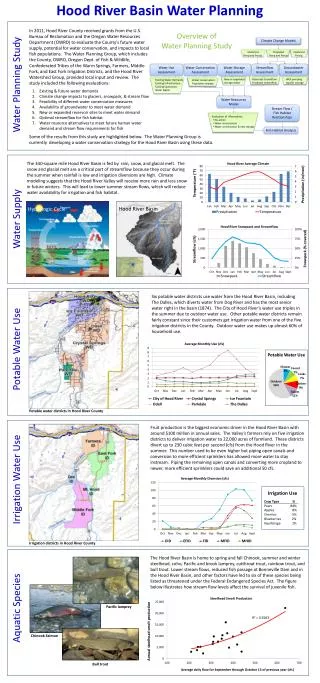
Download

1 / 83
830 likes | 846 Views
This study focuses on efficient water quality prediction for river basin management in line with the EU Water Framework Directive. It covers model identification, parameter estimation, validation, and prediction for sustainable water resource management. The research aims to enhance the accuracy and precision of predictions to streamline management actions in meeting water quality standards.

E N D
WATER QUALITY PREDICTION FOR RIVER BASIN MANAGEMENT Olli MalveFinnish Environment Institute Model identification, parameter estimation, validation, prediction BIO1: Aquatic Water Quality Modelling. Olli Malve, Finnish Environment Istitute
the EU Water Framework Directive (WFD) was adopted on 23 October 2000, with the following key aims: to expand the scope of water protection to all waters, surface waters and groundwater to achieve "a goodstatus" for all waters by a set deadline (2015) to implement water management based on river basins to introduce a "combined approach" laying down emission limitvalues and quality standards to involve citizens more closely to streamline the legislation to implement river basin management with reasonable costs. Cost efficient implementation of Water Framework Directive (WFD) in EUOPEAN UNION
A river basin is managed as a natural geographical and hydrological unit instead of according to administrative or political boundaries. Under the EU Water Framework Directive a management plan needs to be established for every river basin and updated every six years. River basin management plan is a detailed account of how the objectives set for a river basin (ecological status, quantitative status, chemical status and protected area objectives) are to be reached within the time scale required. The plan should include the characteristics of the river basin, a review of the impact of human activity on the status of the water in the basin, estimates of the effects of existing legislation, the remaining "gap" to be closed in order to meet these objectives; and a set of measures designed to fill that gap. Public participation is essential, i.e. all interested parties should be fully involved in the discussion of the cost-effectiveness of the various possible measures and in the preparation of the river basin management plan as a whole. Tight schedule of river basin plannning (by 2009 according to WFD).
What is the most demanding in the planning and decision making in river basin management? Predicting or “guessing” what is likely to happen if we perform a certain management action and planning and selecting actions which are likely to attain selected water quality standard with given probability.
The more accurate and precise predictions the more efficient management actions no over or under design of actions.
Decision making and learning from the experience of taken actions and accumulating observations Design of experiments and monitoring Water quality prediction Planning or approval of management actions Scientific learning Decision making Data collection Testing of the attainment of management objectives Implementation of management plans
Framework for scientific learning and decision making through prediction Statistical inference and causal reasoning Structural equations Differential equations Frequentist Bayesian Regression equations
Water quality prediction • How can we predict water quality? Theoretical understanding Observational data Causal structure Predictive model Water quality prediction Water body Experimental data Model parameters Not available in full scale
How water quality prediction is efficiently performed and used in planning and decision making in river basin management? MANAGEMENT: Selection of management objectives ? Planning and selection of management actions ? Water quality prediction ? Attainment of management goals
Connections between management, data collection and prediction
Basic elements of river basin management Sustainable use and management and good ecological status Primary objective: Attainment of water quality standards Secondary objective: Selection of feasible management actions Decision: Design of management actions Planning: Targeting of pollutant load reduction Prediction: Decision: Set up of water quality standards and acceptable probability of exceedance.
Problems is water quality prediction and river basin management Inefficient and biased river basin management Inefficient fitting, validation and prediction Biased target pollutant load estimates Large number of lakes, rivers. Update of river basin plans every six years Difficulty of coding, debugging, fitting and validation Imprecise parameter estimates Biased predictions and unrealistic error estimates Long simulation time Large number of unknown parameters Complexity of mechanistic models Small longitudinal sample size Large model errors Approximate error estimates
To overcome the difficulties we need efficient prediction methods Efficient, precise and unbiased update of river basin plans every six years Management objective: Easy of update Realistic error estimates Accuracy and precision Criterion of prediction: HIERARCHICAL model structure Developed Bayesian methods: Bayesian inference and MCMC methods Synthesis of mechanistic and statistical approaches Pooling of cross-sectional data Objectives of this study: Statistical models Mechanistic models Traditional methods:
Adaptive management procedure (two update cycles) Design of experiments and monitoring Water quality prediction Planning or approval of management actions 1. Update of predictions 2. Update of management plans Data collection Testing of the attainment of management objectives Implementation of management plans Decision making Scientific learning
Prediction methods for statistical decision making Different ways to causal reasoning and probability estimation • Bayesian inference and MCMC methods • Structural Equation Models (SEM) • Hierarchical linear model • Logistic model • Mass balance models • Differential equation models • Bayes nets and decision trees (Decision making tools)
Classification of prediction methods 1. Mechanistic / statistical modelling • causal structure - mechanistic model • predictive error - statistical model 2. Classical / Bayesian statistical analysis • Point estimate – classical • Full distribution - Bayes 3. Cross-Sectional / Longitudinal data • several lakes – cross-sectional • one lake – longitudinal 4. Hierarchical – non hierarchical model • lakes within lake types – hierarchical
Classification of prediction methods Modeling approach Mechanistic Statistical Bayesian Model structure Single level Hierarchical Multilevel Scientific discipline Hydrological. Chemical Biological. Orientation of data Longitudinal Cross-sectional Mixture
Causes of model uncertainty y x x x x x x x 1. Inaccurate measurements 2. Low number of measurements 3. Unfavorable timing or location of measurements 3. Stochastic variation 4. Model structure (unidentifiability of model parameters) 5. etc. x x
How accuracy of measurements, uncertainty of models and stochastic behavior of phenomenons has been taken into account in water resources research? Physics, hydrology, hydraulics: -determinism -differential equation models -sensitivity analysis - ”hard”-modelling Biology, limnology, hydrology: -statistical inference -regression analysis -”Soft”-modelling
How to integrate methodically ”hard”- ja ”soft”- modelling? -to combine saving graces: ”hard”: deterministic (explanatory) modelling of reaction kinetics, mass- and energy balances ”soft”: statistical inference and decision making with incomplete information -promote co-operation between environmental sciences
Bayesian statistical inference with Markov chain based Monte Carlo (MCMC) sampling Parameters of a deterministic differential equation model are taken as stochastic variables, which has certain statistical attributes (mean, standard deviation).
Using Bayesin inference with MCMC methods we can combine prior information with new measurements ---> posterior-distribution! New measurement Posterior-distribution A prior information Posterior can bee calculated with MCMC-methods
After posterior-distributions of parameters has been calculated confidence limits of predictions can calculated with Monte Carlo sampling y Credible intervals x x x x x x x x prediction x
Parameters of complicated environmental models are seldom identifiable (=parameters are correlated) Variance of parameters (uncertainty) is great! Posterior-distribution of a parameter Confidence limits of predictions are broad! Confidence limits of a prediction
BAYESIAN INFERENCE USING MCMC SAMPLING ALGORITHMS • Model error and parameter uncertainty can be estimated using Bayesian inference and MCMC sampling techniques • full statistical distribution of predictions • realistic design of margin of safety of management plans • no over or under design of management actions • cost effective implementation of management
Bayesian posterior predictive inference Target pollutant load estimate Model validation and update Posterior predictive distributions New observations Posterior simulation Posterior distributions of parameters Water quality standards MCMC sampling; Fitting of the model Mechanistic model of processes which produce data Statistical model of parameters and model error Prior distributions for model parameters Observations
Bayesian inference and MCMC-sampling methods M~model, d~data P(m)=Prior, information about parameters and model structure before observations P(d|m)=likelihood-function, “probability of data given the model and error distribution” P(m|d)=posterior, “probability of the model given data”. Information about parameters and model structure after observations.
Frequentist (Classical) inference Fitting of non linear model to data: Observation=model+error Fitting with least squares methods: θ parameter is a unknown constant, that is to be estimated. Its confidence interval, which is the measure of precision, is evaluated using linear approximation
What distinct Bayesian inference from Frequentist • Takes formally into a account all uncertainties in inference • Error-in-x-varibles can be taken into account • Inclusion of prior information • Efficient numerical sampling algorithms, MCMC • Predictive distributions • Posterior distribution includes all the information necessary for decision making
MCMC • Markov chain Monte Carlo –method is used for the sampling of posterior distribution of parameter vector θ if analytical solution is hard to find (all the complicated models). • Metroplis-Hastings and Gibbs sampler are mostly used.
Steps of Bayesian inference and MCMC sampling • Definition of model: physical/empirical, error distribution, parameters, control variables. • Observational or experimental design and data collection. • Definition of Prior distributions: uninformative, normal, uniform, … • Model fitting using MCMC-sampling methods • Post processing of MCMC-chain: density plots, credible intervals, predictive distributions • Testing of normality of model error and comparison of competing models
Metropolish-Hastings algorithm (i) Select initial value θ0 and proposal distribution q for parameter vector θ. (ii) Take a random sample θ’ from the proposal distribution q. (iii) Take a random sample from uniform random variable u [0,1] and accept the new random sample e.g. θi+1= θ’, if Otherwise θi+1= θi (iv) Go back to the step (ii) until enough samples are generated. Difficulty: proposal distribution must be close enough to the true posterior distribution. Usually it is normal distribution.
MH-algorithm for non linear model with normal error distribution Likelihood function is now MH-algorithm with non informative prior distribution p(θ)=1 and σ2: (i) Select θ0 and q. (ii)Sample θnew from proposal distribution q(θold, ) and calculate SSnew. Accept new sample if Ssnew < SSold or if (iii) Go back to the step (ii) until enough samples are generated.
MARKOV CHAIN MONTE CARLO (MCMC) –SAMPLING METHOD FOR PARAMETER ESTIMATION • Estimation of exact distributions for parameters and predictions • Parameter uncertainty (dark area) of predictions ja model errorσ(ligth dark area) [y=f(θ,x)+σ] can be distinquished. • Is applicable to also to dynamic and non linear oxygen and phytoplankton models.
Usage of predictive distributions in planning and decision making Predicted concentration of contaminant with given margin of safety = f(probability of exceedance) Concentration of contaminant Nitrogen load Predicted Chlorophyll a response surface 10% Chlorophyll a standard Water quality standard 25% Target nitrogen load 25 50% ~ mechanistic prediction 15 5 Phosphorus load Load of contaminant Target phosphorus load Margin of safety of target load Mechanistic prediction = 50 % probability of exceedance target load is large and it is very likely that water quality standard will not be attained. Decision maker does not acknowlegde uncertainty of a water quality prediction risk of non-attaiment of water quality standard is out of control. Use of artificial safety margins fail to attain the standard or unnecessary high cost.
Structural Equation Model (SEM) • Tests whether theoretical hypothesis about causal relationships fit to empirical data. • Correct causal structure correct parameter estimates better predictions
LAKE PYHÄJÄRVI in SÄKYLÄ; research model Planktiv – Planktivorous fish Z – zooplankton (Crustacea) A3- Cyanobacteria TP – total phosphorus TN – total nitrogen
Lakes in the lake monitoring network of Finnish Environment Institute; Targetting of nutrient reduction to attain chlorophyll a standard.
Table. Geomorphological typology of Finnish Lakes specified by Finnish Environment Institute (SA=Surface Area, D=Depth). Lake Name Characteristics Type I Large, non-humic lakes SA > 4,000 Ha, color < 30 II Large, humic lakes SA > 4,000 Ha, color > 30 III Medium and small, non-humic lakes SA: 50 - 4,000 Ha, color < 30 IV Medium Area, humic deep lakes SA:500-4,000 Ha, color: 30-90,D>3 m V Small, humic, deep lakes SA: 50-500 Ha, color:30-90, D>3 m VI Deep, very humic lakes Color > 90, D > 3 m VII Shallow, non-humic lakes Color < 30, D < 3 m VIII Shallow, humic lakes Color: 30-90, D < 3 m IX Shallow, very humic lakes Color > 90, D < 3 m
Objectives ofriver basin planning of Finnish Lakes Primary management objectives: High utility for water uses Good ecological status Attainment of chlorofyll a standard Secondary management objectives: Reduction of nutrient concentrations in lake Management actions: Reduction of nutrient load Chlorophyll a < 30 ug/l Water quality standard:
Computational prediction tools for Finnish lakes -Lake specific chlorophyll a -Target nutrient concentration -Parameter posterior distributions -Error variances Predictions: MCMC sampling Bayesian posterior predictive inference method: Prior parameter values and data HIERARCHICAL linear regression model: Statistical model: -Nutrient concentrations -Chlorophyll a standard -Acceptable probability of exceedance of chlorophyll a standard Decision variables:
Hierarchical Chlorophyll a data • A hierarchical data structure arises if individual lakes are sampled cross-sectionally but studied longitudinally. • e.g. lakes within lake types, or lake types within eco regions, or eco regions within continents (Malve and Qian 2006). Ecoregion Laketype 1 Laketype 2 Laketype 3 Laketype N … Cross-sectional direction Lake 1 Lake 2 Lake 3 … Longitudinal direction
Hirarchical linear chlorophyll a model DAG diagram β σ2 βi σ2i βij τ xijk yijk
Partial pooling in predicting chlorophyll a in a lake with few observations per lake Instead of predicting from lake or from a lake type hierarchical modelpartially pools (average weight by number of observations) information from those two populations. If interclass correlation is high ~1 pooling is complete eg. prediction is based on lake type population If interclass correlation is low ~0 no pooling eg. prediction is based on lake type If interclass correlation is [0,1] (partially pooling) weighted average of those two populations. If number of observations per lake is small partially pooled predictions are more precise and accurate than completely or not pooled predictions Interclass correlation ρ: Log(Chla) x
Most of the lakes are observed few times lake-type-specific Chla regression models may be inaccurate and imprecise on lake level Lake Onkijärvi – three observations
Hierarchical linear model • Partial pooling of information from different levels of hierarchy increases accuracy and precision of lake specific chlorophyll a predictions Lake Onkijärvi – three observations
Observational nutrient concentration ranges don't always cover targeted water quality criteria • the lake specific Chla regression model is not useful in water quality prediction. • Due to the partial pooling of information from lake-type-level a hierarchical chlorohyll a regression model can "extrapolate" outside lake specific observational range. • This is useful if a lake is observed within a eutrophic region and management target is some where in a mesotrophic region. Päijänne
The full statistical distribution of parameters and predictions can be estimated using Markov chain Monte Carlo sampling methods and Byesian Inference (Gelman et al. 2005). Freely available OpenBug-software (http://mathstat.helsinki.fi/openbugs/) is useful in estimation.
Logistic regression model • Phytoplankton bloom in a lake has binomial distribution: 1 ~ bloom and 0 ~ no bloom. • Probability of a bloom pi=Pr(yi=1) is predicted using logistic regression model: log(pi/(1-pi))=Xiβ