Download
1 / 1
• 30 likes • 240 Views
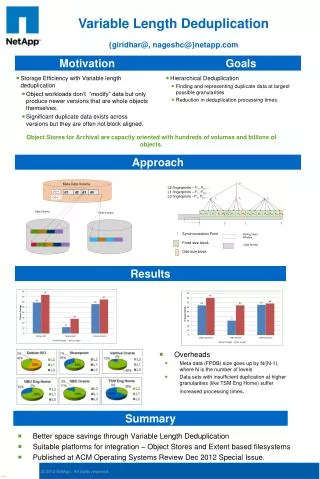
Variable Length Deduplication. { giridhar @, nageshc @}netapp.com. Motivation Goals. Hierarchical Deduplication Finding and representing duplicate data at largest possible granularities Reduction in deduplication processing times.

E N D
Variable Length Deduplication {giridhar@, nageshc@}netapp.com Motivation Goals • Hierarchical Deduplication • Finding and representing duplicate data at largest possible granularities • Reduction in deduplication processing times. • Storage Efficiency with Variable length deduplication • Object workloads don’t “modify” data but only produce newer versions that are whole objects themselves. • Significant duplicate data exists across versions but they are often not block aligned. Object Stores for Archival are capacity oriented with hundreds of volumes and billions of objects. Approach Meta Data Volume f21 L2 fingerprints – f21, f22,… L1 fingerprints – f11, f112,… L0 fingerprints - f01, f02,… OID 4 OID 3 f11 f12 f13 Data Volume Data Volume f01 f02 f03 f04 f05 f06 f07 f08 f09 f010 f011 f012 f013 f014 f015 f016 Synchronization Point Fixed size block Odd size block Rolling Hash Window Data Stream Results • Overheads • Meta data (FPDB) size goes up by N/(N-1), where N is the number of levels • Data sets with insufficient duplication at higher granularities (like TSM Eng Home) suffer increased processing times. Summary • Better space savings through Variable Length Deduplication • Suitable platforms for integration – Object Stores and Extent based filesystems • Published at ACM Operating Systems Review Dec 2012 Special Issue. v. 1.0