Download

1 / 22
220 likes | 484 Views
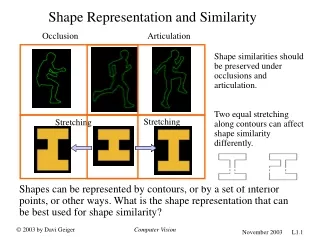
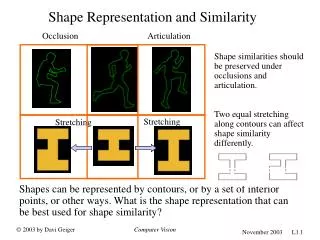
Shape Classification Based on Skeleton Path Similarity. Xingwei Yang, Xiang Bai, Deguang Yu, and Longin Jan Latecki. Shape similarity. The goal of the shape similarity is using the information of the shape to recognize it like human’s perception. . Contour

E N D
Shape Classification Based on Skeleton Path Similarity Xingwei Yang, Xiang Bai, Deguang Yu, and Longin Jan Latecki
Shape similarity • The goal of the shape similarity is using the information of the shape to recognize it like human’s perception.
Contour Advantage: it is easy to implement and similar to human’s perception. Disadvantage: it will meet problems on the articulated shapes. Skeleton Advantage: it is not sensitive to the distortion of the articulated shape compared to contour. Disadvantage: it is sensitive to the noise of contour. Two main kinds of methods
The main content of this talk • 1. obtaining the skeleton which is insensitive to the contour noise. • 2. introducing a skeleton representation. • 3. Implementing the skeleton into Bayesian classifier to recognize shapes. • 4. show results and discuss
Skeleton Pruning by Contour Partitioning with DiscreteCurve Evolution • 1.1 The need for skeleton pruning
Skeleton Pruning by Contour Partitioning with DiscreteCurve Evolution • 1.2 using Discrete Curve Evolution to simplify the contour • where line segments s1, s2 are the polygon sides incident to a common vertex v, ß(s1, s2) is the turn angle at the common vertex v, l is the length function.
Skeleton Pruning by Contour Partitioning with DiscreteCurve Evolution
Skeleton Pruning by Contour Partitioning with DiscreteCurve Evolution • 1.3 More results
Skeleton representation • The endpoint in the skeleton graph is called an end node, and the junction point in the skeleton graph is called a junction node. The shortest path between a pair of end nodes on a skeleton graph is called a skeleton path. We show a few example skeleton paths
Skeleton representation • The shortest paths between every pair of skeleton endpoints are represented as sequences of radii of the maximal disks at corresponding skeleton points. In our paper, the skeleton path is sampled to 50 points.
Implementing the skeleton into Bayesian classifier • The shape dissimilarity between two skeleton paths is called a path distance. The path distance pd between sp and sp’ is: • ri is radius of the i th point on the skeleton path
Implementing the skeleton into Bayesian classifier • Given a shape ω' that should be classified by Bayesian Classifier, we build the skeleton graph G(ω') of ω' and input G(ω') as the query. For a skeleton graph G(ω'), if the number of end nodes is n, the corresponding number of paths is n(n-1) . Then, the Bayesian Classifier computes the posterior probability of all classes for each path sp'∈G(ω'). By accumulating the posterior probability of all of the paths of G(ω'), the system automatically yields the ranking of class hypothesis.
Implementing the skeleton into Bayesian classifier • If two different paths have small pd value, the value of probability should be large. Otherwise, it should be small. Therefore, we use Gaussian distribution to compute the probability p:
Implementing the skeleton into Bayesian classifier • The class-conditional probability for observing sp' given that ω' belongs to class ci is: • We assume that all paths within a class path set are equiprobable, therefore ci is one of the M classes.
Implementing the skeleton into Bayesian classifier • The posterior probability of a class given that path sp'∈G(ω') is determined by Bayes rule:
Implementing the skeleton into Bayesian classifier • Similar to the above assumption, p(ci)=1/M. The probability of sp' is equal to
Implementing the skeleton into Bayesian classifier • By summing the posterior probabilities of a class over the set of paths in the input shape, we obtain the probability that the input shape belongs to a given class. Obviously, the biggest one, Cm, is the class that input shape belongs to
Experiments • The table is composed of 14 rows and 9 columns. The first column of the table represents the class of each row. For each row, there are four experimental results which belong to the same class. Each experimental result has two elements. The first one is the query shape and the second one is the classification result of our system. If the result is correct, it should be the equal to the first column of the row. The red numbers mark the wrong classes assigned to query objects. Since there is only one error in 56 classification results, the classification accuracy in percentage by this measure is 98.2%.
Experiments • The results of the proposed method
Experiments • The results of Super and Sun’s method


![[Image Similarity Based on Histogram]](https://cdn0.slideserve.com/1309335/image-similarity-based-on-histogram-dt.jpg)













![[Image Similarity Based on Histogram]](https://cdn5.slideserve.com/9279474/image-similarity-based-on-histogram-dt.jpg)