Download

1 / 25
250 likes | 376 Views
Fast Firewall Implementation for Software and Hardware-based Routers. Lili Qiu, Microsoft Research George Varghese, UCSD Subhash Suri, UCSB 9 th International Conference on Network Protocols Riverside, CA, November 2001. Outline. Motivation for packet classification Performance metrics

E N D
Fast Firewall Implementation for Software and Hardware-based Routers Lili Qiu, Microsoft Research George Varghese, UCSD Subhash Suri, UCSB 9th International Conference on Network Protocols Riverside, CA, November 2001
Outline • Motivation for packet classification • Performance metrics • Related work • Our approaches • Performance results • Summary
Motivation • Traditionally, routers forward packets based on the destination field only • Firewall and diff-serv require packet classification • forward packets based on multiple fields in the packet header • e.g. source IP address, destination IP address, source port, destination port, protocol, type of service (ToS) …
Problem Specification • Given a set of filters (or rules), find the least cost matching filter for each incoming packet • Each filter specifies • Some criterion on K fields • Associated directive • Cost • Example:Rule 1: 24.128.0.0/16 4.0.0.0/8 … udp denyRule 2: 64.248.128.0/20 8.16.192.0/24 … tcp permit…Rule N: 24.128.0.0/16 4.16.128.0/20 … any permit Incoming packet: [24.128.34.8, 4.16.128.3, udp] Answer: rule 1
Performance Metrics • Classification speed • Wire rate lookup for minimum size (40 byte) packets at OC192 (10 Gbps) speeds. • Memory usage • Should use memory linear in the number of rules • Update time • Slow updates are acceptable • Impact on search speed should be minimal
Related Work • Given N rules in K dimensions, the worst-case bounds • O(log N) search time, O(N(K-1)) memory • O(N) memory, O((log N)(K-1)) search time • Tree based • Grid-of-tries (Srinivasan et.al. Sigcomm’98) • Fat Inverted Segment Tree (Feldman et.al. Infocom’00) • Cross-producting (Srinivasan et.al. Sigcomm’98) • Bit vector scheme • Lucent bit vector (Lakshman et.al. Sigcomm’98) • Aggregated bit vector scheme (Baboescu et.al. Sigcomm’01) • RFC (Pankaj et.al. Sigcomm’99) • Tuple Space Search (Srinivasan et.al. Sigcomm’99)
Backtracking Search • A trie is a binary branching tree, with each branch labeled 0 or 1 • The prefix associated with a node is the concatenation of all the bits from the root to the node A 1 0 B D 0 C 0 F1 E F2
Backtracking Search (Cont.) A • Extend to multiple dimensions • Standard backtracking • Depth-first traversal of the tree visiting all the nodes satisfying the given constraints • Example: Search for [00*,0*,0*]Result: F8 • Reason for backtrack • 00* matches *, 0*, 00* 1 0 B 0 0 C 0 0 D H 1 0 E 0 I J 0 0 1 0 F 1 F8 G F3 1 K 1 0 F6 F4 F2 F5 F7 F1
Set Pruning Tries • Multiplane trie • Fully specify all search paths so that no backtracking is necessary • Performance • O(logN) search time • O(N(k-1)) storage
Set Pruning Tries: Conversion • Converting a backtracking trie to a set pruning trie is essentially replacing a general filter with more specific filters
Set Pruning Tries: Example 1 1 0 0 0 1 0 1 1 0 B C D E 1 1 F2 0 0 F2 F2 F2 F2 F A F3 Min(F1,F2) Min(F2,F3) F1 Backtracking Trie Set Pruning Trie Replace [*,*,*] with [0*,0*,*], [0*,0*,0*], [0*,1*,*], [1**,0*,*],[1*,1*,*], and [1*,1*,1*].
Performance Evaluation • 5 real databases from various sites • Five dimensions • src IP, dest IP, src port, dest port, protocol • Performance metrics • Total storage • Total number of nodes in the multiplane trie • Worst-case lookup time • Total number of memory accesses in the worst-case assuming 1 bit at a time trie traversal
Performance Results Backtracking has small storage and affordable lookup time.
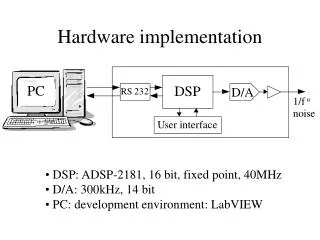
Major Optimizations • Trie compression algorithm • Pipelining the search • Selective pushing • Using minimal hardware
Trie Compression Algorithm 0 • If a path AB satisfies the Compressible Property: • All nodes on its left point to the same place L • All nodes on its right point to the same place R then we compress the entire branches by 3 edges • Center edge with value (AB) pointing to B • Left edge with value < (AB) pointing to L • Right edge with value > (AB) pointing to R • Advantages of compression: save time & storage 0 branch >01010 0 branch < 01010 0 1 0 branch = 01010 F1 1 0 0 1 F3 F1 1 F1 F2 F3 0 F2 F3
Performance Evaluation of Compression Compression reduces the lookup time by a factor of 2 - 5
Pipelining Backtracking • Use pipeline to speed up backtracking • Issues • The amount of register memory passed between pipelining stages need to be small • The amount of main memory need to be small Pipeline Stage 1 Pipeline Stage 2 Pipeline Stage m
Pipelining Backtracking:Limit the amount of register A • Standard backtracking requires O(KW) state for K-dimensional filters, with each dimension W-bit long • Our approach • Visit more general filters first, and more specific filters later • Example • Search for [00*,0*,0*]A-B-H-J-K-C-D-E-F-GResult: F8 • Performance • K+1 32-bit registers 1 0 B 0 0 C 0 0 D H 1 0 E 0 I J 0 0 1 0 F 1 F8 G F3 1 K 1 0 F6 F4 F2 F5 F7 F1
Pipelining Backtracking: Limit the amount of memory • Simple approach • Store an entire backtracking search trie at every pipelining stage • Storage increases proportionally with the number of pipelining stages • Our approach • Have pipeline stage i store only the trie nodes that will be visited in the stage i
Storage Requirement for Pipeline Storage increases moderately with the number of pipelining stages (i.e. slope < 1).
Trading Storage for Time • Smoothly tradeoff storage for time • Observations • Set pruning tries eliminate all backtracking by pushing down all filters intensive storage • Eliminate backtracking for filters with large backtracking time • Selective push • Push down the filters with large backtracking time • Iterate until the worst-case backtracking time satisfies our requirement O((logN)(k-1)) Time (e.g. Backtrack) O(N(k-1)) Space (e.g. Set Pruning)
Example of Selective Pushing Goal: worst-case memory accesses 11 • The filter [0*, 0*, 000*] has 12 memory accesses. • Push the filter down reduce lookup time • Now the search cost of the filter [0*,0*,001*] becomes 12 memory accesses. So we need to push it down. Done! 0 0 0 0 0 0 0 0 0 0 0 0 F3 0 0 0 0 0 F3 F3 0 0 1 1 1 1 0 0 0 0 0 0 0 0 F2 F2 F2 F2 F1 F1 F1 F1 F1
Performance of Selective Push Uncompressed Trie Compressed Trie Lookup time is reduced with moderate increase in storage until we reach the knee of the curve.
Summary • Experimentally show simple trie based schemes perform much better than the worst case figure • Propose optimizations • Trie compression • Pipelining the search • Selective push