Download

1 / 17
170 likes | 374 Views
DEDUPLICATION IN YAFFS. KARTHIK NARAYAN PAVITHRA SESHADRIVIJAYAKRISHNAN. Data Deduplication Intelligent Compression Addresses storage space requirements Solid State Devices A cutting edge storage technology Addresses I/O performance requirements

E N D
DEDUPLICATION IN YAFFS KARTHIK NARAYAN PAVITHRA SESHADRIVIJAYAKRISHNAN
Data Deduplication • Intelligent Compression • Addresses storage space requirements Solid State Devices • A cutting edge storage technology • Addresses I/O performance requirements Data Deduplication + SSD => Perfect match ?
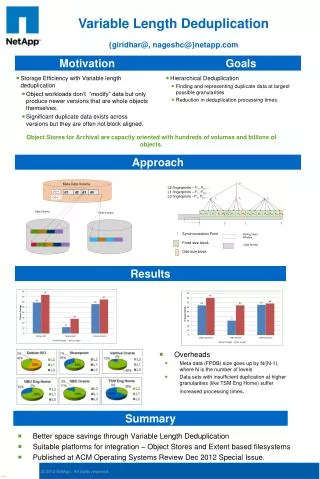
Abundant storage requirements in storage systems due to aplenty of redundant data • Increased storage cost and performance degradations • SSDs can be more cost effective than managing a group of mechanical hard drives
What have we done? • Deduplication in YAFFS2 (Yet Another Flash File System)- NAND flash file system • Deduplication addresses the problems caused by redundant data and it has been implemented using Content based fingerprinting • Properties of flash are harnessed to reduce the overheads and implementation complexity • We show that the write time for duplicate data and storage space has been greatly reduced
SSD ENTERS THE PICTURE • High performance storage • SSDs use microchips which retain data in non-volatile memory chips • As of 2010, most SSDs use NAND-based flash memory, which retains memory even without power • It has been the single biggest change to drive technology in recent years, with the storage medium showing up in data centers,laptops and in memory cards in mobile devices
Some properties of Flash/SSD • Faster access time than a disk, because the data can be randomly accessed and does not rely on a read/write interface head synchronizing with a rotating disk • SSD also provides greater physical resilience to physical vibration, shock and extreme temperature fluctuations because of the absence of moving parts
DESIGN • Source deduplication- Takes place within a file system • Content based finger printing • Files are divided into chunks • Fingerprinting for the chunks is carried out before every write operation • Multiple redundant copies are indirected to the same device location • Read performance is not affected
A note on choice of hash function • The hash functions used include standards such as SHA-1, SHA-256 and others. These provide a far lower probability of data loss than the risk of an undetected/uncorrected hardware error in most cases • Some cite the computational resource intensity of the process as a drawback of data deduplication • To improve performance, We can utilize weak hashes. Weak hashes are much faster to calculate but there is a greater risk of a hash collision. • Systems that utilize weak hashes will subsequently calculate a strong hash or compare the actual data and will use it as the determining factor to whether it is actually the same data or not. • We can afford to compare the actual data as a read is fast enough in SSD than wasting precious CPU power
DESIGN contd.. • The chunk fingerprints and the corresponding chunk IDs are maintained as in memory structures • A back store typically has large number of chunks • This led to the idea of storing Hashes on the device and maintaining a cache of it in memory • A combination of LFU(Least frequently Used) and LRU(Least Recently Used) cache replacement policies should yield good results. We have implemented LFU.
Implementation • We chose YAFFS2 to implement deduplication. • Popular commercially used robust file system for NAND • Our testing environment is an android emulator which runs the virtual CPU called Goldfish • Goldfish executes ARM926T instructions and has hooks for input and output -- such as reading key presses from or displaying video output in the emulator
Implementation • Primarily, we tweaked the function yaffs_WriteChunkDataToObject that writes chunk data to the NAND During every chunk write : • Determine the fingerprint for the chunk • Check if a fingerprint exists in the chunk cache • If it is not present,fetch the fingerprint & corresponding chunk ids from device
Implementation Contd... If a chunk id is present corresponding to the hash, remove Least frequently used entry from chunk cache and replace it with the entry obtained from device Update meta-data for this chunk to point to the existing chunk ID corresponding to its fingerprint value If no chunk id is present for the hash, write the chunk to NAND and update the hash entry
CONCLUSION • Decade’s most important data storage technology • Deduplication on SSDs would be at the fore front of back up solutions in future • These two technologies together can control storage costs without sacrificing reliability or performance • De-dupe technology continues to spread, and as SSD costs drop, those benefits will become even more apparent.