Download

1 / 22
220 likes | 235 Views
Explore parallelization techniques enabling shared memory process of decision tree construction for improved efficiency. Experimentation results and challenges discussed.

E N D
Shared Memory Parallelization of Decision Tree Construction Using a General Middleware Ruoming Jin Gagan Agrawal Department of Computer and Information Sciences Ohio State University
Motivation • Can the algorithms for a variety of mining tasks be parallelized using a common parallelization structure ? • If so, we can • Have a common set of parallelization techniques • Develop general runtime / middleware support • Parallelize starting from a high-level interface
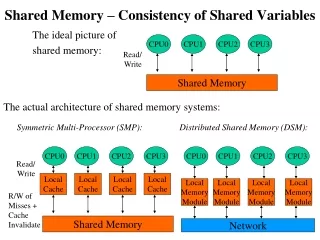
Context • Part of the FREERIDE (Framework for Rapid Implementation of Datamining Engines) system • Support parallelization on shared-nothing configurations • Support parallelization on shared memory configurations • Support processing of large datasets • Previously reported our work for • Distributed memory parallelization and processing of disk-resident datasets (SDM 01, IPDPS 01 workshop) • Shared memory parallelization applied to association mining and clustering (SDM 02, IPDPS 02 workshop, SIGMETRICS 02)
Decision Tree Construction • One of the key mining problems • Previous parallel algorithms have had a significantly different structure than parallel algorithms for association mining, clustering, etc. • Frequently require sorting of data (SPRINT, SLIQ etc.) • Require attributes to be written back • Difficult to obtain very high speedups • Can we perform shared memory parallelization of decision tree construction using the same techniques that were used for association mining and clustering ?
Outline • Previous work on shared memory parallelization • Observation from major mining algorithms • Parallelization Techniques • Decision tree construction problem and algorithms • RainForest Based Approach • Parallelization methods • Experimental Results
Common Processing Structure • Structure of Common Data Mining Algorithms {* Outer Sequential Loop *} While () { { * Reduction Loop* } Foreach (element e) { (i,val) = process(e); Reduc(i) = Reduc(i) op val; } } • Applies to major association mining, clustering and decision tree construction algorithms • How to parallelize it on a shared memory machine?
Challenges in Parallelization • Statically partitioning the reduction object to avoid race conditions is generally impossible. • Runtime preprocessing or scheduling also cannot be applied • Can’t tell what you need to update w/o processing the element • The size of reduction object means significant memory overheads for replication • Locking and synchronization costs could be significant because of the fine-grained updates to the reduction object.
Parallelization Techniques • Full Replication: create a copy of the reduction object for each thread • Full Locking: associate a lock with each element • Optimized Full Locking: put the element and corresponding lock on the same cache block • Fixed Locking: use a fixed number of locks • Cache Sensitive Locking: one lock for all elements in a cache block
Memory Layout for Various Locking Schemes Fixed Locking Full Locking Optimized Full Locking Cache-Sensitive Locking Lock Reduction Element
Trade-offs between Techniques • Memory requirements: high memory requirements can cause memory thrashing • Contention: if the number of reduction elements is small, contention for locks can be a significant factor • Coherence cache misses and false sharing: more likely with a small number of reduction elements
Summary of Results on Association Mining and Clustering • Applied techniques on apriori association mining and k-means clustering • Each of full replication, optimized full locking, and cache-sensitive locking can outperform each other, depending upon the size of the reduction object • Near-linear speedups obtained in all our experiments
Decision Tree Construction Problem • Input: a set of training records, each with several attributes • One attribute is special, called the class label, others are predictor attributes • The goal is to construct a prediction model, which predicts the class model for a new record, using values of its predictor attributes • A tree is constructed in a top-down fashion
Existing Algorithms • Initial algorithms: required training records to fit in memory • SLIQ: scalable, but • Requires sorting of numerical attributes • Separation of attribute lists • A data-structure called class list to be maintained in main memory (size proportional to the number of training records) • SPRINT: scalable and parallelizable, but • Requires sorting of numerical attributes • Separation of attribute lists • Partitioning of attribute lists while splitting a node
RainForest Based Decision Tree Construction • A general approach to scaling decision tree construction • Key idea: AVC-set (Attribute Value, Classlabel) • Sufficient information for deciding on split condition • For an attribute and node, size is proportional to the number of distinct values and class labels • Easily constructed by taking one pass on data • A number of different algorithms: RF-read, RF-Write, RF-hybrid • RF-read has a structure that fits in very well with canonical loop presented earlier
RF-read Algorithm • High-level structure of the algorithm • While the stop condition is not satisfied • read the data • build the AVC-group for nodes • choose the splitting attributes to split nodes • select a new set of node to process as long as the main memory could hold it • Never need to write-back any data to disks • May require multiple passes to process one levels of the tree
Overall Parallelization Approach • Training records can be processed independently by processors • AVC-sets of nodes are reduction objects : race conditions can arise in updating the values • Use the different parallelization techniques we have for avoiding race conditions • Higher memory requirements can mean more passes to process one level of the tree
Parallelization Strategies • Pure approach: only apply one of full replication, optimized full locking and cache-sensitive locking • Vertical approach: use replication at top levels, locking at lower • Horizontal: use replication for attributes with a small number of distinct values, locking otherwise • Mixed approach: combine the above two
Experimental Setup • SMP Machine • SunFire 6800 • 24 750 MHz processors (only up to 8 for our experiments) • 64 KB L1 cache, 8 MG L2 cache, 24 GB memory • Dataset • 1.3 GB dataset with 32 million records • Synthetic data, using a tool available from IBM almaden • 9 attributes, 3 categorical, 6 numerical • Used functions 1 and 7 (1 in paper)
Results Performance of pure versions, 1.3GB dataset with 32 million records in the training set, function 7, the depth of decision tree = 16.
Results Combining full replication and optimized full locking
Results Combining full replication and cache-sensitive locking
Summary • A set of common techniques can be used for shared memory parallelization of different mining algorithms • Combination of parallelization techniques gives the best performance for decision tree construction • Best speedup of 5.9 on 8 processors – comparable with other results on shared memory and distributed memory parallelization