Download

1 / 15
150 likes | 267 Views
Peter Shin, Charles Cowart Tony Fountain, Reagan Moore San Diego Supercomputer Center. Analyzing the NSDL Collection. Introduction. Education Impact and Evaluation Standing Committee (EIESC) Goal: Characterize the contents of the NSDL collection by topic, audience and type Motivation:

E N D
Peter Shin, Charles Cowart Tony Fountain, Reagan Moore San Diego Supercomputer Center Analyzing the NSDL Collection
Introduction Education Impact and Evaluation Standing Committee (EIESC) Goal: Characterize the contents of the NSDL collection by topic, audience and type Motivation: Enable search of the NSDL collection by subject, audience, and type Inform future collection activities
Research Focus Intelligent Information Retrieval (IR) for the NSDL community by providing efficient discovery and access to relevant materials Support queries on audience, topic, and type
Information Retrieval Techniques Keyword Searches Find a document that contains the list of words in the search. Example: digestive system -> “Digestive System Web Resources for Students” Relevance-based search, probabilistic approach Instead of the actual keywords, find documents that have words with similar meaning as in the query Example: break down food -> NCC Food Group’s Food Stuff; break down food body -> “Squirrel Tales” Text Categorization Given the contents of a document, assign topic labels. Hybrid or combination approaches Mix two or more of the above Example: First, keyword search , then text categorization
Challenges Not enough of metadata e.g audience type (intended grade level) Need metadata standards no structure in the metadata Example: Odd/Even Number – subject: number senses, No mathematics, algebra, or number theory No concept map or ontology to capture complex topic relationships Example: Relationship between algebra and calculus Need to make annotation easy and accurate Assist or automate labeling the documents with standard annotation Possible errors in the existing hand-labeled documents Example: mismatch between the contents of the front pages and their metadata Computationally intensive Over 20,000 HTML documents with over 1,300,000 unique terms
Suggestions Involve the community to define methods, sample queries and evaluation criteria, generate metadata, perform comparative studies Create a training/testing data set that is annotated and checked for correctness which can be used by all researchers Provide a forum for sharing methods and results Build an evaluation testbed – collect data, algorithms, tools, results, plus hardware and software, provide online web portal interface to the resources
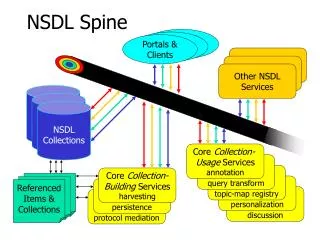
Status of the NSDL testbed at SDSC Monthly web crawl of the NSDL sites Persistent archive of the harvested materials Processing pipeline for various IR techniques Software Resources: Storage Resource Broker (SRB) NSDL Archive Service (Web Crawling) Various processing pipeline scripts that can run in parallel SVMLight by Thorsten Joachim Latent Semantic Indexing from Telecordia Latent Dirichlet Allocation by David Blei from UC Berkeley Cheshire – online catalog and full text retrieval system (from UC Berkeley and University of Liverpool) Hardware Resources: IBM Datastar – supercomputer with 10.4 teraflops of computing power TeraGrid – collection of supercomputers with high throughput communication
Summary Metadata evaluation is important and challenging. Information retrieval techniques are promising. NSDL community involvement is necessary to define evaluation methods. Collaborative testbed would facilitate analysis. An initial testbed is under development at SDSC.
Latent Semantic Indexing (LSI) Assumption: If documents have many words in common, the documents are closely related. Application: Search Engine Archivist’s Assistance Automated Writing Assessment Information Filtering Drawbacks: Not scalable No incremental update
Clustering before LSI Idea: Instead of searching in the whole space, search within the concept space. Task: Define the levels of granularity in the document space. Cluster the documents according to the concept space Apply LSI within a cluster.
Process HTML Documents List of Words Strip Formatting Pick out content words using “stop lists” Stemming Build concept clusters Each document in the Term Document Matrix is a “vector” Term Weighting Discard words that appear too frequently or too sparsely Apply LSI within A cluster
Levels of Granularity Subsection Section Collection Document
Collection Document Section Subsection Building a Concept Space Co-Adjacent Granules Finer Granularity Co-Adjacent Granules
Hypotheses Definition: Significant terms: Defined by the frequency of words in a granule Hypotheses: As the granularity becomes finer, the number of significant terms in a granule goes down. Within one granule, the overlapping significant terms around the specific space decrease as it moves further from it. Appropriate level of granularity for a knowledge is when the number of significant terms is the maximum and the number of overlapping significant terms around the space is minimum.
Sample Data Web Crawl On each document, web crawl written by Charles Cowart gathers 20 levels deep. Size: 200 GB and 1.7 million files