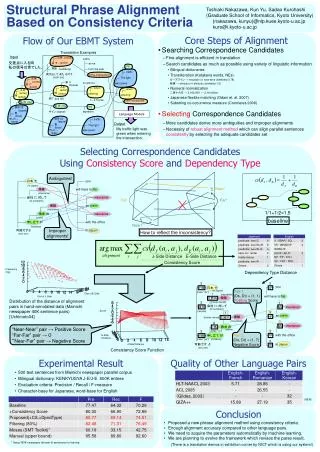
Download

1 / 26
260 likes | 388 Views
Phoneme Alignment based on Discriminative Learning. Shai Shalev-Shwartz The Hebrew University, Jerusalem Joint work with Joseph Keshet, Hebrew University Yoram Singer, Google Dan Chazan, IBM. The Alignment Problem. Have a test. Text:. /hh ae v ey tcl t eh s tcl t/.

E N D
Phoneme Alignment based on Discriminative Learning Shai Shalev-Shwartz The Hebrew University, Jerusalem Joint work with Joseph Keshet, Hebrew University Yoram Singer, Google Dan Chazan, IBM
The Alignment Problem Have a test Text: /hh ae v ey tcl t eh s tcl t/ Phonetic transcription: Waveform:
The Alignment Problem Setting acoustic representation start-time of phoneme pi in x alignment function phonetic representation /hh ae v ey tcl t eh s tcl t/
Acoustic Representation Short-time Fourier Transform
Comparing Alignments e.g.
-insensitive Cost -insensitivity region
A Discriminative Learning Approach Training set: Learning Algorithm Hypotheses class Alignment function:
Outline of Solution • Define the hypotheses class - constitutes the template of our alignment function: • Map each possible alignment into vectors in an abstract vector-space • Devise a projection in the vector-space which order alignments in accordance to their quality • Derive a simple online learning algorithm • Convert the Online Alg. to a Batch procedure with some formal guarantees
Feature “Primitives” for Alignment acoustic and phonetic representation feature primitive for alignment Assessing the quality of a suggested alignment suggested alignment
Feature Primitive I Cumulative spectral change across the boundaries
Feature Primitives I Cumulative spectral change across the boundaries
frame based phoneme classifier Learn a static frame-based phoneme classifier is the confidence that phoneme was uttered at frame (Dekel, Keshet, Singer, ‘04) Feature Primitives II Cumulative confidence in the phoneme sequence
- average length of phoneme - standard deviation of the length of phoneme Feature Primitive III Phoneme duration model
Feature Primitive IV Speaking-rate (“dynamics”) Spectogram at different rates of articulation (Pickett, 1980)
Feature Functions for Alignment Mapping all possible alignments into a vector space slightly incorrect alignment correct alignment grossly incorrect alignment
Main Solution Principle Find a linear projection that ranks alignments according to their quality slightly incorrect alignment correct alignment grossly incorrect alignment
Main Solution Principle (cont.) example of low confidence projection slightly incorrect alignment correct alignment grossly incorrect alignment
Main Solution Principle (cont.) example of incorrect projection slightly incorrect alignment correct alignment grossly incorrect alignment
Online Learning Online Learning Algorithm Hypotheses class Cumulative cost
Online Learning • For • Receive an instance • Predict • Receive true alignment and Pay cost • If • Set • Set • Update
Converting from Online to Batch • Run online algorithm on the training set and generate w1,…,wM • Small online error exists w 2 {w1,…,wM} whose generalization error is low (Cesa-bianchi et al.) • Choose w 2 {w1,…,wM} which minimizes the error on a fresh validation set
Algorithmic aspects • Running-time: • If the “inference”, , can be performed in polynomial time (e.g. dynamic programming), then the entire algorithm operates in polynomial time as well. • Worst case analysis for Online Learning: • For any competitor u, • Generalization error • Online-to-batch conversion guarantees that: low online error low generalization error
Experiments • TIMIT corpus • Phoneme representation: • 48 phonemes (Lee & Hon, 1989) • Acoustic Representation: • MFCC+∆+∆∆ (ETSI standard) • TIMIT training set: • 500 utterances for training a frame classifier • 3096 utterances for learning alignment function • 100 utterances used for validation
Alternative Approaches • Brugnara, Falavigna & Omologo, Automatic segmentation and labeling of speech based on HMM, 1993. • Hosom, Automatic phoneme alignment on acoustic-phonetic modeling, 2002. • Toledano, Gomez & Grande, Automatic Phoneme Alignment, 2003.
Results Brugnara, Falavigna and Omologo, “Automatic segmentation and labling of speech based on Hidden Markov Models”, Speech Comm., 12 (1993) 357-370.
Current and Future Work Discriminative learning methods for: • Whole phoneme sequence classification • 64% (ours) vs. 59% (HMM – IDIAP Torch3) • Results without normalization of silences etc. • Small vocabulary continuous speech recognition • Segmentation of utterances to speakers • Full online learning setting: real-time adaptation to Speaker/environment changes