Download
1 / 40
400 likes | 521 Views
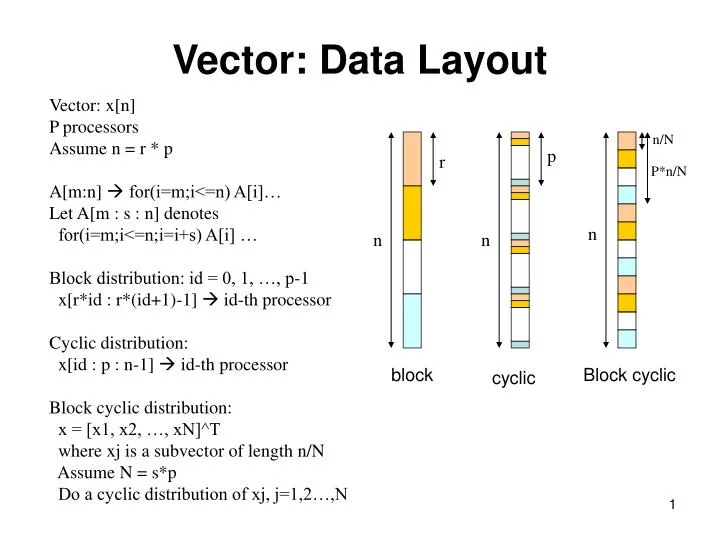
n/N. r. p. P*n/N. n. n. n. block. Block cyclic. cyclic. Vector: Data Layout. Vector: x[n] P processors Assume n = r * p A[m:n] for(i=m;i<=n) A[i]… Let A[m : s : n] denotes for(i=m;i<=n;i=i+s) A[i] … Block distribution: id = 0, 1, …, p-1

E N D
n/N r p P*n/N n n n block Block cyclic cyclic Vector: Data Layout Vector: x[n] P processors Assume n = r * p A[m:n] for(i=m;i<=n) A[i]… Let A[m : s : n] denotes for(i=m;i<=n;i=i+s) A[i] … Block distribution: id = 0, 1, …, p-1 x[r*id : r*(id+1)-1] id-th processor Cyclic distribution: x[id : p : n-1] id-th processor Block cyclic distribution: x = [x1, x2, …, xN]^T where xj is a subvector of length n/N Assume N = s*p Do a cyclic distribution of xj, j=1,2…,N
Matrix: Data Layout Row: block, cyclic, block cyclic Column: block, cyclic, block cyclic Matrix: 9 combinations If only one block in one direction 1D decomposition Otherwise 2D decomposition e.g. p processors with a (Nx, Ny) virtual topology, p=Nx*Ny Matrix A[n][n], n = rx * Nx = ry * Ny A[rx*I : rx*(I+1)-1, J:Ny:n-1], I=0,…,rx-1, J=0,…,ry-1, is a 2D decomposition, block distribution in x direction, cyclic distribution in y direction 1D block cyclic 2D block cyclic
A X Y cpu 0 cpu 0 cpu 0 Y1 A11 A12 A13 X1 cpu 1 cpu 1 cpu 1 = A21 A22 A23 X2 Y2 cpu 2 cpu 2 cpu 2 X3 A31 A32 A33 Y3 Y1 Y1 A11 A11 A12 A12 A13 A13 X3 X2 = = A21 A21 A22 A22 A23 A23 X3 X1 Y2 Y2 X2 X1 A31 A31 A32 A32 A33 A33 Y3 Y3 Matrix-Vector Multiply: Row-wise AX=Y A – NxN matrix, row-wise block distribution X,Y – vectors, dimension N Y1 = A11*X1 + A12*X2 + A13*X3 Y2 = A21*X1 + A22*X2 + A23*X3 Y3 = A31*X1 + A32*X2 + A33*X3 Y1 = A11*X1 + A12*X2 + A13*X3 Y2 = A21*X1 + A22*X2 + A23*X3 Y3 = A31*X1 + A32*X2 + A33*X3 Y1 = A11*X1 + A12*X2 + A13*X3 Y2 = A21*X1 + A22*X2 + A23*X3 Y3 = A31*X1 + A32*X2 + A33*X3
A X Y Y1 cpu 0 cpu 0 cpu 0 A11 A12 A13 X1 = A21 A22 A23 cpu 1 cpu 1 cpu 1 X2 Y2 X3 cpu 2 cpu 2 cpu 2 A31 A32 A33 Y3 Y2 A11 A12 A13 X1 = A21 A22 A23 X2 Y3 X3 A31 A32 A33 Y1 Y3 A11 A12 A13 X1 = A23 A21 A22 X2 Y1 X3 A31 A32 A33 Y2 Matrix-Vector Multiply: Column-wise AX=Y A – NxN matrix, column-wise block distribution X,Y – vectors, dimension N Y1 = A11*X1 + A12*X2 + A13*X3 Y2 = A21*X1 + A22*X2 + A23*X3 Y3 = A31*X1 + A32*X2 + A33*X3 Y2 = A21*X1 + A22*X2 + A23*X3 Y3 = A31*X1 + A32*X2 + A33*X3 Y1 = A11*X1 + A12*X2 + A13*X3 Y3 = A31*X1 + A32*X2 + A33*X3 Y1 = A11*X1 + A12*X2 + A13*X3 Y2 = A21*X1 + A22*X2 + A23*X3
Matrix-Vector Multiply: Row-wise All-gather
A X Y cpu 0 Y1 A11 A12 A13 X1 cpu 1 = A21 A22 A23 X2 Y2 cpu 2 X3 A31 A32 A33 Y3 Matrix-Vector Multiply: Column-wise AX=Y A – NxN matrix, column-wise block distribution X,Y – vectors, dimension N First local computations Y1’ = A11*X1 Y2’ = A21*X1 Y3’ = A31*X1 Y1’ = A12*X2 Y2’ = A22*X2 Y3’ = A32*X2 Y1’ = A13*X3 Y2’ = A23*X3 Y3’ = A33*X3 Then reduce-scatter across processors
Matrix-Vector Multiply: 2D Decomposition x A P=K^2 number of cpus As a 2D KxK mesh A – K x K block matrix, each block (N/K)x(N/K) X – K x 1 blocks, each block (N/K)x1 Each block of A is distributed to a cpu X is distributed to the K cpus in last column Result A*X be distributed on the K cpus of the last column
Homework • Write an MPI program and implement the matrix vector multiplication algorithm with 2D decomposition • Assume: • Y=A*X, A – NxN matrix, X – vector of length N • Number of processors P=K^2, arranged as a K x K mesh in a row-major fashion, i.e. cpus 0, …, K-1 in first row, K, …, 2K-1 in 2nd row, etc • N can be divided by K. • Initially, each cpu has the data for its own submatrix of A; Input vector X is distributed on processors of the rightmost column, i.e. cpus K-1, 2K-1, …, P-1 • In the end, the result vector Y should be distributed on processors at the rightmost column. • A[i][j] = 2*i+j, X[i] = i; • Make sure your result is correct using a small value of N • Turn in: • Source code + binary • Wall-time and speedup vs. cpu for 1, 4, 16 processors for N = 1024.
Cyclic Distribution Matrix-vector multiply, row-wise cyclic distribution of A and y Block distribution of x Initial data: id – cpu id p – number of cpus ids of left/right neighbors n – matrix dimension, n=r*p Aloc = A(id:p:n-1,:) yloc = y(id:p:n-1) xloc = x(id*r:(id+1)*r-1) r = n/p for t=0:p-1 send(xloc,left) s = (id+t)%p // xloc = x(s*r:(s+1)*r-1) for i=0:r-1 for j=0:min(id+i*p-s*r,r) yloc(j) += Aloc(i,j+s*r)*xloc(j) end end recv(xloc,right) end
Matrix Multiplication A – m x p B – p x n C – m x n C = AB + C Row: A(i,:) = [Ai1, Ai2, …, Ain] Column: A(:,j) = [A1j, A2j, …, Anj]^T Submatrix: A(i1:i2,j1:j2) = [ A(i,j) ], i1<=i<=i2, j1<=j<=j2 for i=1:m for j=1:n for k=1:p C(i,j) = C(i,j)+A(i,k)*B(k,j) end end end (ijk) variant of matrix multiplication for i=1:m for j=1:n C(i,j) = C(i,j)+A(i,:)B(:,j) end end Dot product formulation A(i,:) dot B(:,j) A accessed by row B accessed by column Non-optimal memory access!
Matrix Multiply ijk loop can be arranged in other orders (ikj) variant for i=1:m for k=1:p for j=1:n C(i,j) = C(i,j) + A(i,k)B(k,j) end end end axpy formulation B by row C by row for i=1:m for k=1:p C(i,:) = C(i,:) + A(i,k)B(k,:) end end (jki) variant for j=1:n for k=1:p for i=1:m C(i,j) = C(i,j)+A(i,k)B(k,j) end end end for j=1:n for k=1:p C(:,j) = C(:,j)+A(:,k)B(k,j) end end axpy formulation A by column C by column
Block Matrices Block matrix multiply A, B, C – NxN block matrices each block: s x s (mnp) variant for m=1:N for n = 1:N for p = 1:N i=(m-1)s+1 : ms j = (n-1)s+1 : ns k = (p-1)s+1 : ps C(i,j) = C(i,j) + A(i,k)B(k,j) end end end also other variants Cache blocking
Matrix Multiply: Column-wise C A B = C1 = A1*B11 + A2*B21 + A3*B31 cpu 0 C2 = A1*B12 + A2*B22 + A3*B32 cpu 1 C3 = A1*B13 + A2*B23 + A3*B33cpu 2 A, B, C – NxN matrices P – number of processors A1, A2, A3 – Nx(N/P) matrices C1, C2, C3 - … Bij – (N/P)x(N/P) matrices Column-wise decomposition
Matrix Multiply: Row-wise = C1 = A11*B1 + A12*B2 + A13*B3 cpu 0 C2 = A21*B1 + A22*B2 + A23*B3 cpu 1 C3 = A31*B1 + A32*B2 + A33*B3 cpu 2 A, B, C – NxN matrices P – number of processors B1, B2, B3 – (N/P)xN matrices C1, C2, C3 - … Aij – (N/P)x(N/P) matrices
Matrix Multiply: 2D DecompositionHypercube-Ring Cpus: P = K^2 Matrices A, B, C: dimension N x N, K x K blocks Each block: (N/K) x (N/K) Determine coordinate (irow,icol) of current cpu. Set B’=B_local For j=0:K-1 root_col = (irow+j)%K broadcast A’=A_local from root cpu (irow,root_col) to other cpus in the row C_local += A_local*B_local shift B’ upward one step end broadcast Broadcast A diagonals Shift B C fixed Step 1 Step 2 shift Step 2
Matrix Multiply • Total ~K*log(K) communication steps, or sqrt(P)log(sqrt(P)) steps • In contrast, 1D decomposition, P communication steps • Can use max N^2 processors for problem size NxN matrices • 1D decomposition, max N processors
Matrix Multiply: Ring-Hypercube Determine coordinate (irow,icol) of current cpu. Set A’=A_local For j=0:K-1 root_row = (icol+j)%K broadcast B’=B_local from root cpu (root_row,icol) to other cpus in the column C_local += A_local*B_local Shift A’ leftward one step end Shift A columns Broadcast B diag C fixed Step 1 Step 2 Number of cpus: P=K^2 A, B, C: K x K block matrices each block: (N/K) x (N/K)
compute initial Broadcast B Shift A broadcast Shift A Broadcast B compute Matrix Multiply: Ring-Hypercube
B A Matrix Multiply: Systolic (Torus) C fixed Number of cpus: P=K^2 A, B, C: K x K block matrices each block: (N/K) x (N/K) Shift rows of A leftward Shift columns of B upward initial Step 1 Step 2 Step 3
Matrix Multiply: Systolic P = K^2 number of processors, as a K x K 2D torus A, B, C: KxK block matrices, each block (N/K)x(N/K) Each cpu computes 1 block: A_loc, B_loc, C_loc Coordinate in torus of current cpu: (irow, icol) Ids of left, right, top, bottom neighboring processors // first get appropriate initial distribution for j=0:irow-1 send(A_loc,left); recv(A_loc,right) end for j=0:icol-1 send(B_loc,top); recv(B_loc,bottom) end // start computation for j=0:K-1 send(A_loc,left) send(B_loc,top) C_loc = C_loc + A_loc*B_loc recv(A_loc,right) recv(B_loc,bottom) end Max N^2 processors ~ sqrt(P) communication steps
Matrix Multiply on P=K^3 CPUs Assume: A, B, C: dimension N x N P = K^3 number of processors Organized into K x K x K 3D mesh A (NxN) can be considered as a q x q block matrix, each block (N/q)x(N/q) Let q = K^(1/3), i.e. consider A as a K^(1/3) x K^(1/3) block matrix, each block being (N/K^(1/3)) x (N/K^(1/3)) Similar for B and C
Matrix Multiply on K^3 CPUs r,s = 1, 2, …, K^(1/3) Total K^(1/3)*K^(1/3)*K^(1/3) = K block matrix multiplications Idea: Perform these K matrix multiplications on the K different planes (or levels) of the 3D mesh of processors. Processor (i,j,k) (i,j=1,…,K) belongs to plane k. Will perform multiplication A_{rt}*B_{ts}, where k = (r-1)*K^(2/3)+(s-1)*K^(1/3)+t Within a plane, (N/K^(1/3)) x (N/K^(1/3)) matrix multiply on K x K processors. Use the systolic multiplication algorithm. Within a plane k: A_{rt}, B_{ts} and C_{rs} decomposed into K x K block matrices, each block (N/K^(4/3)) x (N/K^(4/3)).
x N/K^(1/3) dimension A, B, C K^(1/3) blocks K blocks B_{ts} A_{rt} Matrix Multiply (i,j) On KxK processors A_{rt} destined to levels k=(r-1)*K^(2/3)+(s-1)K^(1/3)+t, for all s=1,…,K^(1/3) B_{ts} destined to levels k=(r-1)*K^(2/3)+(s-1)*K^(1/3)+t, for all r=1,…,K^(1/3) Initially, processor (i,j,1) has (i,j) sub-blocks of all A_{rt} and B_{ts} blocks, for all r,s,t=1,…,K^(1/3), i,j=1,…,K Initial data distribution
Matrix Multiply // set up input data On processor (i,j,1), read in the (i,j)-th block of matrices A_{r,t} and B_{t,s}, 1<= r,s,t <= K^(1/3); pass data onto processor (i,j,2); On processor (i,j,m), make own copy of A_{rt} if m=(r-1)*K^(2/3)+(s-1)*K^(1/3)+t for some s=1,...,K^(1/3); make own copy of B_{ts} if m=(r-1)*K^(2/3)+(s-1)*K^(1/3)+t for some r=1,...,K^(1/3); pass data onward to (i,j,m+1); // Computation On each processor (i,j,m), Compute A_{rt}*B_{ts} on the K x K processors using the systolic matrix multiplication algorithm; Some initial data setup may be needed before multiplication; // Summation Determine (r0,s0) of matrix the current processor (i,j,k) works on: r0 = k/K^(2/3)+1; s0 = (k-(r0-1)*K^(2/3))/K^(1/3); Do reduction (sum) over processors (i,j,m), m=(r0-1)*K^(2/3)+(s0-1)*K^(1/3)+t, of all 1<=t<=K^(1/3);
Matrix Multiply • Communication steps: ~K, or P^(1/3) • Maximum CPUs: N/K^(4/3) = 1 K=N^(3/4), or P=N^(9/4)
Matrix Multiply • If number of processors: P = KQ^2, arranged into KxQxQ mesh • K planes • Each plane QxQ processors • Handle similarly • Decompose A, B, C into K^(1/3)xK^(1/3) blocks • Different block matrix multiplications in different planes, K multiplications total • Each block multiplication handled in a plane on QxQ processors; use any favorable algorithm, e.g. systolic
Processor Array in Higher Dimension • Processors P=K^4, arranged into KxKxKxK mesh • Similar strategy: • Divide A,B,C into K^(1/3)xK^(1/3) block matrices • Different multiplications (total K) computed on different levels of 1st dimension • Each block matrix multiplication done on the KxKxK mesh at one level; repeat the above strategy. • For even higher dimensions, P=K^n, n>4, handle similarly.
Matrix Multiply: DNS Algorithm Assume: A, B, C: dimension N x N P = K^3 number of processors Organized into K x K x K 3D mesh A, B, C are K x K block matrices, each block (N/K) x (N/K) Total K*K*K block matrix multiplications Idea: each block matrix multiplication is assigned to one processor Processor (i,j,k) computes C_{ij}=A_{ik}*B_{kj} Need a reduction (sum) over processors (i,j,k), k=0,…,K-1
Matrix Multiply: DNS Algorithm Initial data distribution: A_{ij} and B_{ij} at processor (i,j,0) Need to trasnsfer A_{ik} (i,k=0,…,K-1) to processor (i,j,k) for all j=0,1,…,K-1 Two steps: - Send A_{ik} from processor (i,k,0) to (i,k,k); - Broadcast A_{ik} from processor (i,k,k) to processors (i,j,k);
Matrix Multiply Send A_{ik} from (i,k,0) to (i,k,k) To broadcast A_{ik} from (i,k,k) to (i,j,k)
Matrix Multiply Final data distribution for A A can also be considered to come in through the (i,k) plane; with a broadcast along the j-direction.
B Distribution • B distribution: • Initially B_{kj} in processor (k,j,0); • Need to transfer to processors (i,j,k) for all i=0,1,…,K-1 • Two steps: • First send B_{kj} from (k,j,0) to (k,j,k) • Broadcast B_{kj} from (k,j,k) to (i,j,k) for all i=0,…,K-1, i.e. along i-direction
3,3 3,2 3,1 3,0 2,3 2,2 2,1 2,0 1,3 1,2 1,1 1,0 0,3 0,2 k 0,1 j 0,0 i B Distribution Send B_{kj} from (k,j,0) to (k,j,k) To broadcast from (k,j,k) to along i direction
Matrix Multiply Final B distribution: B can also be considered to come through (j,k) plane; then broadcast along i-direction
A_{ik} and B_{kj} on cpu (i,j,k) Compute C_{ij} locally Reduce (sum) C_{ij} along k-direction Final result: C_{ij} on cpu (i,j,0) Matrix Multiply
Matrix Multiply A matrix comes through (i,k) plane, broadcast along j-direction B matrix comes through (j,k) plane, broadcast along i-direction C matrix result goes to (i,j) plane Broadcast: 2log(K) steps Reduction: log(K) steps Total: 3log(K) = log(P) steps Can use a maximum of P=N^3 processors In contrast: Systolic: P^(1/2) communication steps Can use a maximum of P=N^2 processors Slide #24: P^(1/3) communication steps Can use a maximum of P=N^(9/4) processors






















