURY SIECI) y1 h1 X1 . . . . . . . . . . Ym hk Xn SIECI JEDNOKIERUNKOWE (FEEDFORWARD)
TOPOLOGIE (ARCHITEKTURY SIECI) 1 2 3 n 1 I1 I2 I3 In SIECI REKURENCYJNE
TOPOLOGIE (ARCHITEKTURY SIECI) • Podział ze względu na liczbę warstw: • Jednowarstwowe, dwuwarstwowe, .... • Jednowarstwowe, wielowarstwowe
METODY UCZENIA SIECI • Uczenie z nauczycielem (nadzorowane, asocjacyjne) • Uczenie bez nauczyciela (bez nadzoru) • GŁÓWNE REGUŁY MODYFIKACJI WAG: • REGUŁA HEBBA: • wij = •yi•yj • REGUŁA DELTA (WIDROWA-HOFFA): • wij = •(di – yi)•yj
ADALINE X0 w1 X1 w0 w2 X2 +1 w3 X3 Y’=sgn(y) y -1 w4 Xn Błąd odpowiedzi sieci: L – liczba wektorów w zbiorze uczącym;
ADALINE – metoda gradientowa uczenia Kształt „powierzchni błędu” i zasada maksymalnego spadku
ADALINE – metoda gradientowa uczenia Estymacja gradientu E:
ADALINE – metoda gradientowa uczenia • ALGORYTM UCZENIA SIECI: • Inicjalizuj wagi sieci jako niewielkie liczby losowe; • Oblicz wartość kwadratu błędu k(t); • k(t)= (dk-wTxk); • Oblicz zmianę wag w: • w(t) = 2k(t)xk; • Uaktualnij wektor wag w(t+1): • w(t+1)=w(t)+ w(t); • Powtarzaj kroki 1-4 dopóki błąd nie osiągnie akceptowalnej wartości.
ADALINE – metoda gradientowa uczenia (b) (a) Idealna (a) i rzeczywista (b) trajektoria końca wektora wag w procesie uczenia sieci.
PERCEPTRONY JEDNOWARSTWOWE . . . . . y w . . . . . x
PERCEPTRONY JEDNOWARSTWOWE Jednostki progowe: yi=sgn(neti+i) yi=sgn(wiTx) Dla i =0: Płaszczyzna decyzyjna: x2 x1 x1 w w i 0: i = 0:
REGUŁA UCZENIA PERCEPTRONU Jednostki nieliniowe: Funkcja błędu (kosztu):
FORMY NIELINIOWOSCI NEURONU Funkcja logistyczna: Bipolarna funkcja sigmoidalna: Funkcja tangens hiperboliczny:
PERCEPTRONY WIELOWARSTWOWE . . . . . y wskaźnik k wih . . . . . h wskaźnik h whj . . . . . wskaźnik j x
REGUŁA UCZENIA WARSTWY WYJŚCIOWEJ: REGUŁA UCZENIA WARSTWY UKRYTEJ:
PROBLEMY UCZENIA SIECI: • Minima lokalne • Paraliż sieci • Wolna zbieżność lub brak zbieżności; • Przetrenowanie sieci
Minima lokalne: Przykładowy „krajobraz” funkcji kosztu • Rozwiązania: • Wprowadzenie „bezwładności”; • Metoda symulowanego wyżarzania; • Uczenie genetyczne .....
Paraliż sieci: Niekorzystny punkt pracy Typowa nieliniowa charakterystyka neuronu Rozwiązanie: Właściwa inicjalizacja wag
Wolna zbieżność lub brak zbieżności: • – zbyt mała wartość współczynnika szybkości uczenia sieci; • - zbyt duża wartość współczynnika szybkości uczenia; • - prawidłowa wartość współczynnika szybkości uczenia.
„Przetrenowanie” sieci: Rozwiązanie: Właściwa struktura sieci oraz zbiorów: uczącego i testowego
Przykładowe zastosowanie: autopilot Parametry analizowane przez sieć Struktura sieci
UCZENIE BEZ NADZORU • Przykładowe zadania stawiany sieciom uczonym bez nadzoru: • Klasyfikacja (grupowanie); • Redukcja wymiarowości (kompresja); • Wyodrębnianie cech znaczących; • ...................
UCZENIE Z RYWALIZACJĄ (SIECI WTA – Winner Takes All) Neuron zwycięski y1 y2 ym . . . . . W . . . . . x1 x2 x3 xn Wektory wejść x i wag w znormalizowane do długości jednostkowej
Pobudzenie neuronu i: neti = wiT·x = cos() gdzie - kąt pomiędzy wektorami wi i x. Zwycięża neuron najsilniej pobudzony i na jego wyjściu pojawia się stan „1”, na wyjściach pozostałych – stan „0”. Uczony jest wyłącznie neuron zwycięski: Wi*j(t+1) = Wi*j(t) + [xjk - Wi*j(t)] (reguła Grossberga)
Idea uczenia konkurencyjnego: Uczenie konkurencyjne: (a)początkowe i (b) końcowe położenia końców wektorów wag. - koniec wektora danych; - koniec wektora wag.