Download
1 / 1
10 likes | 155 Views
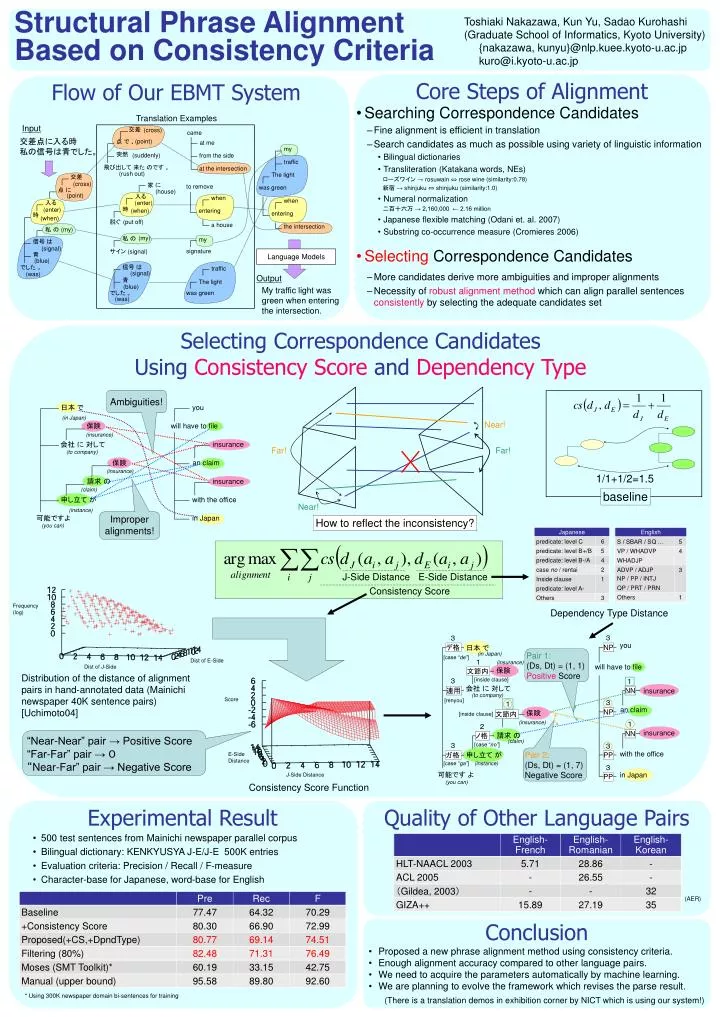
my. traffic. The light. was green. when. Frequency (log). entering. the intersection. 1/1+1/2=1.5. Dist of E-Side. Dist of J-Side. baseline. J-Side Distance. E-Side Distance. Consistency Score. 3. 3. you. デ格. NP. 日本 で. Pair 1: (Ds, Dt) = (1, 1) Positive Score. (in Japan).

E N D
my traffic The light was green when Frequency (log) entering the intersection 1/1+1/2=1.5 Dist of E-Side Dist of J-Side baseline J-Side Distance E-Side Distance Consistency Score 3 3 you デ格 NP 日本 で Pair 1: (Ds, Dt) = (1, 1) Positive Score (in Japan) [case “de”] 1 (insurance) will have to file 保険 文節内 [inside clause] 3 1 会社 に 対して 連用 NN insurance (to company) Score [renyou] 3 1 an claim NP 保険 文節内 [inside clause] (insurance) 1 2 insurance NN 請求 の ノ格 (claim) 3 [case “no”] 3 Pair 2: (Ds, Dt) = (1, 7) Negative Score with the office E-Side Distance 申し立て が ガ格 PP [case “ga”] (instance) 3 可能です よ J-Side Distance in Japan PP (you can) Toshiaki Nakazawa, Kun Yu, Sadao Kurohashi (Graduate School of Informatics, Kyoto University) {nakazawa, kunyu}@nlp.kuee.kyoto-u.ac.jp kuro@i.kyoto-u.ac.jp Core Steps of Alignment Flow of Our EBMT System • Searching Correspondence Candidates • Fine alignment is efficient in translation • Search candidates as much as possible using variety of linguistic information • Bilingual dictionaries • Transliteration (Katakana words, NEs) • ローズワイン → rosuwain ⇔ rose wine (similarity:0.78) • 新宿 → shinjuku ⇔ shinjuku (similarity:1.0) • Numeral normalization • 二百十六万 → 2,160,000 ← 2.16 million • Japanese flexible matching(Odani et. al. 2007) • Substring co-occurrence measure (Cromieres 2006) • Selecting Correspondence Candidates • More candidates derive more ambiguities and improper alignments • Necessity of robust alignment method which can align parallel sentences consistently by selecting the adequate candidates set Translation Examples Input 交差 (cross) came 交差点に入る時 私の信号は青でした。 点 で 、 (point) at me 突然 from the side (suddenly) 飛び出して 来た のです 。 at the intersection Structural Phrase AlignmentBased on Consistency Criteria (rush out) 交差 家 に (cross) to remove 点 に (house) 入る (point) when 入る (enter) 時 entering (enter) (when) 時 (when) 脱ぐ (put off) a house 私 の (my) 私 の (my) my 信号 は (signal) signature サイン (signal) Language Models 青 (blue) 信号 は でした 。 traffic (signal) (was) Output 青 The light (blue) My traffic light was green when entering the intersection. でした 。 was green (was) Selecting Correspondence Candidates Using Consistency Score and Dependency Type Ambiguities! 日本 で you (in Japan) Near! will have to file 保険 (insurance) insurance 会社 に 対して Far! Far! (to company) an claim 保険 (insurance) insurance 請求 の (claim) 申し立て が with the office Near! (instance) Improper alignments! in Japan 可能ですよ How to reflect the inconsistency? (you can) Dependency Type Distance Distribution of the distance of alignment pairs in hand-annotated data (Mainichi newspaper 40K sentence pairs) [Uchimoto04] “Near-Near” pair → Positive Score “Far-Far” pair → 0 “Near-Far” pair → Negative Score Consistency Score Function Experimental Result Quality of Other Language Pairs • 500 test sentences from Mainichi newspaper parallel corpus • Bilingual dictionary: KENKYUSYA J-E/J-E 500K entries • Evaluation criteria: Precision / Recall / F-measure • Character-base for Japanese, word-base for English (AER) Conclusion • Proposed a new phrase alignment method using consistency criteria. • Enough alignment accuracy compared to other language pairs. • We need to acquire the parameters automatically by machine learning. • We are planning to evolve the framework which revises the parse result. * Using 300K newspaper domain bi-sentences for training (There is a translation demos in exhibition corner by NICT which is using our system!)